
今回も、kaggleの入門者向けチュートリアルコンペ「住宅価格予測」を解いてみます。
House Prices: Advanced Regression Techniques

各種指標を用いて住宅の価格を予測する分析問題です。
- 【7回目】KaggleのHouse Pricesで回帰分析(Feature Engineering編)
- 【6回目】KaggleのHouse Pricesで回帰分析(EDA:Exploratory Data Analysis編)
- 【5回目】Kaggle の Titanic Prediction Competition でクラス分類(XGBoost、LightGBM、CatBoost編)
- 【4回目】Kaggle の Titanic Prediction Competition でクラス分類(scikit-learn編)
- 【3回目】Kaggle の Titanic Prediction Competition でクラス分類(Keras Functional API編)
- 【2回目】Kaggle の Titanic Prediction Competition でクラス分類(Jupyter Notebook編)
- 【1回目】Kaggle の Titanic Prediction Competition でクラス分類(Keras導入編)
データ分析のプロセスとして、CRISP-DM(CRoss Industry Standard Process for Data Mining)というものがあります。
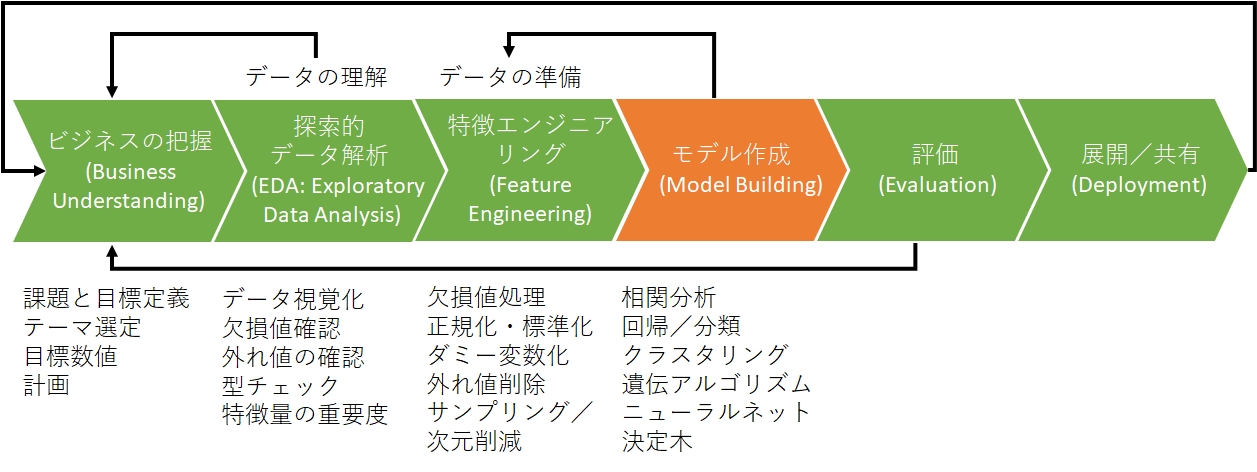
モデリングより前のステップである「ビジネスの理解」「データの理解(Exploratory Data Analysis)」「データの準備(Feature Engineering)」のステップが大半を占めます。
今回はタイタニックに続いて二度目の「モデル作成(Model Building)」です。
学習モデルの生成
選ぶべきモデルを確認したい場合、下記のSklearnのチートシートを使うのが早いです。
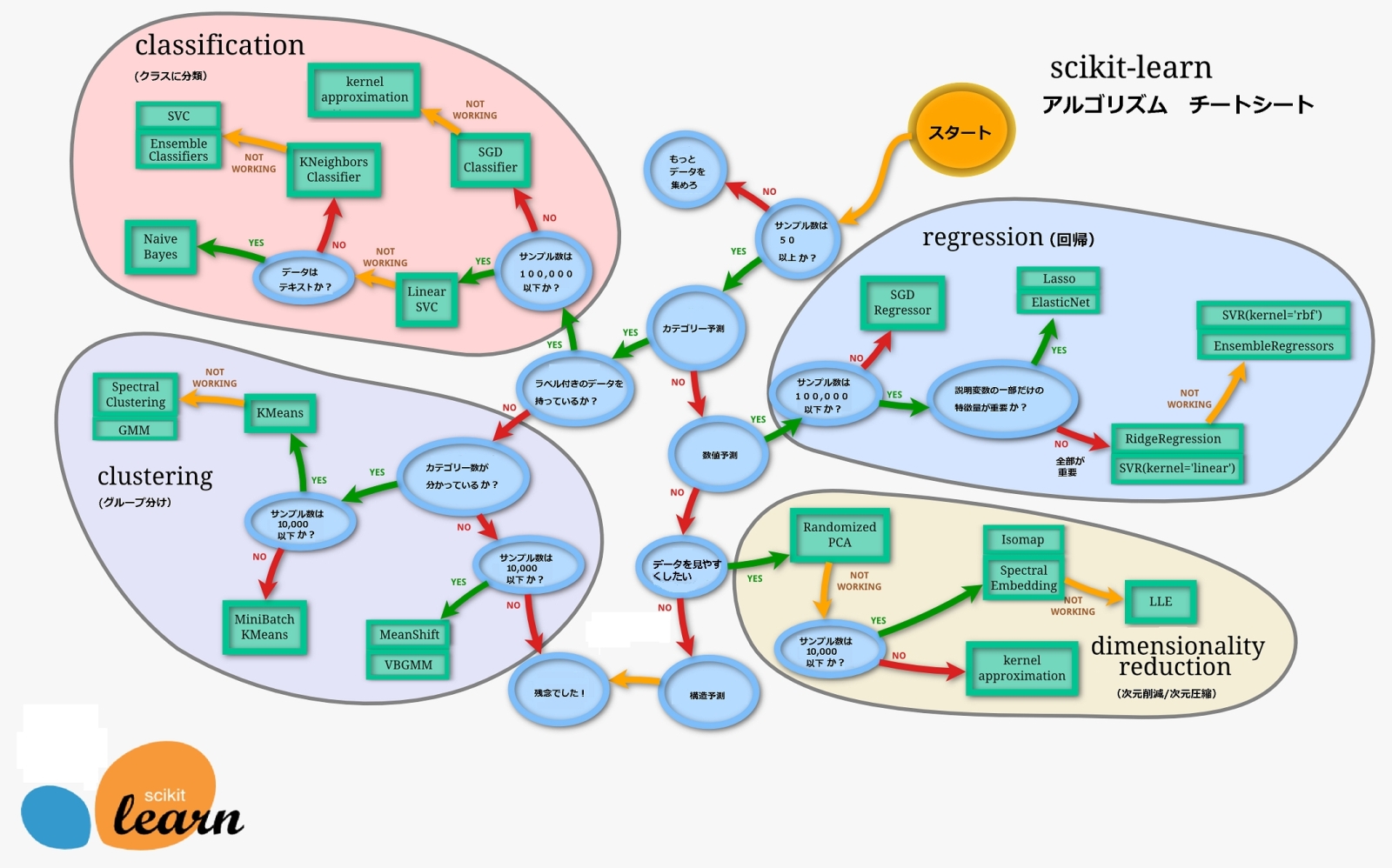
1.サンプル数は50以上か?→Yes
2.カテゴリ予測?→No
3.数値予測?→Yes
4.サンプル数は100000以下か?→Yes
5.説明変数の一部だけの特徴量が重要か?→Yes
この結果より、Regression(回帰)の中でもLasso回帰かElasticNetを使うのが良さそうです。
また、Kaggleで人気のXGBoost、LightGBM、CatBoostを適用して結果を確認します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
from sklearn.linear_model import LinearRegression, ElasticNet, Lasso, Ridge from xgboost import XGBRegressor from lightgbm import LGBMRegressor from catboost import CatBoostRegressor clf_names = ["LinearRegression", "ElasticNet", "Lasso", "Ridge", "LGBMRegressor", "CatBoostRegressor", "XGBRegressor", ] clf_params = ["", "max_iter=1000, tol=0.0001", "max_iter=1000, tol=0.0001", "", "boosting_type='gbdt', num_leaves=31, learning_rate=0.1, n_estimators=100", "logging_level='Silent'", "max_depth=3, learning_rate=0.1, n_estimators=100", ] def sklearn_model(x_train, y_train): start = time.time() models = list() model = None # もっと精度が高いモデル total = 0.0 name = "" for i in range(len(clf_names)): clf = eval("%s(%s)" % (clf_names[i], clf_params[i])) clf.fit(x_train, y_train) score = clf.score(x_train, y_train) print('%s Accuracy:' % clf_names[i], score) models.append(clf) if total <= score: total = score model = clf name = clf_names[i] print(str(time.time() - start)) print('%s was selected' % name) return models, model #学習データを目的変数とそれ以外に分ける X_train = df_train.drop("SalePrice", axis=1) X_test = df_test y_train = df_train["SalePrice"] # 学習データとテストデータを統合 models, model = sklearn_model(X_train, y_train) |
結果は次のようになります。
|
1 2 3 4 5 6 7 8 9 |
LinearRegression Accuracy: 0.9044288698146412 ElasticNet Accuracy: 0.5691257174663265 Lasso Accuracy: 0.5687335871411467 Ridge Accuracy: 0.9042581373935173 LGBMRegressor Accuracy: 0.984791064990173 CatBoostRegressor Accuracy: 0.9786456623137267 XGBRegressor Accuracy: 0.9448792895994685 5.725295782089233 LGBMRegressor was selected |
もっとも精度が高いのは「LightGBM」でした。
モデルにテストデータを投入し予測
この学習モデルに対してテストデータの予測値を求めます。
ターゲットをYeo-Johnson変換にしていたので、inverse_transformを使って元のスケールに戻す事を忘れないで下さい。
|
1 2 3 4 5 6 7 8 9 10 |
# Yeo-Johnson逆変換 def inverse_trans_yeo_johnson(df, df2): pt = PowerTransformer() pt.fit_transform(df) return pt.inverse_transform(df2) predictions = model.predict(X_test) df_result['SalePrice'] = inverse_trans_yeo_johnson(y_pre_train.values.reshape(-1,1), predictions.reshape(-1, 1)) df_result.to_csv("result.csv",index=False) display(df_result) |
最後に出力されたcsvファイルをKaggleにサブミットすればスコア表示されます。

「0.18152」でした。
スコアは対数平均二乗誤差(RMSLE)であり、この値が0に近ければちかほど、良いモデルが作れたということになります。
[応用] グリッドサーチ (Grid Search)とは?
グリッドサーチとはモデルの精度を向上させるために用いられる手法で、全てのパラメータの組み合わせを試してみる方法のことです。
イメージとしてはループさせてパラメータの組み合わせを全て試し、最も評価精度の良いものを探索します。
scikit-learnにはハイパーパラメータ探索用の「GridSearchCV」が用意されています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
import time from sklearn.model_selection import GridSearchCV ### 探索するパラメータ空間 def param(): ret = { 'num_leaves':[15, 20, 25, 31, 35], 'n_estimators':[50, 100, 250, 500, 750], 'boosting_type':['gbdt', 'dart', 'goss', 'rf'], } return ret start = time.time() # GridSearchCVのインスタンスを作成&学習&スコア記録 gscv = GridSearchCV(LGBMRegressor(), param(), cv=4, verbose=0) gscv.fit(x_train, y_train) # 最も良いパラメタ、モデル print(gscv.best_score_) print(gscv.best_params_) # スコアの一覧を取得 gs_result = pd.DataFrame.from_dict(gscv.cv_results_) gs_result.to_csv('gs_result.csv') print("time:" + str(time.time() - start)) |
次のような結果が出力されます。
|
1 2 3 |
0.8891145545988084 {'boosting_type': 'dart', 'n_estimators': 750, 'num_leaves': 15} time:251.56157684326172 |
私のPCでは、4分程度の計算時間が必要でした。
[応用] アンサンブル学習(Ensemble Learning)とは?
前回も「アンサンブル学習」って何?で簡単に記載しましたが、より詳細です。
機械学習において、単一の学習器をそのまま使うのではなく、複数の学習器を組み合わせることで、予測エラーを小さくする手法をアンサンブル学習(Ensemble Learning)といいます。
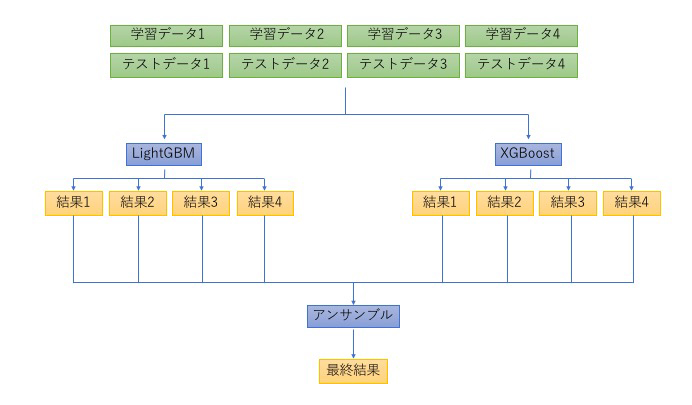
Kaggleなどのデータ分析コンペではよく利用されており、事実、多くのコンペティションの上位にランクインする方々はアンサンブル学習を活用しています。
※XGboostやLightGBMもアンサンブル学習の1つであるブースティングを用いています。
今回はXGBoostを2つ、LightGBMを1つの計3つを組み合わせました。
組み合わせ方は、基本はXGBoost1の結果に従うものの、たまにXGBoost1が、汎化性能が高いXGBoost2やLightGBMの結果と大きく外れる時は、LightGBMの結果を用いる、ということをしました。
のようなイメージです。
前提となる知識
まずはアンサンブル学習を理解する上で前提となる知識、「バイアス(Bias)」「バリアンス(Variance)」の2つを説明します。
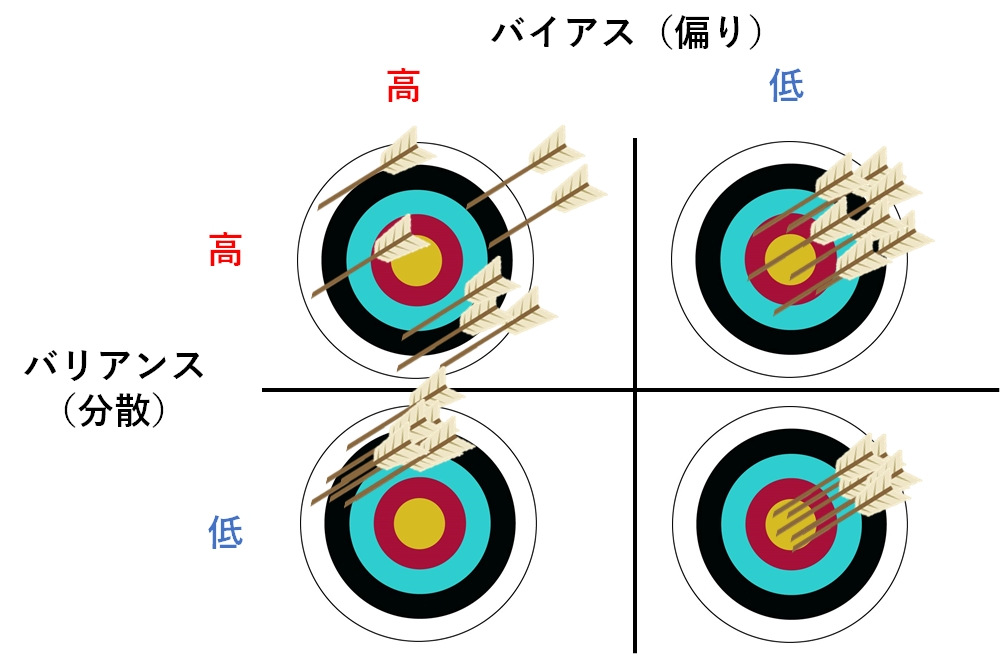
バイアスが大きいとはモデルの予測がかなり外れていることを表し、バイアスが小さいということはモデルがかなりの精度で予測できていることを表します。
バイアス(Bias)(偏り)
真の値(学習データ)と平均予測値のずれの大きさを意味します。
バイアスは「偏り」という意味であり、機械学習の概念的に覚える時は
「真の値とモデルの予測値の偏りがどのくらいあるか」
という風に覚えます。
より具体的には、バイアスは実際値と予測値との誤差の平均のことです。
値が小さいほど予測値と真の値の誤差が小さいということになります。
バリアンス(Variance)(分散)
バリアンスは予測値がどれだけ散らばっているかを示す度合いのことで、値が小さいほど予測値の散らばりが小さいということになります。
バリアンスが大きいと学習データごとに予測値が大きく変化することを表し、バリアンスが小さいと学習データにかかわらず予測値がほぼ一定になるということを表します。
バリアンスは「分散」という意味なので、「学習データに応じた予測値の分散の大きさ」を意味します。
3つの手法
アンサンブル(混合学習手法の)には次の3つがあります。
バギング(Bagging)
アンサンブルに用いる個々の弱学習機の学習において、すべての学習データを使うのではなく、その一部を抽出したデータで別個に学習する手法です。
それぞれの弱学習機が異なるデータセットで学習するために汎化性能が向上し、また学習の計算を並列処理できるという利点もあります。
バギングを利用する代表的なアルゴリズムとして「ランダムフォレスト」があります。
ブースティング(boosting)
最初にベースラインとなる弱学習器を生成し、これを改善するような学習を行って新たな学習器を生成していく手法です。
例えば、前回生成した弱学習器が誤って予測したデータに重点を置き、その予測を改善するように次の学習が行われます。
学習は逐次的に行われるため、バギングのような並列処理はできません。
スタッキング(stacking)
モデルを多段に積み上げていく手法です。
機械学習モデルの精度を向上させる手法の1つで、モデルを積み重ねる(Stackする)ことで精度を高めます。
1段目で様々な弱学習器の学習を行い、2段目では1段目の各学習器の出力(予測値)を使って、最終的な予測を行う学習器を生成します。
言い換えれば、2段目では1段目のどの弱学習器をどう組み合わせれば最も性能が上がるかを学習します。
Kaggleでは段数を増やした複雑なスタッキングモデルが用いられることもあり、計算量が非常に大きくなりモデルが複雑で扱いにくいというデメリットもあります。
[参考サイト] Kaggleの練習問題(Regression)を解いてKagglerになる
まとめ
「0.18152」という結果は「Top 79%」程度であり低いです。
Top 50%に入るには「0.13176」以下の誤差にする必要があり、難易度は高めです。
「LightGBM使って誤差0.13となった」などと書かれているサイトを見ていると、私の場合は前処理が不十分だと思われます。
関連書籍を立ち読みしても、日記上で記載しているノウハウとほぼ一緒だと思うので、後は経験を増やして精度を上げていくしかないと思ってます。
今回用いたコード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 |
import time import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt from sklearn.ensemble import RandomForestRegressor from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import PowerTransformer from sklearn.linear_model import LinearRegression, ElasticNet, Lasso, Ridge from sklearn.model_selection import GridSearchCV from xgboost import XGBRegressor from lightgbm import LGBMRegressor from catboost import CatBoostRegressor DEBUG = False # 外れ値の削除 def del_outlier(df): df = df.drop(df[(df["TotalSF"]>10000) & (df["SalePrice"]<300000)].index) for col in df: if df[col].dtype != "object" and col != "SalePrice": df = df.drop(df[(df[col]>=0) & (df["SalePrice"]>600000)].index) df = df.drop(df[(df["OverallQual"]<10) & (df["SalePrice"]>500000)].index) df = df.drop(df[(df["OverallQual"]<5) & (df["SalePrice"]>200000)].index) df = df.drop(df[(df["SF"]>=0) & (df["SalePrice"]>500000)].index) df = df.drop(df[(df["Garage"]>=0) & (df["SalePrice"]>500000)].index) df = df.drop(df[(df["Year"]>=0) & (df["SalePrice"]>500000)].index) return df # 多重共線性の削除 def del_multicollinearity(df): df["Garage"] = df["GarageCars"] + df["GarageArea"] df["Year"] = df["YearBuilt"] + df["YearRemodAdd"] df["SF"] = df["WoodDeckSF"] + df["OpenPorchSF"] df["TotalSF"] = df["1stFlrSF"] + df["2ndFlrSF"] + df["TotalBsmtSF"] + df["GrLivArea"] # カラム削除 cols = ["GarageCars","GarageArea","1stFlrSF", "2ndFlrSF", "TotalBsmtSF", "GrLivArea", "YearBuilt", "YearRemodAdd", "WoodDeckSF", "OpenPorchSF"] for i in cols: df = df.drop(i, axis=1) return df # 欠損値補完 def do_imputation(df): df['LotFrontage'] = df.groupby('Neighborhood')['LotFrontage'].transform(lambda x: x.fillna(x.median())) for col in df: #check if it is a number if df[col].dtype != "object": df[col].fillna(0.0, inplace=True) else: df[col].fillna("NA", inplace=True) return df # 順序関係に従ってエンコーディング def encode_mapping(df, i): num=-1 mapping={} for j in df.groupby(i)['SalePrice'].mean().sort_values().index: num+=1 mapping[j]=num df[i]= df[i].map(mapping) return df def encode_categorical1(df): cols = ("MSZoning", 'FireplaceQu', 'BsmtQual', 'BsmtCond', 'GarageQual', 'GarageCond', 'ExterQual', 'ExterCond','HeatingQC', 'PoolQC', 'KitchenQual', 'BsmtFinType1', 'BsmtFinType2', 'Functional', 'Fence', 'BsmtExposure', 'GarageFinish', 'LandSlope', 'LotShape', 'PavedDrive', 'Street', 'Alley', 'CentralAir') for col in cols: df = encode_mapping(df, col) return df # ラベルエンコーダー def encode_label(df, i): lbl = LabelEncoder() lbl.fit(list(df[i].values)) df[i] = lbl.transform(list(df[i].values)) return df def encode_categorical2(df): cols = ("MSZoning", 'FireplaceQu', 'BsmtQual', 'BsmtCond', 'GarageQual', 'GarageCond', 'ExterQual', 'ExterCond','HeatingQC', 'PoolQC', 'KitchenQual', 'BsmtFinType1', 'BsmtFinType2', 'Functional', 'Fence', 'BsmtExposure', 'GarageFinish', 'LandSlope', 'LotShape', 'PavedDrive', 'Street', 'Alley', 'CentralAir') for col in cols: df = encode_label(df, col) return df # 不要変数の削除 def del_variable(df): cols = ("MSSubClass", "OverallCond", "YrSold", "MoSold", "Id", "LandContour", "Utilities", "LotConfig", "Neighborhood", "Condition1","Condition2", "BldgType", "HouseStyle", "RoofStyle", "RoofMatl", "Exterior1st", "Exterior2nd", "MasVnrType", "Foundation", "Heating", "Electrical", "GarageType", "KitchenAbvGr", "MiscFeature", "SaleType", "SaleCondition") for i in cols: df = df.drop(i, axis=1) return df # 歪度の絶対値が0.5より大きい変数だけに絞る def count_skew(df): # 数値の説明変数のリストを作成 num_feats = df.dtypes[df.dtypes != "object"].index # 各説明変数の歪度を計算 skewed_feats = df[num_feats].apply(lambda x: x.skew()).sort_values(ascending = False) # 歪度の絶対値が0.5より大きい変数だけに絞る skewed_feats_over = skewed_feats[abs(skewed_feats) > 0.45].index if (DEBUG): # 各変数の最小値を表示 for i in skewed_feats_over: print(str(min(df[i])) + "\t" + str(i)) return skewed_feats, skewed_feats_over # Yeo-Johnson変換 def trans_yeo_johnson(df, skewed_feats_over): pt = PowerTransformer() #pt.fit(df[skewed_feats_over]) # 変換後のデータで各列を置換 df[skewed_feats_over] = pt.fit_transform(df[skewed_feats_over]) # 各説明変数の歪度を計算 skewed_feats_fixed = df[skewed_feats_over].apply(lambda x: x.skew()).sort_values(ascending = False) return df # Yeo-Johnson逆変換 def inverse_trans_yeo_johnson(df, df2): pt = PowerTransformer() pt.fit_transform(df) return pt.inverse_transform(df2) # 新たな特徴量の追加 def add_new_feature(df): # 特徴量に1部屋あたりの面積を追加 df["FeetPerRoom"] = df["TotalSF"]/df["TotRmsAbvGrd"] return df # [EDA]ランダムフォレスト def do_RandomForestRegressor(df): y_train = df['SalePrice'] X_train = df.drop(['SalePrice'], axis=1) rf = RandomForestRegressor() rf.fit(X_train, y_train) return rf # [EDA]説明変数の関係の可視化 def visualize_target(df, rf): fig = plt.figure(figsize=(20,20)) ranking = np.argsort(-rf.feature_importances_) y_train = df['SalePrice'] X_train = df.drop(['SalePrice'], axis=1) X_train = X_train.iloc[:,ranking[:24]] for i in np.arange(24): # fig.add_subplot(行,列,場所) ax = fig.add_subplot(6,4,i+1) sns.regplot(x=X_train.iloc[:,i], y=y_train) plt.tight_layout() plt.show() fig.savefig("figure3.png") clf_names = ["LinearRegression", "ElasticNet", "Lasso", "Ridge", "LGBMRegressor", "CatBoostRegressor", "XGBRegressor", ] clf_params = ["", "max_iter=1000, tol=0.0001", "max_iter=1000, tol=0.0001", "", "boosting_type='gbdt', num_leaves=31, learning_rate=0.1, n_estimators=100", "logging_level='Silent'", "max_depth=3, learning_rate=0.1, n_estimators=100", ] def sklearn_model(x_train, y_train): start = time.time() models = list() model = None # もっと精度が高いモデル total = 0.0 name = "" for i in range(len(clf_names)): clf = eval("%s(%s)" % (clf_names[i], clf_params[i])) clf.fit(x_train, y_train) score = clf.score(x_train, y_train) print('%s Accuracy:' % clf_names[i], score) models.append(clf) if total <= score: total = score model = clf name = clf_names[i] print(str(time.time() - start)) print('%s was selected' % name) return models, model ### 探索するパラメータ空間 def param(): ret = { 'num_leaves':[15, 20, 25, 31, 35], 'n_estimators':[50, 100, 250, 500, 750], 'boosting_type':['gbdt', 'dart', 'goss', 'rf'], } return ret def sklearn_model2(x_train, y_train): start = time.time() models = list() gscv = GridSearchCV(LGBMRegressor(), param(), cv=4, verbose=0) gscv.fit(x_train, y_train) # 最も良いパラメタ、モデル print(gscv.best_score_) print(gscv.best_params_) # スコアの一覧を取得 gs_result = pd.DataFrame.from_dict(gscv.cv_results_) gs_result.to_csv('gs_result.csv') print("time:" + str(time.time() - start)) return models, gscv def main(df_train, df_test): df_result = pd.DataFrame() df_result['Id'] = df_test['Id'] # 学習データ df_train = del_multicollinearity(df_train) df_train = del_outlier(df_train) df_train = do_imputation(df_train) df_train = del_variable(df_train) df_train = encode_categorical1(df_train) df_train = add_new_feature(df_train) # original data before trans_yeo_johnson y_pre_train = df_train["SalePrice"] skewed_feats, skewed_feats_over = count_skew(df_train) df_train = trans_yeo_johnson(df_train, skewed_feats_over) rf = do_RandomForestRegressor(df_train) #visualize_target(df_train, rf) #----------------------------------------- # テストデータ df_test = del_multicollinearity(df_test) df_test = do_imputation(df_test) df_test = del_variable(df_test) df_test = encode_categorical2(df_test) df_test = add_new_feature(df_test) skewed_feats, skewed_feats_over = count_skew(df_test) df_test = trans_yeo_johnson(df_test, skewed_feats_over) #学習データを目的変数とそれ以外に分ける X_train = df_train.drop("SalePrice", axis=1) X_test = df_test y_train = df_train["SalePrice"] models, model = sklearn_model2(X_train, y_train) # Don't forget to convert the prediction back to non-log scale predictions = model.predict(X_test) #print(yy_train.values.reshape(-1,1)) #print(predictions.reshape(-1, 1)) df_result['SalePrice'] = inverse_trans_yeo_johnson(y_pre_train.values.reshape(-1,1), predictions.reshape(-1, 1)) df_result.to_csv("result.csv",index=False) display(df_result) # CSV読み込み sns.set() df_train = pd.read_csv("train.csv") df_test = pd.read_csv("test.csv") main(df_train, df_test) |

