データサイエンティストの転職サイトを見ると年収 600万 ~ 1,200万円ぐらいだ。
書かれている内容を大体まとめると次のようなスキルが必要だと分かる。
【必須】
- 統計学、機械学習に関する知識・実務経験
- データ分析の実務経験(Python/R/C++などの経験)
- PythonやR等のデータ解析プログラミングに関する経験・知識
- ビジネスにおける定量的な効果検証・改善施策立案の経験
- C++,Java,Pythonなどで実際のプロダクトやビジネス上の課題に対して自然言語処理を応用した経験(3年以上)
- Cabocha,KNPなどの言語解析ツールの利用経験
- Word2VecやNERなどの機械学習を応用したツールの利用経験
- 英語メール,英語論文読解に抵抗のない方
【歓迎】
- 開発プロジェクトマネジメントの経験
- 国際論文(NIPS、 ICML、 KDD等)採録実績
- 社外との要件定義など技術的打ち合わせ経験
- 機械学習モデルの構築、改善の実務経験
- 大規模なデータやサービスの分析の実務経験
- データベース、SQLに関する実務経験
- BtoBプロジェクトに関する経験
- 機械学習 (LSTM,SVM,LDAなど)に対する経験
Pythonで機械学習フレームワークが利用できて、データ分析と統計学に精通していれば転職可能そうです。
前回データの可視化により、データ傾向を理解した上で、もう少しデータ加工やKerasを触って理解を深めてみる。
- 【2回目】Kaggle の Titanic Prediction Competition で機械学習を習得(Jupyter Notebook編)
- 【1回目】Kaggle の Titanic Prediction Competition で機械学習を習得(Keras導入編)
- 【6回目】Kerasを使った株の利益を計算(ディープラーニング)
- 【5回目】Kerasを使ったMatplotlibのグラフ整形と日本語表示(ディープラーニング)
- 【4回目】Kerasのモデル保存・利用(ディープラーニング)
- 【3回目】Kerasを使って活性関数・目的関数・最適化手法をまとめる
- 【2回目】KerasのFunctional API Modelの構造を理解する
- 【1回目】はじめてのKerasを使った株価予測(ディープラーニング)
Jupyter notebookでscroll boxの高さを変える
ブラウザでみれるからHTMLなので次のように変更できるっぽい。
|
1 2 3 |
from IPython.core.display import display, HTML display(HTML("<style>.container { width:90% !important; }</style>")) display(HTML("<style>.scroll_box { height:30em !important; }</style>")) |
けど、縦軸は伸びなかった・・・。
データの概略をつかむ
前回は紹介しなかったが、このような見える化もできます。
ヒストグラムで概略をつかむ
|
1 2 3 4 5 6 7 8 9 10 |
import numpy as np import matplotlib.pyplot as plt import pandas as pd df_train = pd.read_csv("train.csv").replace(["male", "female"], [0,1]) df_train["Embarked"] = df_train["Embarked"].dropna().map({"S": 0, "C": 1, "Q": 2}).astype(int) # ヒストグラムでデータの概略をつかむ df_train.hist(bins=50, figsize=(20,15)) # creates a figure with 10 (width) x 5 (height) inches plt.rcParams['figure.figsize'] = [10, 5] plt.show() |
Jupyter notebookで画像を表示するためにrcParamsを使ってサイズを変更しています。
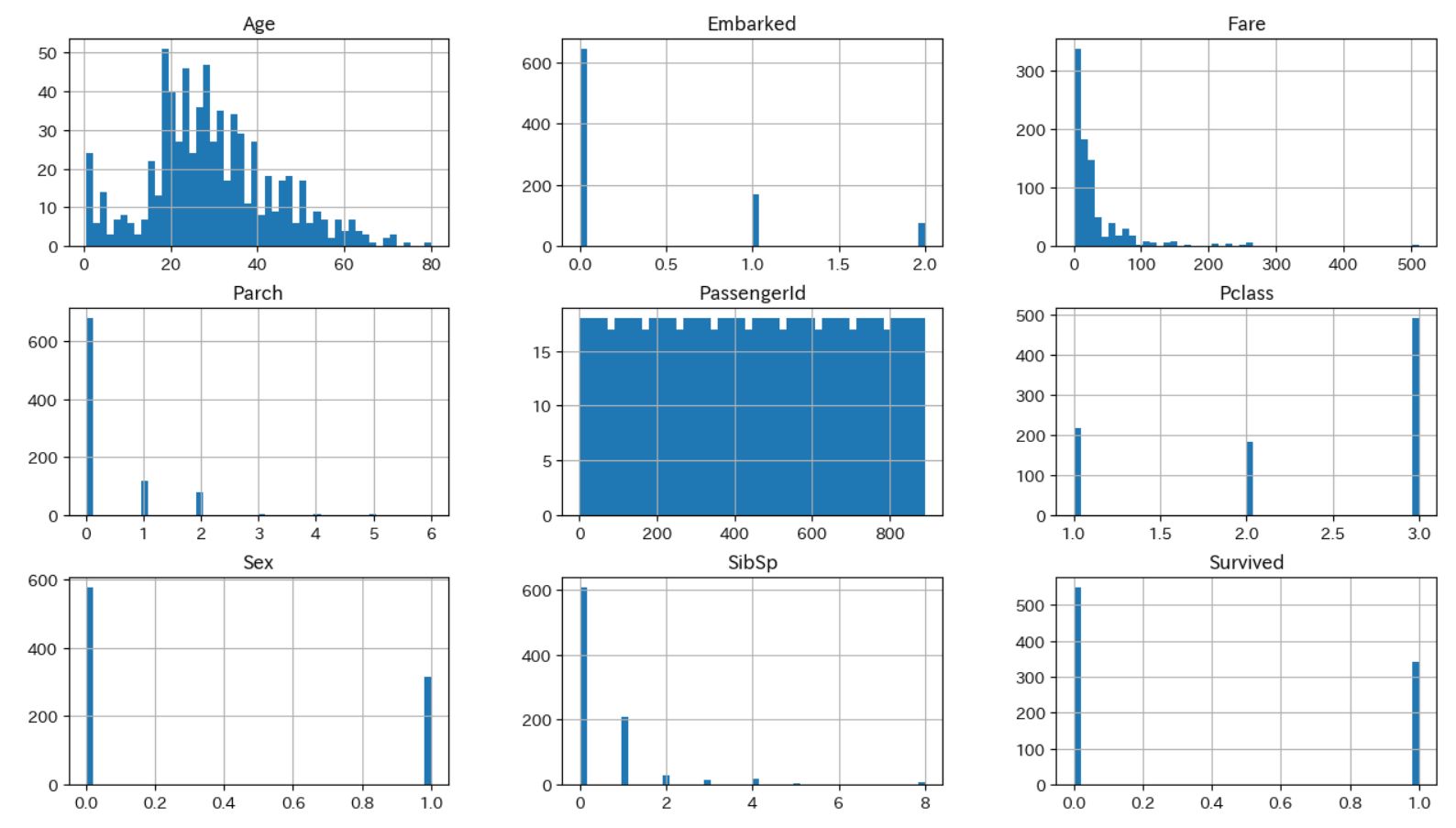
ヒストグラムにするとかなりみやすいですね。
Ageは20~30代が多く、Survivedは生存できなかったほうが割合としては多いなど、傾向が一目でわかります。
相関係数で概略をつかむ
量的データどうしの相関関係をみるときには、ピアソンの積率相関係数を用います。
pandas.DataFrameオブジェクトからcorr()メソッドを呼ぶと、各列の間の相関係数が算出されます。
|
1 2 |
corr_matrix = df_train.corr() corr_matrix["Survived"].sort_values(ascending=False) |
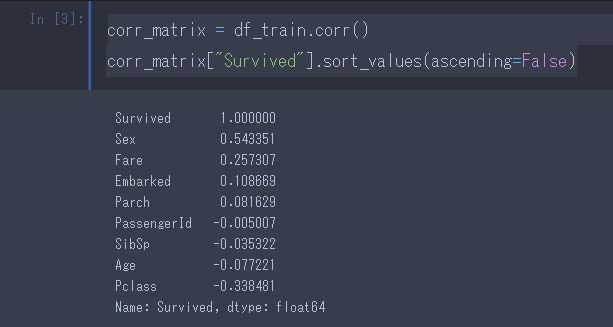
ここで「相関係数」はすべてデフォルトでは「ピアソンの積立相関係数」となっています。
| 相関係数の絶対値 | 強さ |
|---|---|
| 0.0~0.2 | 相関無し |
| 0.2~0.4 | やや相関有り |
| 0.4~0.7 | 強い相関がある |
| 0.7~1.0 | 非常に強い相関がある |
Sex(性別)、Fare(金額)、Pclass(階級)にも相関があります。
相関係数は、1 ~ -1 の値をとり、値が大きいほど強い正の相関があり、0に近いと相関はなし
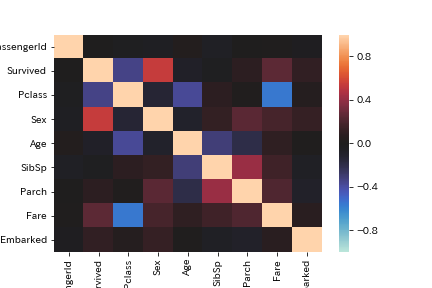
また、Pythonのビジュアライゼーションライブラリseabornを使うと、corr()で得られるようなpandas.DataFrameをヒートマップとして簡単に可視化できます。
|
1 2 3 |
import seaborn as sns sns.heatmap(corr_matrix, vmax=1, vmin=-1, center=0) plt.savefig('seaborn_heatmap_corr_example.png') |
KerasでFunctional APIを利用
Kerasには2通りのModelの書き方があります。
「Sequential Model」と「Functional API Model」です。
「Sequential Model」は入力と出力が必ず1つずつのネットワーク構成しか定義することができません。
・・・ネット上には、そう書いてありますが、同じネットワークを「Sequential Model」と「Functional API Model」で書いて比較しているサイトが全くありません。
前回の「Sequential Model」を「Functional API Model」で書いてみます。
Sequentialで書いた場合
|
1 2 3 4 5 6 |
model = Sequential() model.add(Dense(20, input_shape=(input_dim,))) model.add(Activation("relu")) model.add(Dense(1, input_dim=20)) model.add(Activation("sigmoid")) plot_model(model, to_file='model.png', show_shapes=True) |
Functional APIで書いた場合
|
1 2 3 4 5 6 7 |
inputs = Input(shape=(input_dim,)) layer = Dense(20)(inputs) mid1 = Activation('relu')(layer) mid2 = Dense(1)(mid1) output = Activation('sigmoid')(mid2) model = Model(inputs=inputs, outputs=output) plot_model(model, to_file='model.png', show_shapes=True) |
結果
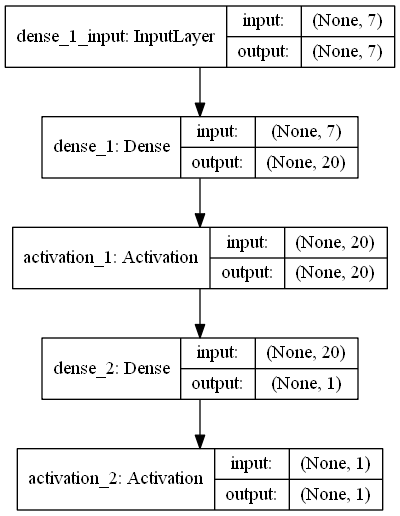
難しいことは何もありませんでした。
ただ、、下記のように書くと違うのかな・・・・。
|
1 2 3 4 5 6 7 8 9 |
# 学習ネットワーク構築(Functional API ver) def build_model(input_dim): inputs = Input(shape=(input_dim,)) layer = Dense(20, activation='relu')(inputs) dense = Dense(1, activation='sigmoid')(layer) model = Model(inputs=inputs, outputs=dense) model.summary() plot_model(model, to_file='model3.png', show_shapes=True) return model |
結果
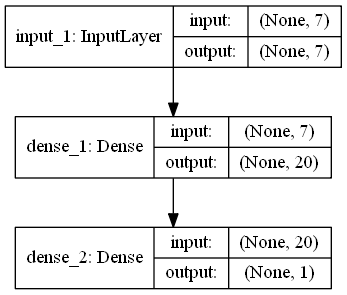
結果は確かに違うけど・・・・、学習ネットワークとして本当に違うのか・・・な。
ソースコード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 |
import time import numpy as np import pandas as pd from keras.layers import Input, Dense, Activation from keras.models import Model from keras.models import Sequential from sklearn.preprocessing import StandardScaler import tensorflow as tf from keras.utils import plot_model # Data Cleansing def normalize_data(data): data = data.drop(["PassengerId", "Name", "Ticket", "Cabin"], axis=1) # Changing the name of Column (PClass) to (TicketClass) for easy understanding data = data.rename(columns = {"Pclass":"TicketClass"}) # Complement the missing values of "Age" column with average of "Age" data["Age"] = data["Age"].fillna(data["Age"].mean()) # 全てのAgeを平均 0 標準偏差 1になるように標準化 scaler = StandardScaler() data["Age"] = scaler.fit_transform(data["Age"].values.reshape(-1, 1)) # Complement the missing values of "Fare" column with average of "Fare" data["Fare"] = data["Fare"].fillna(data["Fare"].mean()) # Convert "Sex" to be a dummy variable (female = 0, Male = 1) data["Sex"] = data["Sex"].replace(["male", "female"], [0, 1]) # Convert "Embarked" to be a dummy variable (S = 0,C = 1, Q = 2) data["Embarked"] = data["Embarked"].fillna("S") data["Embarked"] = data["Embarked"].replace(["C", "S", "Q"], [0, 1, 2]) # 他の書き方例 # data["Embarked"] = data["Embarked"].dropna().map({"S": 0, "C": 1, "Q": 2}).astype(int) # data["Embarked"][data["Embarked"] == "S"] = 0 return data # 学習用データ x_data、検証用結果 y_data の割り当て def build_train_test_data(data, rate=0.8): # 答えの削除 y_data = data["Survived"] x_data = data.drop(["Survived"], axis=1) # 全データのうち、80% を学習用データ、20% を検証用データに割り当て train_size = int(len(x_data) * 0.8) # 80% を学習用データ x_train = x_data[:train_size] # Inputs y_train = y_data[:train_size] # Output (Survived) # 20% // 2 小数点以下は切り捨て valid_test_size = (len(x_data) - train_size) // 2 # 10% を検証用テストデータ x_test = x_data[valid_test_size + train_size:] y_test = y_data[valid_test_size + train_size:] # 作成した行列出力 print("x_train:{}".format(x_train.shape)) print("y_train:{}".format(y_train.shape)) print("x_test:{}".format(x_test.shape)) print("y_test:{}".format(y_test.shape)) return x_train, y_train, x_test, y_test # 学習ネットワーク構築(Sequential ver) def build_model(input_dim): model = Sequential() model.add(Dense(20, input_shape=(input_dim,))) # model.add(Dense(20, input_dim=input_dim)) model.add(Activation("relu")) model.add(Dense(1, input_dim=20)) model.add(Activation("sigmoid")) model.summary() plot_model(model, to_file='model2.png', show_shapes=True) return model # 学習ネットワーク構築(Functional API ver) def build_model2(input_dim): inputs = Input(shape=(input_dim,)) layer = Dense(20)(inputs) mid1 = Activation('relu')(layer) mid2 = Dense(1)(mid1) output = Activation('sigmoid')(mid2) model = Model(inputs=inputs, outputs=output) model.summary() plot_model(model, to_file='model.png', show_shapes=True) return model # 学習ネットワーク構築(Functional API ver) def build_model(input_dim): inputs = Input(shape=(input_dim,)) layer = Dense(20, activation='relu')(inputs) dense = Dense(1, activation='sigmoid')(layer) model = Model(inputs=inputs, outputs=dense) model.summary() plot_model(model, to_file='model3.png', show_shapes=True) return model def main(): # CSVを読み込む df_train = pd.read_csv("train.csv") normalized_data = normalize_data(df_train) x_train, y_train, x_test, y_test = build_train_test_data(normalized_data, 0.8) start = time.time() # x_train.shape[1] = 7 model = build_model(x_train.shape[1]) model.compile(loss="binary_crossentropy", optimizer="sgd", metrics=["accuracy"]) # エポックは 120、バッチサイズは 16 model.fit(x_train, y_train, nb_epoch=120, batch_size=16) print(str(time.time() - start)) # 結果出力 [loss, accuracy] = model.evaluate(x_test, y_test) print("loss:{0} -- accuracy:{1}".format(loss, accuracy)) # テスト値を読み込み df_out = pd.read_csv("test.csv") predictions = model.predict(normalize_data(df_out)) df_out["Survived"] = np.round(predictions).astype(np.int) # CSVに出力する df_out[["PassengerId","Survived"]].to_csv("submission.csv",index=False) main() |