
将来が不安です・・・。
先週、上司(センター長、部門長、部長、課長)より、
今後どうするんだ?この仕事じゃ何年も生きていけないぞ!!
と言われています。
自分でもそう思います・・・・。
でも、今の仕事を目的でアメリカから帰任させたの貴方達ですよ・・・。
2年前に部門内MVPまで受賞したのに・・・
目的達成したら、不要になりポイですよ。
サラリーマンとは理不尽さを学ぶ職業です。
孔子曰く、「四十にして惑わず」。
もう40になるというのに、今の自分は人生で一番迷っている。
まるで生まれたばかりのバンビが、弱々しく親鹿を探しているように・・・・。

【引用】LINEスタンプ「生まれたての子鹿」
社内コンサルのような業務に携わっていたので、口だけ達者で技術力が完全に落ちてしまいました。
社内でFA宣言したら、
応募数が「0件」
という制度始まって以来の汚名を残し人事が慌てる騒動があったぐらいなので、本当に私に需要が無いです。
売り手市場なんて優秀な人にしか関係ないね。糞。
完全にオッサンじゃね?どうするの?俺?

で、この数年で得た能力は?
業務上はコンサル的な一面とデータアナリスト的な一面がありました。
論理的思考・・ぐらいかな・・、身についたのは。
ただ、武器といっても40のオッサンなので、
ひのきのぼうを手に入れた

ぐらいの価値しか無い。
そもそも口だけの評論家なので、何も役には立ちません。
ちなみに、ここ5年間で得た身体能力は、
くさいいき
だけです・・・・・。
僕、生きてて良いですか・・・?
Kaggle(カグル)の練習問題をやってみる
そんな中、「Kaggle初心者向け入門編!アカウント開設からタイタニック提出まで」という記事を見つけました。
「Kaggle(カグル)」とは、2010年にアメリカで設立された世界中の企業や研究者がデータを投稿する世界最大のデータ分析のCompetition(コンペ)です。
名前だけは知ってます。
AtCoder とか、TopCoderとか、Codeforcesの機械学習版のようなもの。というザックリした理解ですが。
初心者にはKaggleの中で特に有名な課題として「Titanic : Machine Learning from Disaster」(タイタニック号の生存者予測)があります。

タイタニック号の乗客の情報から傾向を見つけて、彼ら生存率を推定するタスク。
具体的に、データセットは、train.csv(train用) / test.csv(submit用) の2つが存在し、test.csvは、Survivedのみ情報が欠落しているため、これを推定して、KaggleサーバーにSubmitするというのがゴール。
何もないから何かみつかる。
上のサイトを参考にアカウント取得してやってみました。
① 「gender_submission.csv(答えファイル)」を選択してダウンロード。
② 「Submit Predictions(予測を送信する)」からアップロードする。
③ データがアップロードされていることを確認できたら、一番下にある「Make Submission(提出する)」をクリックする。
オメデトウ!♪
自分の名前がランキングに載りました!!

何それ!インチキ!

【引用】藤子不二雄「チンプイ」第一話
エンジニアとしての適正年齢が終わりに近づいているのに、こんなインチキしている場合じゃないでしょう。
まずは他人のサイトを参考に写経をする
機械学習に挑戦するのは、これで人生で5回目です。
最後は2年前。
株価予想をKerasでチャレンジして断念しました。
- 【6回目】Kerasを使った株の利益を計算(ディープラーニング)
- 【5回目】Kerasを使ったMatplotlibのグラフ整形と日本語表示(ディープラーニング)
- 【4回目】Kerasのモデル保存・利用(ディープラーニング)
- 【3回目】Kerasを使って活性関数・目的関数・最適化手法をまとめる
- 【2回目】KerasのFunctional API Modelの構造を理解する
- 【1回目】はじめてのKerasを使った株価予測(ディープラーニング)
ディープラーニングの基礎は理解したけど・・・。
今度は自力で実装できるように、もっとサンプルの多い世界で始めよう。
データの中身は次のような項目が書かれています。
この「Survived(生存)」か否かを他の情報の傾向データを参考に当てるのが、この問題の趣旨です。
PassengerId : kaggleが割り振った個人に割り振ったID
Survived : 生存・非生存(予測対象)
Pclass : 客室のクラスを表すコード1は1等、2は2等、3は3等
Name : 名前
Sex : 性別
Age : 年齢
SibSp : 同行した兄弟または配偶者の人数
Parch : 同行した親または子どもの人数
Ticket : チケット番号
Fare : 料金
Cabin : キャビン番号
Embarked : 乗船した港
例えば、
- 若い男性より高齢者・女性・子供の方が生存率は高い
- 料金が低額より高額なお客の方が生存率は高い
のような仮説を元に問題を解いていきます。
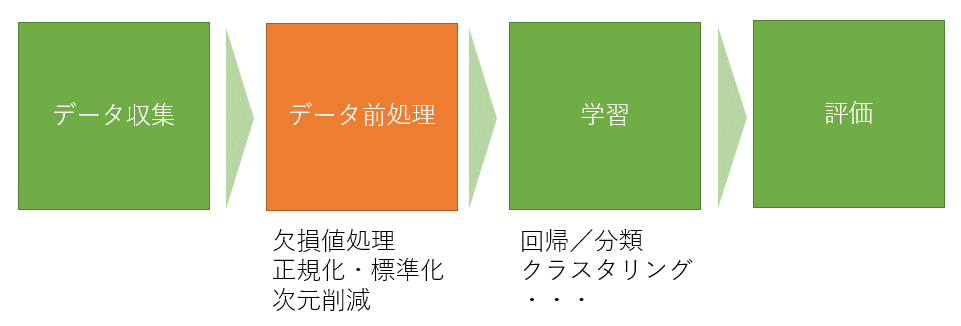
解き方は機械学習なら上の図のような進め方になります。
データ前処理(データクレンジング)
ここは大事な部分ですが、今回は説明を省略します。
具体的には次のような加工をします。
- 「Name」「Ticket」「Cabin」は使わない
- 「Age」「Fare」の欠損値は平均で埋める
- 「Sex」は 0,1 に
- 「Age」は標準化して利用する
これらの仮説検証は次回以降に行います。
Kerasを使って学習ネットワークを組む
今回も、TensorFlowのラッパーであるKerasを使います。

ただし、まだ自分でノードを構築できるほどのスキルはありません。
色々なインターネットに公開されているスクリプトを組み合わせながら作成してみました。
自分よりにノード作ると、全く動きませんでした・・・。
完成したソースコード
Jupyter Notebookを利用したサンプルが多く、スクリプトとしてまとまったものは少なかったです。
実際のデータアナリストは、コマンドを打つような感覚でデータ加工して機械学習使って分析されるということですね・・・。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 |
import time import numpy as np import pandas as pd from keras.layers import Dense, Activation from keras.models import Sequential from sklearn.preprocessing import StandardScaler # Data Cleansing def normalize_data(data): data = data.drop(["PassengerId", "Name", "Ticket", "Cabin"], axis=1) # Changing the name of Column (PClass) to (TicketClass) for easy understanding data = data.rename(columns = {"Pclass":"TicketClass"}) # Complement the missing values of "Age" column with average of "Age" data["Age"] = data["Age"].fillna(data["Age"].mean()) # 全てのAgeを平均 0 標準偏差 1になるように標準化 scaler = StandardScaler() data["Age"] = scaler.fit_transform(data["Age"].values.reshape(-1, 1)) # Complement the missing values of "Fare" column with average of "Fare" data["Fare"] = data["Fare"].fillna(data["Fare"].mean()) # Convert "Sex" to be a dummy variable (female = 0, Male = 1) data["Sex"] = data["Sex"].replace(["male", "female"], [0, 1]) # Convert "Embarked" to be a dummy variable (S = 0,C = 1, Q = 2) data["Embarked"] = data["Embarked"].fillna("S") data["Embarked"] = data["Embarked"].replace(["C", "S", "Q"], [0, 1, 2]) # 他の書き方例 # data["Embarked"] = data["Embarked"].dropna().map({"S": 0, "C": 1, "Q": 2}).astype(int) # data["Embarked"][data["Embarked"] == "S"] = 0 return data # 学習用データ x_data、検証用結果 y_data の割り当て def build_train_test_data(data, rate=0.8): # 答えの削除 y_data = data["Survived"] x_data = data.drop(["Survived"], axis=1) # 全データのうち、80% を学習用データ、20% を検証用データに割り当て train_size = int(len(x_data) * 0.8) # 80% を学習用データ x_train = x_data[:train_size] # Inputs y_train = y_data[:train_size] # Output (Survived) # 20% // 2 小数点以下は切り捨て valid_test_size = (len(x_data) - train_size) // 2 # 10% を検証用テストデータ x_test = x_data[valid_test_size + train_size:] y_test = y_data[valid_test_size + train_size:] # 作成した行列出力 print("x_train:{}".format(x_train.shape)) print("y_train:{}".format(y_train.shape)) print("x_test:{}".format(x_test.shape)) print("y_test:{}".format(y_test.shape)) return x_train, y_train, x_test, y_test # 学習ネットワーク構築 def build_model(input_dim): model = Sequential() model.add(Dense(20, input_dim=input_dim)) model.add(Activation("relu")) model.add(Dense(1, input_dim=20)) model.add(Activation("sigmoid")) return model def main(): # CSVを読み込む df_train = pd.read_csv("train.csv") normalized_data = normalize_data(df_train) x_train, y_train, x_test, y_test = build_train_test_data(normalized_data, 0.8) start = time.time() # x_train.shape[1] = 7 model = build_model(x_train.shape[1]) model.compile(loss="binary_crossentropy", optimizer="sgd", metrics=["accuracy"]) # エポックは 120、バッチサイズは 16 model.fit(x_train, y_train, nb_epoch=120, batch_size=16) print(str(time.time() - start)) # 結果出力 [loss, accuracy] = model.evaluate(x_test, y_test) print("loss:{0} -- accuracy:{1}".format(loss, accuracy)) # テスト値を読み込み df_out = pd.read_csv("test.csv") predictions = model.predict(normalize_data(df_out)) df_out["Survived"] = np.round(predictions).astype(np.int) # CSVに出力する df_out[["PassengerId","Survived"]].to_csv("submission.csv",index=False) main() |
学習用データと検証用結果の割り当て、学習モデルの構築が自力で出来ない・・・。
結果出力
Warningは無視するために、次のようにコンソール上で実行します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# python -W ignore test.py x_train:(712, 7) y_train:(712,) x_test:(90, 7) y_test:(90,) Epoch 1/120 16/712 [..............................] - ETA: 13s - loss: 3.9929 - acc: 0.4375 432/712 [=================>............] - ETA: 0s - loss: 1.6842 - acc: 0.5903 712/712 [==============================] - 0s 558us/step - loss: 1.5915 - acc: 0.6110 Epoch 2/120 ..(省略).. 16/712 [..............................] - ETA: 0s - loss: 0.4608 - acc: 0.8750 400/712 [===============>..............] - ETA: 0s - loss: 0.5149 - acc: 0.7525 712/712 [==============================] - 0s 134us/step - loss: 0.5090 - acc: 0.7654 12.863690853118896 32/90 [=========>....................] - ETA: 0s 90/90 [==============================] - 0s 695us/step Using TensorFlow backend. loss:0.4676677107810974 -- accuracy:0.8222222248713176 |
学習に必要な時間は12秒程度です。
何度か実験したところ、精度は「78%~85%」程度でブレるようです。
まとめ
データ加工部分で何をしているのか?は理解しましたが、pythonでは多くの書き方がありシンプルな実装方法が分かっていません。
Kerasを使ったネットワーク構築はこれから学んでいきます。そもそも、Sequentialを使わずにFunctional APIを利用したいです。
また、データ加工部分はシンプルなので、Pytorchや、TensorFlowも直接利用して理解を深めないと・・・・。
他にも、多くの機械学習が用意されているので、こちらも理解しなきゃ・・・・。
- 線形回帰
- K近傍法
- SVM(線形分類器)
- SVM(RBF分類器)
- ナイーブベイズ
- 決定木
- ランダムフォレスト
- Perceptron
Jupyter Notebookを利用した、仮説を導くためのデータのグラフ化、可視化もね。
やることは沢山ある。少しずつ理解だね・・。

