今回はDigit Recognizerという入門コンペに参加してみます。

これは機械学習用の画像データとしては最も基本的かつよく使われるMNISTデータセットを用いた画像の分類コンテストです。
手書きで数字の0~9が書かれた28×28ピクセルの画像を教師有機械学習で学習させ、その学習器に、テスト用の画像データを読み込ませ、それぞれの画像がどの数字を表しているかを予測させるものです。
- 【8回目】KaggleのHouse Pricesで回帰分析(モデル作成編)
- 【7回目】KaggleのHouse Pricesで回帰分析(Feature Engineering編)
- 【6回目】KaggleのHouse Pricesで回帰分析(EDA:Exploratory Data Analysis編)
- 【5回目】Kaggle の Titanic Prediction Competition でクラス分類(XGBoost、LightGBM、CatBoost編)
- 【4回目】Kaggle の Titanic Prediction Competition でクラス分類(scikit-learn編)
- 【3回目】Kaggle の Titanic Prediction Competition でクラス分類(Keras Functional API編)
- 【2回目】Kaggle の Titanic Prediction Competition でクラス分類(Jupyter Notebook編)
- 【1回目】Kaggle の Titanic Prediction Competition でクラス分類(Keras導入編)
なお、Python3.8にアップデートしましたが、Tensorflowが未だ3.8に対応していないようです。
As you can refer from this page Tensorflow is only supported till python 3.7 as of now.
Python3.7以前の環境が必要です。消さなくてよかった・・・。
探索的データ解析(EDA:Exploratory Data Analysis)
MNISTのデータフォーマットは理解しているので、簡単に確認して次に進みます。
データの各特徴名とその意味の確認
Digit Recognizer は、MNISTと呼ばれる 0 ~ 9 の手書き文字画像(28 x 28 px)のデータセットを用いて、そのラベル(どの数字が書かれているか)を分類するタスクです。

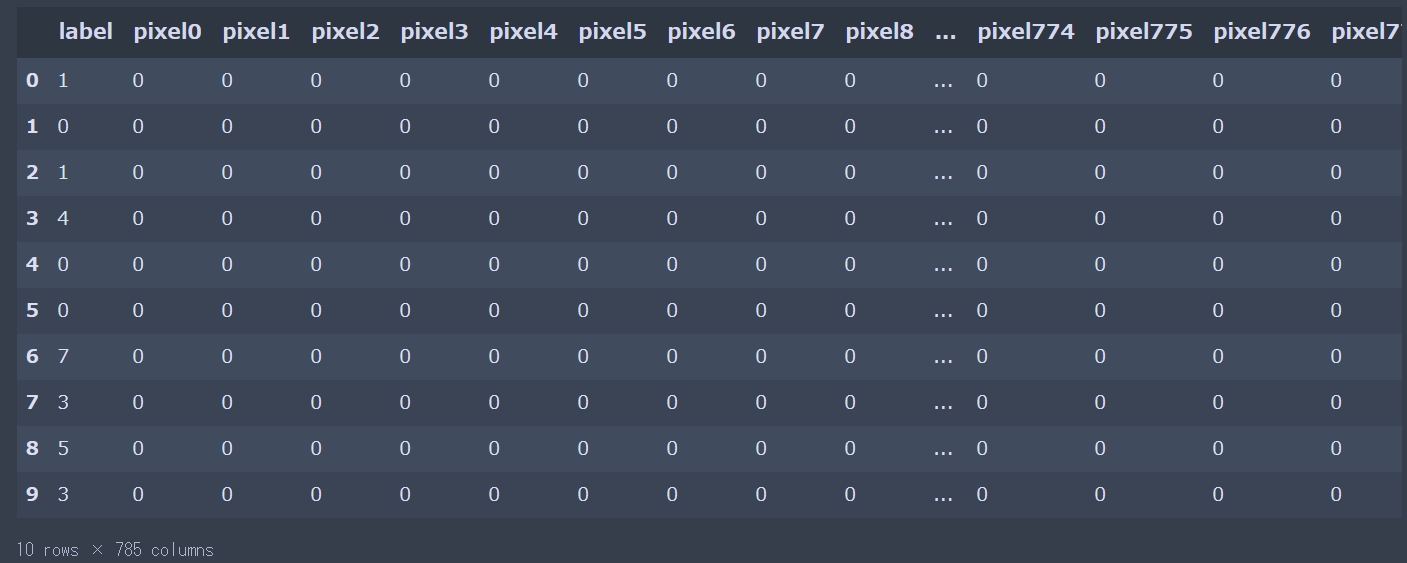
表の一部分表示(pandasの.head())
|
1 2 3 4 5 6 7 8 9 10 11 |
import time import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt sns.set() # CSV読み込み df_train = pd.read_csv("train.csv") df_test = pd.read_csv("test.csv") display(df_train.head(10)) |
0(黒)~255(白)でグレースケールの画像(画像形式は「PGM」)を表しています。
画像で出力してみましょう。
|
1 2 3 4 5 6 7 8 9 10 |
import pandas as pd import matplotlib.pyplot as plt def output_gray_image(df, i): img = df.drop(["label"], axis=1).iloc[i].values img = img.reshape((28,28)) plt.imshow(img, cmap='gray') df_train = pd.read_csv("train.csv") output_gray_image(df_train, 3) |
結果は次のようになります。
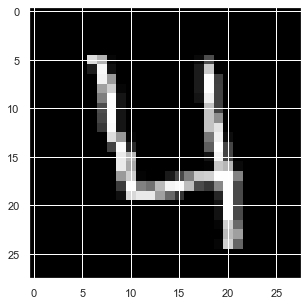
数字の「4」が現れます。
次に、PBM(2値画像)で出力してみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import pandas as pd import matplotlib.pyplot as plt def output_binary_image(df, i): add_lambda = lambda x: 1 if int(x) > 100 else 0 j = 0 for m in df.drop(["label"], axis=1).iloc[i]: print(add_lambda(m), end="") j = j + 1 if (j % 28 == 0): print("\n", end="") df_train = pd.read_csv("train.csv") output_binary_image(df_train, 3) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
0000000000000000000000000000 0000000000000000000000000000 0000000000000000000000000000 0000000000000000000000000000 0000000000000000000000000000 0000001100000000000000000000 0000000100000000001000000000 0000000110000000001000000000 0000000110000000001000000000 0000000110000000001000000000 0000000010000000001000000000 0000000010000000001100000000 0000000010000000001100000000 0000000011000000001100000000 0000000001000000000100000000 0000000001100000000100000000 0000000001100000000110000000 0000000001100000111111000000 0000000000111111100110000000 0000000000111110000010000000 0000000000000000000010000000 0000000000000000000010000000 0000000000000000000011000000 0000000000000000000011000000 0000000000000000000011000000 0000000000000000000000000000 0000000000000000000000000000 0000000000000000000000000000 |
「1」と「0」の数字で「4」を表しています。
データの可視化(snsの.countplot())
|
1 2 3 |
print('The size of train is : ' + str(df_train.shape)) print('The size of test is : ' + str(df_test.shape)) sns.countplot(df_train["label"]) |
|
1 2 |
The size of train is : (42000, 785) The size of test is : (28000, 784) |
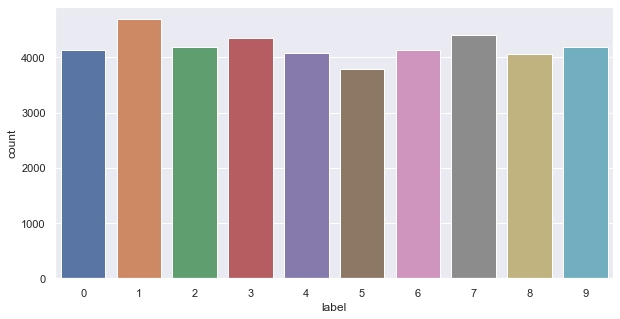
画像が4200種類存在し、28×28 pixel(784カラム)+ラベル=785カラム存在しています。
テストデータにはラベル(を推測するため)振られておらず、画像は28000種類です。
データ自体はほぼ均等に用意されているようです。
欠損値の確認
画像データなので欠損値はないと思いますが定石通り確認します。
|
1 2 |
df_train.isnull().sum()[df_train.isnull().sum()>0].sort_values(ascending=False) df_test.isnull().sum()[df_train.isnull().sum()>0].sort_values(ascending=False) |
|
1 |
Series([], dtype: int64) |
欠損値はありません。
データの準備(Feature Engineering)
通常であれば、ラベル付けが大変な作業となります。
がMNISTなので、既にラベル付けが完了しています。
各要素の正規化
MNISTデータを加工します。ここでは、28ピクセル×28ピクセルのデータを28×28=784次元のベクトルに変換し、ベクトルの成分を0~1の範囲に正規化します。
|
1 2 3 |
# 0~255を0~1に正規化 X_train = X_train / 255.0 X_test = df_test / 255.0 |
ラベルをone hot ベクトルにする
機械学習の特徴量や正解ラベルをone-hotベクトルにするには色々な方法があります。
- 自分で実装する
- sklearnのOneHotEncoderを使う
- pandasのget_dummiesを使う
- kerasのto_categoricalを使う
今回は、Kerasを使うので「to_categorical」を使ってみます。
|
1 2 |
#ラベルをone hot vectorsに (ex : 2 -> [0,0,1,0,0,0,0,0,0,0]) y_train = to_categorical(y_train, num_classes = 10) |
番目の引数(num_classes)として、数値を渡すと、データの最大値を指定できます。
結果は次のようになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
[3 2 1 4 4 1 0 1 0 2] [[0. 0. 0. 1. 0.] [0. 0. 1. 0. 0.] [0. 1. 0. 0. 0.] [0. 0. 0. 0. 1.] [0. 0. 0. 0. 1.] [0. 1. 0. 0. 0.] [1. 0. 0. 0. 0.] [0. 1. 0. 0. 0.] [1. 0. 0. 0. 0.] [0. 0. 1. 0. 0.]] |
モデル作成
画像処理は2000年代前半まではLinear kernelを用いたsupport vector machineが最も高い精度を出していましたが、2012年以降は、Deep Learningの方が高い精度を出すようになりました。
特に、画像認識・画像分類では「畳込みニューラルネットワーク(Convolutional Neural Network:CNN)」が高い精度を誇るアルゴリズムとしてよく利用されます。
今回は、Kerasを使って「MLP」と「CNN」を使ったディープラーニングの両方を試してみます。
MLP:MultiLayer Perceptronを試す
全結合層のみのもっとも単純なモデルです。

(単純)パーセプトロンを複数繋いで多層構造にしたニューラルネットで、MLP(多層パーセプトロン)と呼ばれます。
おもに音声認識での実用が進められています。
以前作った学習モデルを適用してみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 学習ネットワーク構築(Functional API ver) def build_model(input_dim): # モデル作成 inputs = Input(shape = (input_dim,)) layer = Dense(64, activation = 'relu')(inputs) dense = Dense(10, activation = 'softmax')(layer) model = Model(inputs = inputs, outputs = dense) model.summary() plot_model(model, to_file = 'model3.png', show_shapes = True) return model model = build_model(X_train.shape[1]) model.compile(loss = "categorical_crossentropy", optimizer = Adam(), metrics = ["accuracy"]) # エポックは 120、バッチサイズは 16 model.fit(X_train, y_train, epochs = 120, batch_size = 16) |
Dense()で全結合層を2層追加しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
x_train:(33600, 784) y_train:(33600, 10) x_test:(8400, 784) y_test:(8400, 10) _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_6 (InputLayer) (None, 784) 0 _________________________________________________________________ dense_11 (Dense) (None, 64) 50240 _________________________________________________________________ dense_12 (Dense) (None, 10) 650 ================================================================= Total params: 50,890 Trainable params: 50,890 Non-trainable params: 0 _________________________________________________________________ Epoch 1/120 33600/33600 [==============================] - 9s 277us/step - loss: 0.3376 - acc: 0.9026 Epoch 2/120 33600/33600 [==============================] - 7s 199us/step - loss: 0.1634 - acc: 0.9515 Epoch 3/120 33600/33600 [==============================] - 7s 211us/step - loss: 0.1195 - acc: 0.9651 ....(省略) 33600/33600 [==============================] - 7s 222us/step - loss: 0.0017 - acc: 0.9995 Epoch 119/120 33600/33600 [==============================] - 7s 223us/step - loss: 0.0035 - acc: 0.9990 Epoch 120/120 33600/33600 [==============================] - 7s 223us/step - loss: 6.7432e-04 - acc: 0.9998 loss:0.26080882655329146 -- accuracy:0.9725 641.2394087314606 |
計算時間は10分程度です。
では、結果を提出してみます。
![]()
スコアは「0.97357」で「Top 70%」となりました。
単にKerasを使っただけなのに、今までの入門コンペの中では一番高いスコアとなりました。
CNN:Convolutional Neural Networkを試す
CNNは、入力層と出力層の中間に位置する「畳み込み層(Convolution Layer)」と「プーリング層(Pooling Layer)」を交互に配置することで、特徴量を抽出し、全結合層で認識するニューラルネットワークのことです。
画像認識の分野で実用化が進んでおり、畳み込みニューラルネットワークと呼ばれます。

「畳み込み層」は、複数の最小データをまとめた特徴量を検出する層です。また「プーリング層」は、入力情報を圧縮する目的で使われる層です。
サンプルコードがあるので、それを見ながら作成してみます。
keras/mnist_cnn.py at master · keras-team/keras · GitHub
畳み込みニューラルネットでは、入力する画像の形状を保つために画像集合を4次元テンソル(4次元配列)で入力するのが一般的です。
なお、Kerasでは、4次元テンソルの各次元の位置がkeras.backend.image_data_format()(バックエンドのエンジン)によって変わります。
- th(Theano)では(サンプル数, チャネル数, 画像の行数, 画像の列数)
- tf(TensorFlow)では(サンプル数, 画像の行数, 画像の列数, チャネル数)
MNISTの入力数は白黒画像なのでチャネル数は1です。
|
1 2 3 |
# 1×784→28×28に変換(1次元→2次元に変換) X_train = X_train.values.reshape(-1,28,28,1) X_test = X_test.values.reshape(-1,28,28,1) |
学習モデルは次のようになっています(Sequential)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
model = Sequential() model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=input_shape)) model.add(Conv2D(64, (3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(num_classes, activation='softmax')) model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adadelta(), metrics=['accuracy']) |
モデルを図示化すると次のようになります、長い・・・。
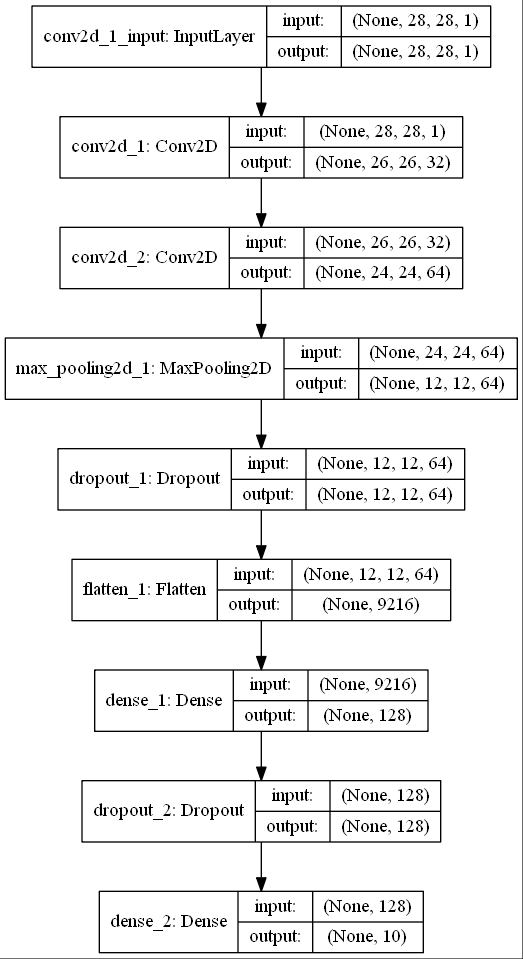
知らないモジュールが色々と出てきました。
- Conv2d: 2次元畳み込み層のモジュール
- MaxPool2D: 2次元最大プーリング層のモジュール
- Dropout: ドロップアウトモジュール
- Flatten: 入力を平滑化するモジュール
また、Adadeltaという最適化アルゴリズムが出てきています。
以前も「最適化手法(optimizer)」紹介しましたが、今回も後学に回します。
[引用] 勾配降下法の最適化アルゴリズムを概観する
Adagrad、Adadelta、RMSprop、Adamは最適で最良の収束するようです。なので、ディープラーニングと同じく今回はAdamを使ってみます。
結果は次のようになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
x_train:(33600, 28, 28, 1) y_train:(33600, 10) x_test:(8400, 28, 28, 1) y_test:(8400, 10) _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_1 (Conv2D) (None, 26, 26, 32) 320 _________________________________________________________________ conv2d_2 (Conv2D) (None, 24, 24, 64) 18496 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 12, 12, 64) 0 _________________________________________________________________ dropout_1 (Dropout) (None, 12, 12, 64) 0 _________________________________________________________________ flatten_1 (Flatten) (None, 9216) 0 _________________________________________________________________ dense_1 (Dense) (None, 128) 1179776 _________________________________________________________________ dropout_2 (Dropout) (None, 128) 0 _________________________________________________________________ dense_2 (Dense) (None, 10) 1290 ================================================================= Total params: 1,199,882 Trainable params: 1,199,882 Non-trainable params: 0 _________________________________________________________________ Epoch 1/12 33600/33600 [==============================] - 93s 3ms/step - loss: 0.3462 - acc: 0.8938 Epoch 2/12 33600/33600 [==============================] - 94s 3ms/step - loss: 0.1119 - acc: 0.9661 Epoch 3/12 33600/33600 [==============================] - 91s 3ms/step - loss: 0.0795 - acc: 0.9755 Epoch 4/12 33600/33600 [==============================] - 90s 3ms/step - loss: 0.0617 - acc: 0.9806 ...(省略) Epoch 11/12 33600/33600 [==============================] - 95s 3ms/step - loss: 0.0279 - acc: 0.9904 Epoch 12/12 33600/33600 [==============================] - 92s 3ms/step - loss: 0.0251 - acc: 0.9922 loss:0.04145396228034986 -- accuracy:0.9894047619047619 1139.27609872818 |
計算時間は18分程度です。
では、結果を提出してみます。
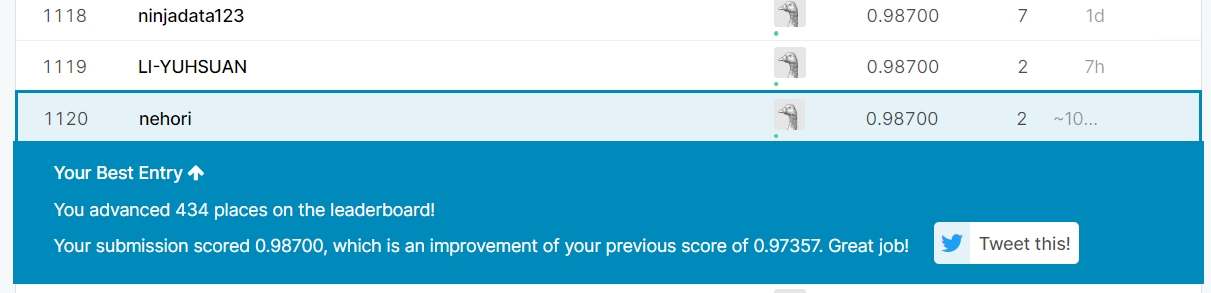
スコアは「0.98700」で「Top 50%」となりました。
Functional API で試す
Sequentialではなく、Functional API を使って学習モデルを構築してみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 畳込みニューラルネットワーク構築(Functional API) def build_model_cnn(input_dim): inputs = Input(shape=(28, 28, 1)) layer1 = Conv2D(32, kernel_size=(3, 3), activation='relu')(inputs) layer2 = Conv2D(64, (3, 3), activation='relu')(layer1) layer3 = MaxPooling2D(pool_size=(2, 2))(layer2) layer4 = Dropout(0.25)(layer3) layer5 = Flatten()(layer4) layer6 = Dense(128, activation='relu')(layer5) layer7 = Dropout(0.5)(layer6) output = Dense(10, activation='softmax')(layer7) model = Model(inputs=inputs, outputs=output) return model |
結果は次のようになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
x_train:(33600, 28, 28, 1) y_train:(33600, 10) x_test:(8400, 28, 28, 1) y_test:(8400, 10) _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_2 (InputLayer) (None, 28, 28, 1) 0 _________________________________________________________________ conv2d_5 (Conv2D) (None, 26, 26, 32) 320 _________________________________________________________________ conv2d_6 (Conv2D) (None, 24, 24, 64) 18496 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 12, 12, 64) 0 _________________________________________________________________ dropout_5 (Dropout) (None, 12, 12, 64) 0 _________________________________________________________________ flatten_3 (Flatten) (None, 9216) 0 _________________________________________________________________ dense_5 (Dense) (None, 128) 1179776 _________________________________________________________________ dropout_6 (Dropout) (None, 128) 0 _________________________________________________________________ dense_6 (Dense) (None, 10) 1290 ================================================================= Total params: 1,199,882 Trainable params: 1,199,882 Non-trainable params: 0 _________________________________________________________________ Epoch 1/12 33600/33600 [==============================] - 120s 4ms/step - loss: 0.3411 - acc: 0.8939 Epoch 2/12 ...(省略) Epoch 11/12 33600/33600 [==============================] - 92s 3ms/step - loss: 0.0265 - acc: 0.9910 Epoch 12/12 33600/33600 [==============================] - 100s 3ms/step - loss: 0.0247 - acc: 0.9921 loss:0.03514577395002735 -- accuracy:0.9907142857142858 1282.5768110752106 |
Sequentialと学習モデルが変わってしまいました・・・。
「input_2 (InputLayer)」が追加されてしましましたが、「Input(shape=(28, 28, 1))」以外の書き方が分かりません(誰か教えて下さい)。
ただし精度が上がり、提出するとスコアは「0.98757」で「Top 49%」となりました。
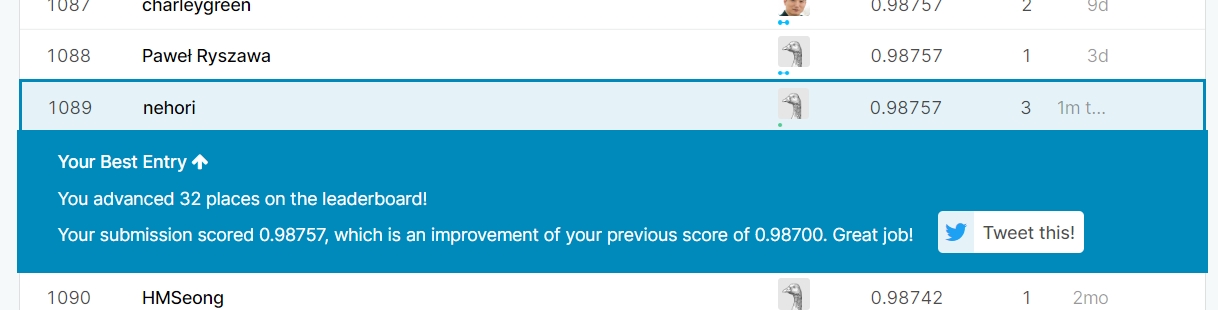
まとめ
今まで参加した入門コンペティションの中では、結果提出までの時間は短かったです。
当初計画していた入門コンペティション参加はこれで終わりとなります。
今後は、入門コンペの精度を高めるか次のステージに進むかは未定です。
ソースコード
「GitHub」にも公開しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 |
import time import pandas as pd import numpy as np import matplotlib.pyplot as plt from keras.models import Model from keras.optimizers import Adam from keras.utils import plot_model from keras.utils import to_categorical from keras.layers import Input, Dense, Activation from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split CNN = True def output_gray_image(df, i): img = df.drop(["label"], axis = 1).iloc[i].values img = img.reshape((28,28)) plt.imshow(img, cmap='gray') def output_binary_image(df, i): add_lambda = lambda x: 1 if int(x) > 100 else 0 j = 0 for m in df.drop(["label"], axis=1).iloc[i]: print(add_lambda(m), end="") j = j + 1 if (j % 28 == 0): print("\n", end = "") # 学習ネットワーク構築(Functional API) def build_model(input_dim): inputs = Input(shape = (input_dim,)) layer = Dense(64, activation = 'relu')(inputs) dense = Dense(10, activation = 'softmax')(layer) model = Model(inputs = inputs, outputs = dense) return model from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten from keras.layers import Conv2D, MaxPooling2D # 畳込みニューラルネットワーク構築(Sequential Version) def build_model_cnn2(input_dim): model = Sequential() model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1))) model.add(Conv2D(64, (3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(10, activation='softmax')) return model # 畳込みニューラルネットワーク構築(Functional API) def build_model_cnn(input_dim): inputs = Input(shape=(28, 28, 1)) layer1 = Conv2D(32, kernel_size=(3, 3), activation='relu')(inputs) layer2 = Conv2D(64, (3, 3), activation='relu')(layer1) layer3 = MaxPooling2D(pool_size=(2, 2))(layer2) layer4 = Dropout(0.25)(layer3) layer5 = Flatten()(layer4) layer6 = Dense(128, activation='relu')(layer5) layer7 = Dropout(0.5)(layer6) output = Dense(10, activation='softmax')(layer7) model = Model(inputs=inputs, outputs=output) return model # 学習用データ x_data、検証用結果 y_data の割り当て def build_train_test_data(df_train): # 答えの削除 y_train = df_train["label"] X_train = df_train.drop(labels = ["label"],axis = 1) # 0~255を0~1に正規化 X_train = X_train / 255.0 if (CNN): # 1×784→28×28に変換(1次元→2次元に変換) # TensorFlowでは4次元配列(サンプル数, 画像の行数, 画像の列数, チャネル数) X_train = X_train.values.reshape(-1, 28, 28, 1) #ラベルをone hot vectorsに (ex : 2 -> [0,0,1,0,0,0,0,0,0,0]) y_train = to_categorical(y_train, num_classes = 10) # データを訓練用(学習用)とテスト用に分割 X_train, X_test, y_train, y_test = train_test_split(X_train, y_train, train_size=0.8)# 1×784→28×28に変換(1次元→2次元に変換) # 作成した行列出力 print("x_train:{}".format(X_train.shape)) print("y_train:{}".format(y_train.shape)) print("x_test:{}".format(X_test.shape)) print("y_test:{}".format(y_test.shape)) return X_train, X_test, y_train, y_test def main(): # CSV読み込み df_train = pd.read_csv("train.csv") # 学習ネットワーク start = time.time() X_train, X_test, y_train, y_test = build_train_test_data(df_train) if (CNN): model = build_model_cnn(X_train.shape[1]) epochs = 12 batch_size = 128 else: model = build_model(X_train.shape[1]) epochs = 120 batch_size = 16 model.summary() plot_model(model, to_file = 'model3.png', show_shapes = True) # 最適化手法はAdamを使う model.compile(loss = "categorical_crossentropy", optimizer = Adam(), metrics = ["accuracy"]) # 訓練データを学習 model.fit(X_train, y_train, epochs = epochs, batch_size = batch_size) # 結果出力 [loss, accuracy] = model.evaluate(X_test, y_test, verbose = 0) print("loss:{0} -- accuracy:{1}".format(loss, accuracy)) print(str(time.time() - start)) # テスト値を読み込み df_test = pd.read_csv("test.csv") # 0~255を0~1に正規化 X_test = df_test / 255.0 if (CNN): # 1×784→28×28に変換(1次元→2次元に変換) X_test = X_test.values.reshape(-1, 28, 28, 1) predictions = model.predict(X_test) # one-hotベクトルで結果が返るので、数値に変換する df_out = [np.argmax(v, axis = None, out = None) for v in predictions] # 整形 df_out = pd.Series(df_out, name = "Label") submission = pd.concat([pd.Series(range(1, df_test.shape[0] + 1), name = "ImageId"),df_out],axis = 1) # CSVに出力する submission.to_csv("submission.csv",index=False) main() |