今回は、kaggleの入門者向けチュートリアルコンペ「住宅価格予測」をやってみます。
House Prices: Advanced Regression Techniques

各種指標を用いて住宅の価格を予測する分析問題です。
- 【5回目】Kaggle の Titanic Prediction Competition でクラス分類(XGBoost、LightGBM、CatBoost編)
- 【4回目】Kaggle の Titanic Prediction Competition でクラス分類(scikit-learn編)
- 【3回目】Kaggle の Titanic Prediction Competition でクラス分類(Keras Functional API編)
- 【2回目】Kaggle の Titanic Prediction Competition でクラス分類(Jupyter Notebook編)
- 【1回目】Kaggle の Titanic Prediction Competition でクラス分類(Keras導入編)
データ分析のプロセスとして、CRISP-DM(CRoss Industry Standard Process for Data Mining)というものがあります。

モデリングより前のステップである「ビジネスの理解」「データの理解(Exploratory Data Analysis)」「データの準備(Feature Engineering)」のステップが大半を占めます。
まず「データの理解(Exploratory Data Analysis)」についてです。
データ分析の前提知識
教師あり学習には回帰と分類があります。
タイタニック問題は「2クラス分類」のチュートリアルでした。
住宅価格の予測は「回帰」のチュートリアルです。
「回帰」は株価分析など出力が連続値、「分類 (クラスタリング)」は文字認識など離散値という違いがあります。
回帰分析とは何か?
関数をデータに当てはめることによって、ある変数yの変動を別の変数xの変動により説明・予測・影響関係を検討するための手法です。
乱暴にいってしまえば、複数の変数間の関係を一次方程式(Y=aX+b)の形で表現する分析方法です。
次のような用途があります。
- 因果関係が想像される2つの変数間の関係を調べる(因果関係の証明)
- 売上高と宣伝費の関係が分かる→目標とする売上高に対して宣伝費を決定する(制御)
- 人口と商店数の関係が分かる→ある市の人口からその市の商店数を予測する(予測)
予測したい変数のことを目的変数(または被説明変数)といいます。
また、目的変数を説明する変数のことを説明変数(または独立変数)と呼びます。
説明変数が2つ以上の時は重回帰、1つのとき特に単回帰と呼びます。
Python3.8でjupyter-notebookを動作させる
pip でインストールして動かそうとするとエラーが出ます。
|
1 2 3 4 5 6 7 8 9 |
# # /c/Python38/Scripts/jupyter-notebook Traceback (most recent call last): File "c:\python38\lib\runpy.py", line 193, in _run_module_as_main return _run_code(code, main_globals, None, File "c:\python38\lib\runpy.py", line 86, in _run_code .... File "c:\python38\lib\asyncio\events.py", line 501, in add_reader raise NotImplementedError NotImplementedError |
ググると対応策がありました。
「C:\Python38\Lib\site-packages\tornado\platform」の「asyncio.py」の最後に下記を書き込みます。
|
1 2 3 |
import sys if sys.platform == 'win32': asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy()) |
無事に起動を確認できたので、データ前処理を進めていきます。
探索的データ解析(データの理解:EDA)
以前のjupyter-notebook利用例と同じように、データを確認します。
- データの各特徴名とその意味の確認
- データの取り込み(.read_csv)
- 表の一部分表示(pandasの.head())
- データの大きさの確認(pandasの.shape)
- ヒストグラムによる分布の可視化(.hist)
- 特徴量ごとの平均値、最大値、最小値などの統計量確認(pandasの.describe())
- 欠損値チェック(pandasの.isnull().sum())
- 型チェック(pandasの.dtypes())
- ヒートマップによる相関の強い特徴量チェック(heatmap)
- 外れ値の確認(.regplot)
- 散布図や箱ひげ図を用いた目的変数と、説明変数の関係の可視化(.boxplot)
- 時系列データであれば、時系列トレンドの可視化
なお、綺麗なグラフが描写できる「seaborn」も利用しながら可視化しています。
データの各特徴名とその意味の確認
Kaggleの提供しているデータ「data_description.txt」に変数にどんなデータが格納されているのか説明があります。
タイタニックと比べて非常に説明変数が多く、79項目(+価格1項目)あります。
BsmtFullBath:地下フルバスルーム
BsmtHalfBath:地下ハーフバスルーム
FullBath:グレード以上のフルバスルーム
HalfBath:グレード以上のハーフバス
Bedroom:地下室より上の寝室の数
Kitchen:キッチンの数
KitchenQual:キッチンの質
などが、数字や文字列、5段階等で評価されていることが分かります。
なお、今回は「SalePrice」を予測するのがミッションです。
SalePrice – the property’s sale price in dollars. This is the target variable that you’re trying to predict.
データが少なければ一つずつの意味を把握したいですが、今の時点では必要に応じて確認することにします。
データの取り込み(.read_csv)
ファイル形式によって、色々な方法があります。
|
1 2 3 4 5 6 7 |
# `header=None`を指定せず`pd.read_csv('CSVファイル名')`とした場合は1行目が自動的にカラム名として挿入される # CSVファイルで取り込む場合 df = pd.read_csv('CSVファイル名', header = None) # Excelファイルで取り込む場合 df = pd.read_excel('Excelファイル名', sheetname='シート名', header = None) # コピペで取り込む場合 df = pd.read_clipboard(header = None) |
因みに、カラム名を変えるには次のように記載します。
|
1 |
df = df.rename(columns = {'変更前カラム名1': '変更後カラム名1', '変更前カラム名2': '変更後カラム名2'}) |
今回はCSVファイルなので次のように取り込みます。
|
1 2 |
import pandas as pd df_train = pd.read_csv("train.csv") |
表の一部分表示(pandasの.head())
まずは、データがどういう構造なのか探っていきます。
|
1 |
display(df_train.head(10)) |
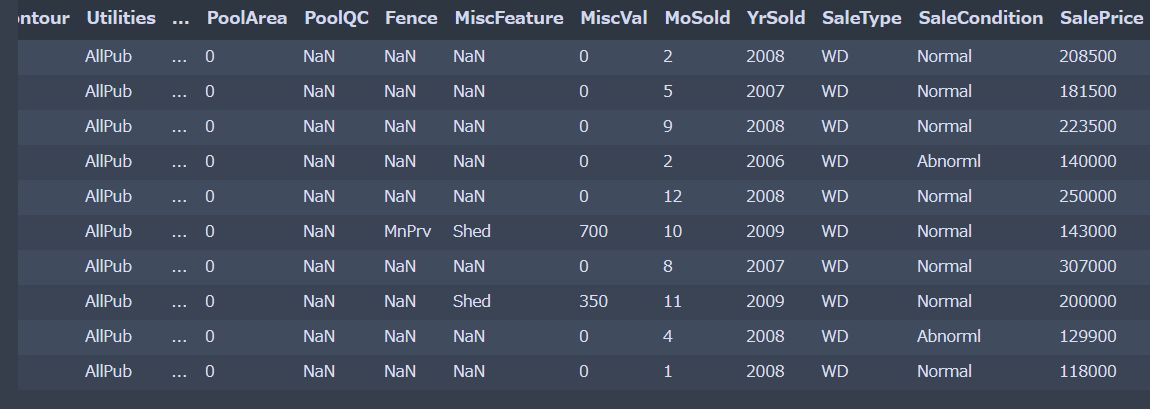
欠損値が多く、文字列情報も多く含まれているようです。
データの大きさの確認(pandasの.shape)
変数の数を確認してみます。
|
1 |
print('The size of train is : ' + str(df_train.shape)) |
|
1 |
The size of train is : (1460, 81) |
81変数あり1460件の住宅情報が含まれている事が分かります。
ヒストグラムによる分布の可視化(.hist)
今度は視覚化するためにヒストグラムで出力してみます。
|
1 2 3 4 5 |
import matplotlib.pyplot as plt df_train.hist(bins=50, figsize=(20,15)) # creates a figure with 10 (width) x 5 (height) inches plt.rcParams['figure.figsize'] = [10, 5] plt.show() |
出力結果です。

「SalePrice」が正規分布となっていないようにみえます。
特徴量ごとの平均値、最大値、最小値などの統計量確認(pandasの.describe())
回帰(Regression)分析の場合、ターゲットの値がどちらかに偏らず正規分布に従っていることが重要です。
「SalePrice」の統計量を確認します。
|
1 2 |
# データの概要 df_train['SalePrice'].describe() |
|
1 2 3 4 5 6 7 8 9 |
count 1460.000000 mean 180921.195890 std 79442.502883 min 34900.000000 25% 129975.000000 50% 163000.000000 75% 214000.000000 max 755000.000000 Name: SalePrice, dtype: float64 |
50%が16万なのに対して、平均(mean)が18万となっています。
また、最小値(min)が3万、最大値(max)が75万なので偏っており、正規分布ではありません。
特徴エンジニアリングの際に、対数変換が必要です。
欠損値チェック(pandasの.isnull().sum())
データ分析において、欠損値の処理は1つの重要なポイントです。
Kaggleでもスピード重視でこのパートを雑に行うとパフォーマンスが上がりません。
0より大きい数で降順にソートをかけ欠損値を確認します。
|
1 2 |
# 学習データの欠損状況 df_train.isnull().sum()[df_train.isnull().sum()>0].sort_values(ascending=False) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
PoolQC 1453 MiscFeature 1406 Alley 1369 Fence 1179 FireplaceQu 690 LotFrontage 259 GarageYrBlt 81 GarageType 81 GarageFinish 81 GarageQual 81 GarageCond 81 BsmtFinType2 38 BsmtExposure 38 BsmtFinType1 37 BsmtCond 37 BsmtQual 37 MasVnrArea 8 MasVnrType 8 Electrical 1 dtype: int64 |
凄い数の欠損があります・・・・。
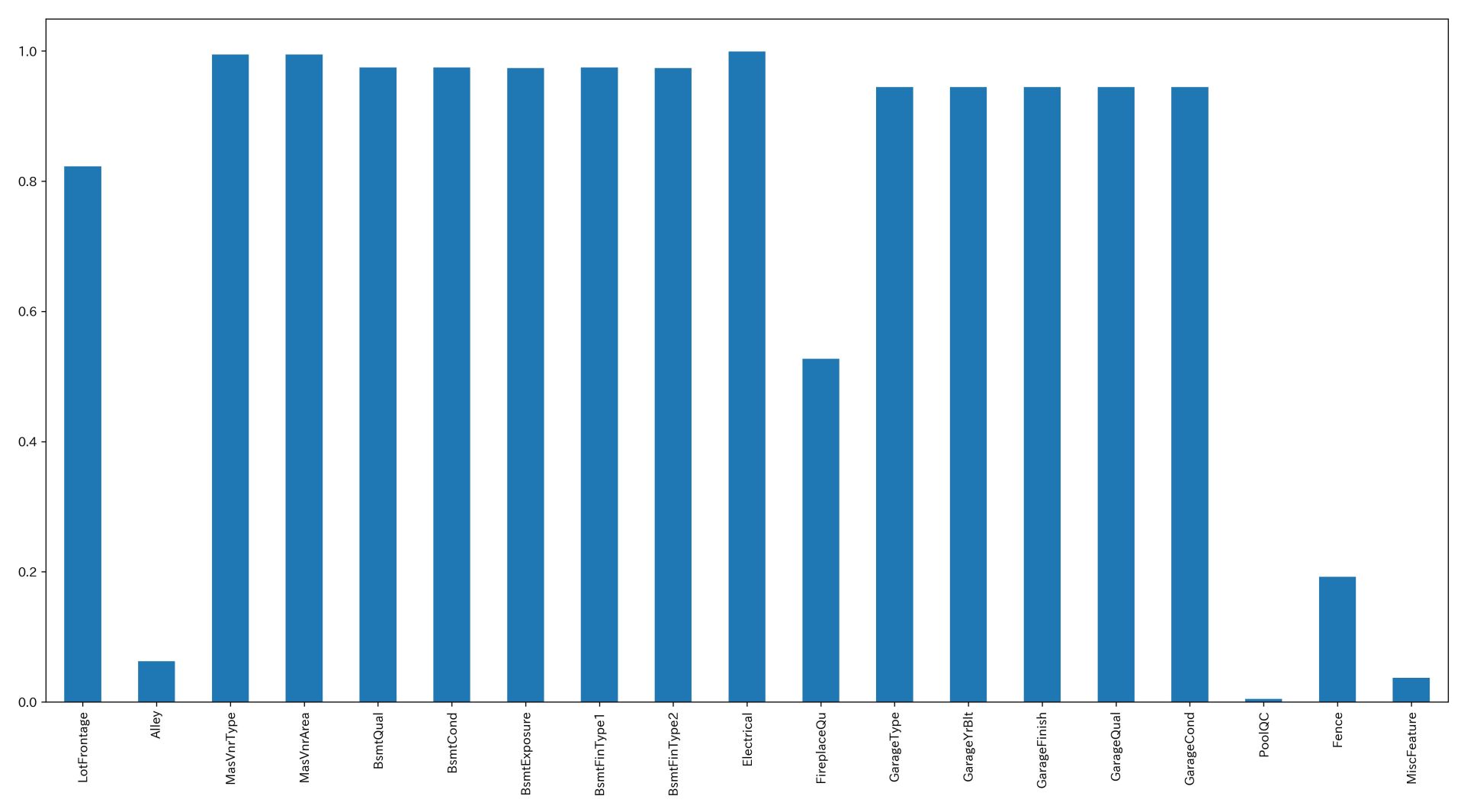
可視化は次のように記載します。
【matplotlibの場合】
|
1 2 3 4 |
import matplotlib.pyplot as plt fig, ax = plt.subplots(figsize=(20,10)) (1 - df_train.isnull().mean()[df_train.isnull().sum() > 0]).abs().plot.bar(ax=ax) fig.savefig("output.png", dpi=300) |
【seabornの場合】
|
1 2 3 4 5 6 7 8 |
import matplotlib.pyplot as plt import seaborn as sns sns.set() fig, ax = plt.subplots(figsize=(20,10)) all_data_na = (1 - df_train.isnull().mean()[df_train.isnull().sum()>0].abs()) plt.xticks(rotation='90') sns.barplot(x=all_data_na.index, y=all_data_na) fig.savefig("output.png", dpi=300) |
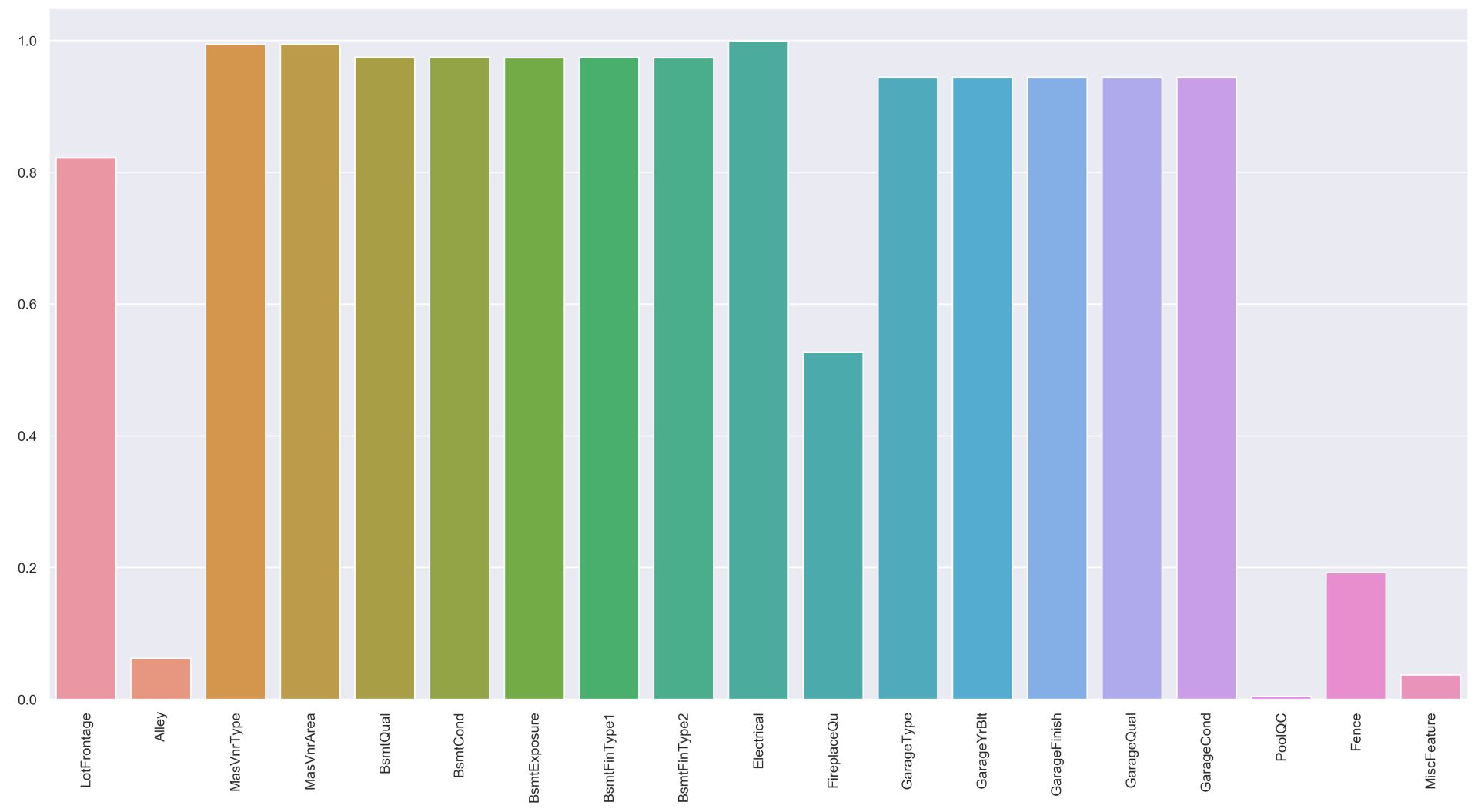
最も欠損が多いのはPoolQC(プールのクオリティ)です。
型チェック(pandasの.dtypes())
欠損値を含む列のデータタイプを確認します。
|
1 2 3 |
# 欠損値を含む列のデータタイプを確認 na_columns = df_train.isnull().sum()[df_train.isnull().sum()>0].index.tolist() df_train[na_columns].dtypes.sort_values() |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
LotFrontage float64 MasVnrArea float64 GarageYrBlt float64 GarageCond object GarageQual object GarageFinish object GarageType object FireplaceQu object Electrical object BsmtFinType2 object BsmtFinType1 object BsmtExposure object BsmtCond object BsmtQual object MasVnrType object Alley object Fence object MiscFeature object PoolQC object dtype: object |
PoolQC(プールのクオリティ)は欠損が大量にあり、更に文字列のデータした。
このカラムは削除したくなります。
ですが、Kaggleの提供しているデータ「data_description.txt」に「PoolQC(プールのクオリティ)」を再確認すると次のように記載されています。
PoolQC: Pool quality
Ex Excellent
Gd Good
TA Average/Typical
Fa Fair
NA No Pool
つまり、NaN(欠損)は「No Pool」の事であり、データの欠損そのものが情報となっています。
他の変数を確認しても欠損の意味は同じようです。
| 変数 | 意味 |
|---|---|
| PoolQC: Pool quality | 備え付けられているプールの質を表す。プールがない場合にはNA |
| MiscFeature: Miscellaneous feature not covered in other categories | その他の備え付けられている設備を表す。エレベータやテニスコートなど。特にない場合はNA |
| Alley: Type of alley access to property | 物件にアクセスするための道の種類(砂利なのか舗装されているのか)を表す。該当しない場合はNA |
| Fence: Fence quality | フェンスの質を表す。フェンスがない場合はNA |
| FireplaceQu: Fireplace quality | 暖炉の品質を表す。暖炉がない場合はNA |
| LotFrontage: Linear feet of street connected to property | 物件に隣接した道路の長さ |
このため、欠損データの補完方法を考える必要があります。
ヒートマップによる相関の強い特徴量チェック(heatmap)
分析方針を立てるために、何の変数が「SalePrice(施設の売却価格)」と強い相関があるが一気に確認しておきましょう。
|
1 2 3 4 5 6 7 8 9 10 |
k = 20 # number of variables for heatmap df = df_train corrmat = df.corr() cols = corrmat.nlargest(k, "SalePrice")["SalePrice"].index cm = np.corrcoef(df[cols].values.T) fig, ax = plt.subplots(figsize=(12, 10)) sns.set(font_scale=1.2) hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt=".2f", annot_kws={"size": 10}, yticklabels=cols.values, xticklabels=cols.values) plt.show() fig.savefig("figure4.png") |
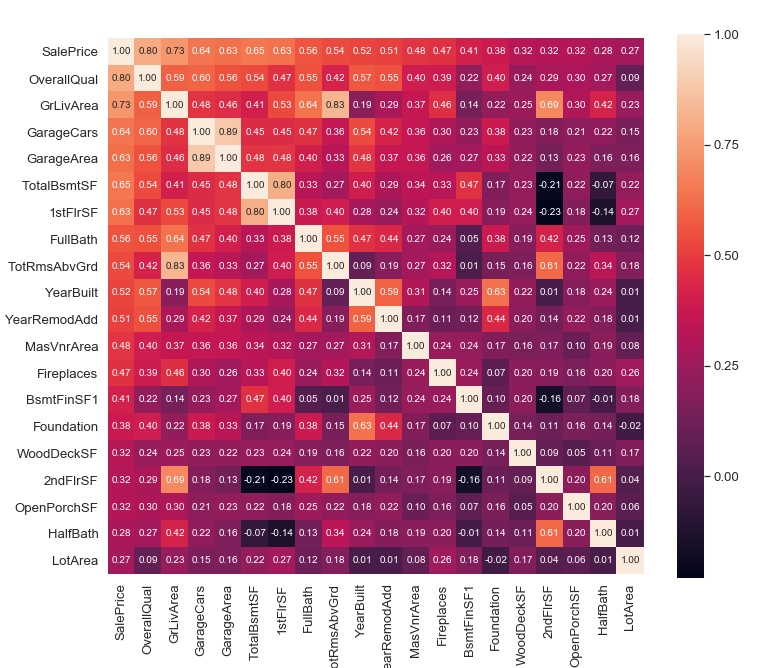
この結果から以下の点が読み取れます。
SalePrice(施設の売却価格)と強い相関がある
- OverallQual:全体的な素材と仕上げの品質
- GrLivArea:上階(地面)のリビングエリア平方フィート
- GarageCars:車庫のサイズ
- TotalBsmtSF:地下室の総平方フィート
強い相関がある(多重共線性の点から一つに絞る必要がある)
- GarageCars:車庫のサイズ
- GarageArea:車庫サイズ
- TotalBsmtSF:地下室の総平方フィート
- 1stFlrSF:1階平方フィート
- GrLivArea:上階(地面)のリビングエリア平方フィート
- TotRmsAbvGrd:グレード以上の総客室数
- 2ndFlrSF:2階平方フィート
- FullBath:グレード以上のフルバスルーム
- YearBuilt:元の建設日
- Foundation:基礎、基盤の種類
「GarageCars」「GarageArea」などは項目の意味からも相関の強さは明らかで、これらは多重共線性を引き起こします。
※ 最も一般的な解消法は、「相関関係が高いと考えられる説明変数を外すこと」です
このような状況を検出するのにヒートマップは便利です。
外れ値の確認
TotalBsmtSF(地下室の総平方フィート)はSalePrice(施設の売却価格)と強い相関がありました。
変数を見るとTotalBsmtSF以外にも物件の大きさを表しているものがあります。
- 1stFlrSF: 1階の広さ
- 2ndFlrSF: 2階の広さ
- TotalBsmtSF:地下の広さ
- GrLivArea:上階(地面)のリビングエリア平方フィート
こちらの合計の変数の外れ値を確認します。
|
1 2 3 4 5 6 7 8 9 |
#物件の広さを合計した変数を作成 df = df_train df["TotalSF"] = df["1stFlrSF"] + df["2ndFlrSF"] + df["TotalBsmtSF"] + df["GrLivArea"] fig = plt.figure(figsize=(9,6)) sns.regplot(x=df["TotalSF"], y=df["SalePrice"]) plt.xlabel("TotalSF") plt.ylabel("SalePrice") plt.show() fig.savefig("figure4.png") |
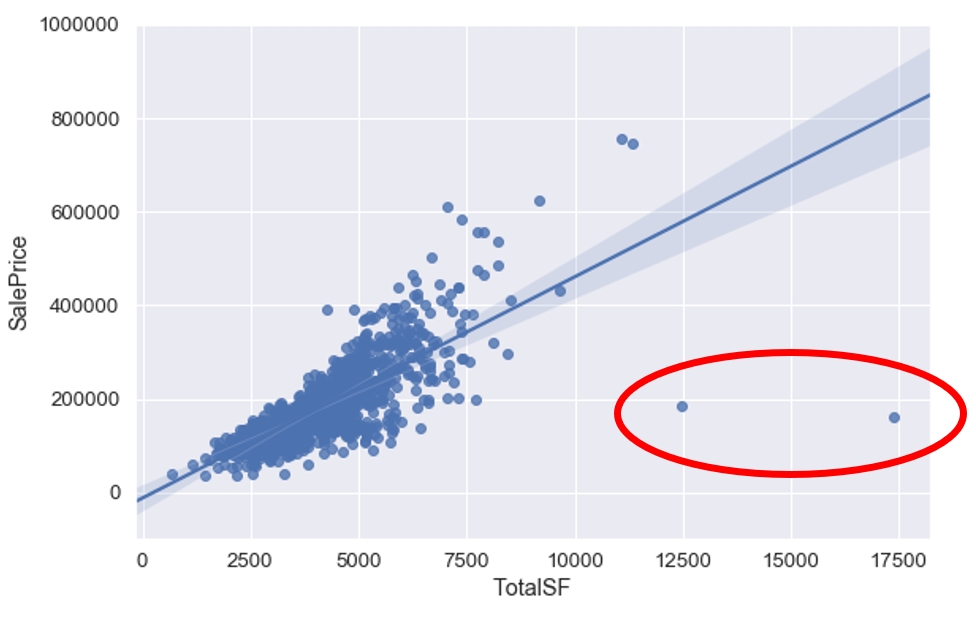
TotalSFが10000より小さく、SalePriceが300000より小さい場合は除去できそうです。
より詳細に確認したい場合は次のように記載できます。
|
1 2 3 |
# Seaborn(jointplot)を使うと散布グラフとヒストグラムが合成される # kind="reg"を指定すると回帰直線と信頼区間95%の影が表示される sns.jointplot("TotalSF", "SalePrice", df, kind="reg") |
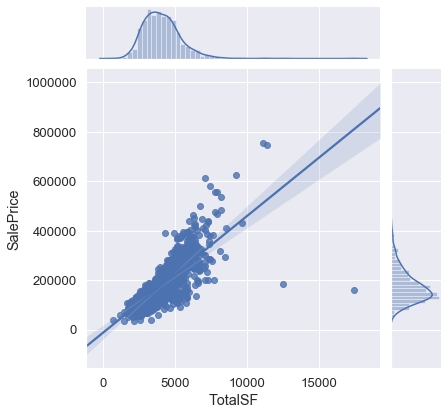
散布図や箱ひげ図を用いた目的変数と、説明変数の関係の可視化
OverallQual(全体的な素材と仕上げの品質)はSalePrice(施設の売却価格)と相関が高かったので、外れ値の確認をしてみます。
「箱ひげ図」を出力して確認してみます。
|
1 2 3 4 5 6 7 |
#box plot overallqual/saleprice var = "OverallQual" data = pd.concat([df['SalePrice'], df[var]], axis=1) fig, ax = plt.subplots(figsize=(8, 6)) f = sns.boxplot(x=var, y="SalePrice", data=data) f.axis(ymin=0, ymax=800000); fig.savefig("figure6.png") |
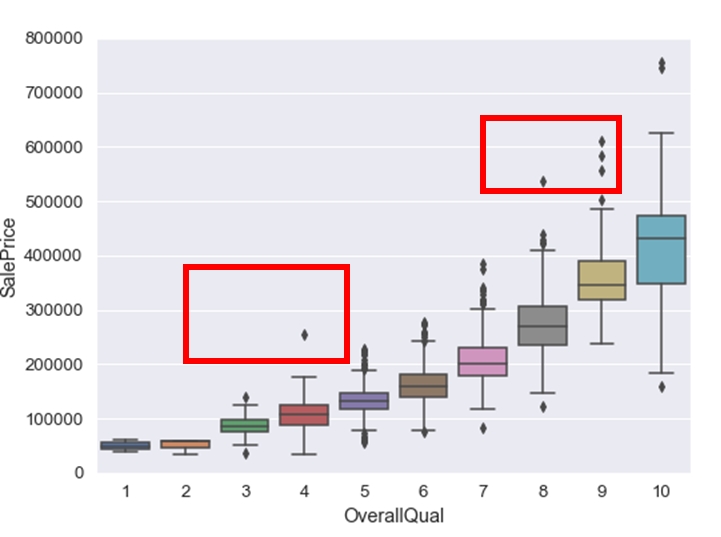
OverallQualが10より小さく、SalePriceが500000より大きい場合は除去できそうです。
また、OverallQualが5より小さく、SalePriceが200000より大きい場合は除去できそうです。
最後に、散布図に出力して俯瞰します。
全部出力するのは多すぎるので、相関の高い上位20変数を出力しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
df = df_train # 相関の高いものを合成 df["Garage"] = df["GarageCars"] + df["GarageArea"] df["Year"] = df["YearBuilt"] + df["YearRemodAdd"] df["SF"] = df["WoodDeckSF"] + df["OpenPorchSF"] df["TotalSF"] = df["1stFlrSF"] + df["2ndFlrSF"] + df["TotalBsmtSF"] + df["GrLivArea"] cols = ["GarageCars","GarageArea","1stFlrSF", "2ndFlrSF", "TotalBsmtSF", "GrLivArea", "YearBuilt", "YearRemodAdd", "WoodDeckSF", "OpenPorchSF"] for i in cols: df = df.drop(i, axis=1) # number of variables for heatmap k = 21 fig = plt.figure(figsize=(20,20)) # 各列の間の相関係数算出 corrmat = df.corr() # リストの最大値から順にk個の要素を取得 cols = corrmat.nlargest(k, "SalePrice")["SalePrice"].index # NumPyの相関係数を求める(最初はSalePriceなので不要) for i in np.arange(1,k): X_train = df[cols[i]] ax = fig.add_subplot(5,4,i) # 図やサブプロットのうち一番最後のものに描画 sns.regplot(x=X_train, y=y_train) plt.tight_layout() plt.show() |
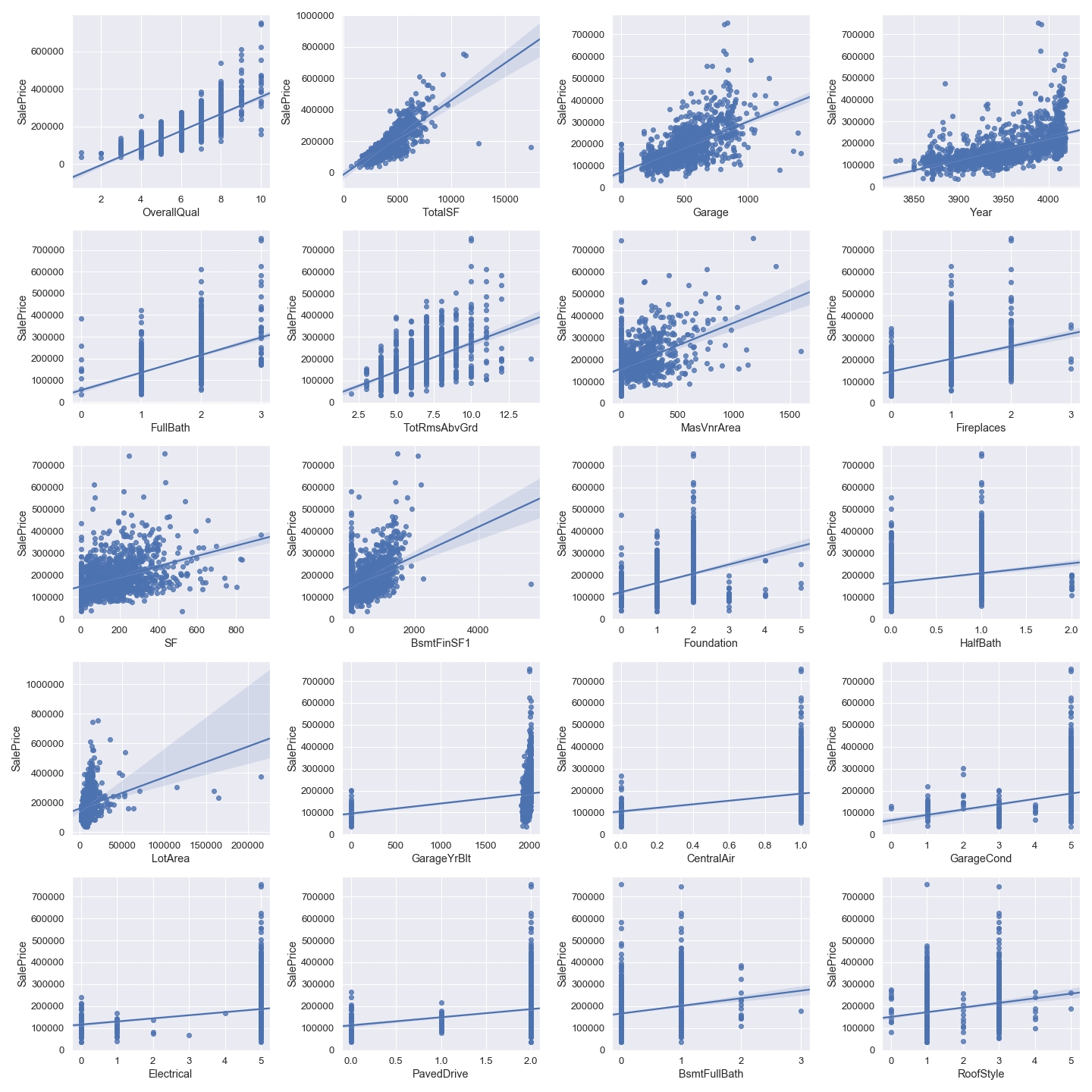
外れ値がまだ多くあるようです。
マニュアルで地道に削除することになります。
テストデータのみに存在する変数確認
学習データには存在せず、テストデータのみに存在するカテゴリ変数が存在するか確認します。
なぜなら、学習モデルがそのカテゴリを学習できず、予測値がおかしくなる可能性があるためです。
|
1 2 3 4 5 |
#カテゴリ変数となっているカラムを取り出す cal_list = df.dtypes[df.dtypes=="object"].index.tolist() #学習データにおけるカテゴリ変数のデータ数を確認 train_x[cal_list].info() |
今回は、学習データの中に数が0となっているカテゴリ変数はありません。
まとめ
タイタニックのチュートリアルで行った確認方法と同じですが、細かい確認が多いです。
この辺りは、他のデータを使っても同じかと思うのでライブラリ化しておきたいです。