
株式投資は、予測するものではなくルールに沿って選ぶものです。
その際に、選んだ銘柄が当たろうが外れようが、つねに勝てるルールを作り出す事が大切です。
- 【10回目】機械学習を使った株価予測(関連論文・サイトを調査してみる)
- 【9回目】機械学習で株価予測(年利・勝率向上の分析)
- 【8回目】機械学習で株価予測(交差検証+ROC 曲線とAUCで精度65%)
- 【7回目】機械学習で株価予測(騰落レシオ+株価分割対応で複数銘柄)
- 【6回目】機械学習で株価予測(機械学習で株予測(3点チャージ法の有効性検証)
これは、「株の自動売買で億り人」を夢見て無駄な人生を費やしている一人の中年男の物語です。
前回、Webサイトを見て回った際に
68%を上回るモデルの改良には、為替などの情報や、テキストマイニング等を追加することが必要
と書かれていたので今回はスコア上げに注力してみます。
その中で「ファンダメンタルズ指標」も導入してみました。
テクニカル指標を追加・排除する
説明変数は多けれ多いほどよい
と思ってましたが違うようです。
テクニカル指標「ボリュームレシオ」を自作しましたが、AUCによるスコアは低下していました。
「移動平均乖離率(MA Deviation)」も低下させる要因でした。
更には、日々株価データの「安値」「出来高」なども不要のようです。
加えて「レンジ(高値-安値)」も不要、アノマリーである「曜日」もスコアを落とす要因でした。
アノマリー信者は滅びた方がいい
逆に少しスコアが上がったのは、
「平均方向性指数(ADX)」
「ATR(Average True Range)」
です。
これらはシステムトレードのストラテジー作っているときには通常は使うことはない指標です。
「単純移動平均(Simple Moving Average)」も、利用日数でスコアが変わります。
経験的には25日より長めを導入するとスコアが上りました。
「騰落レシオ」は相変わらずスコアアップに貢献してくれています。
なお、銘柄によって有効なテクニカル指標は異なるようなので代表銘柄の平均を見ながら調整しています。
交差検証を見直す
「K-分割交差検証( K-fold cross-validation)」より、「StratifiedKFold(層状K分割)」を使うほうが精度が高くなりました。
ただし、n_split(データの分割数)は「4」「5」「6」と分割するほど精度が高い・・・という訳でもなく銘柄によって異なるようです。
速度と全体平均を見て「5」を採用しました。
国債金利(ファンダメンタルズ指標)を使う
機械学習は中長期的な指標が好きだと分かったので、ファンダメンタルズ指標もスコアが上がるかと試しました。
ただ、問題は
何の指標が存在し、どうやって20年間分のデータを手に入れるか?
です。
「マクロ経済の「使えるデータ」はどこにあるか?」というサイトに詳細な情報がありました。
- GDP統計
- 為替レート、株価、物価(消費者物価指数、企業物価指数)
- 景気動向関連データ(日銀短観、鉱工業生産指数、機械受注統計調査報告、経済指標カレンダー、景気動向指数、商業動態統計、車種別販売台数)
大量に存在するようです。
まずは国債金利を使ってみます。
10年物国債金利と日経平均株価との関係
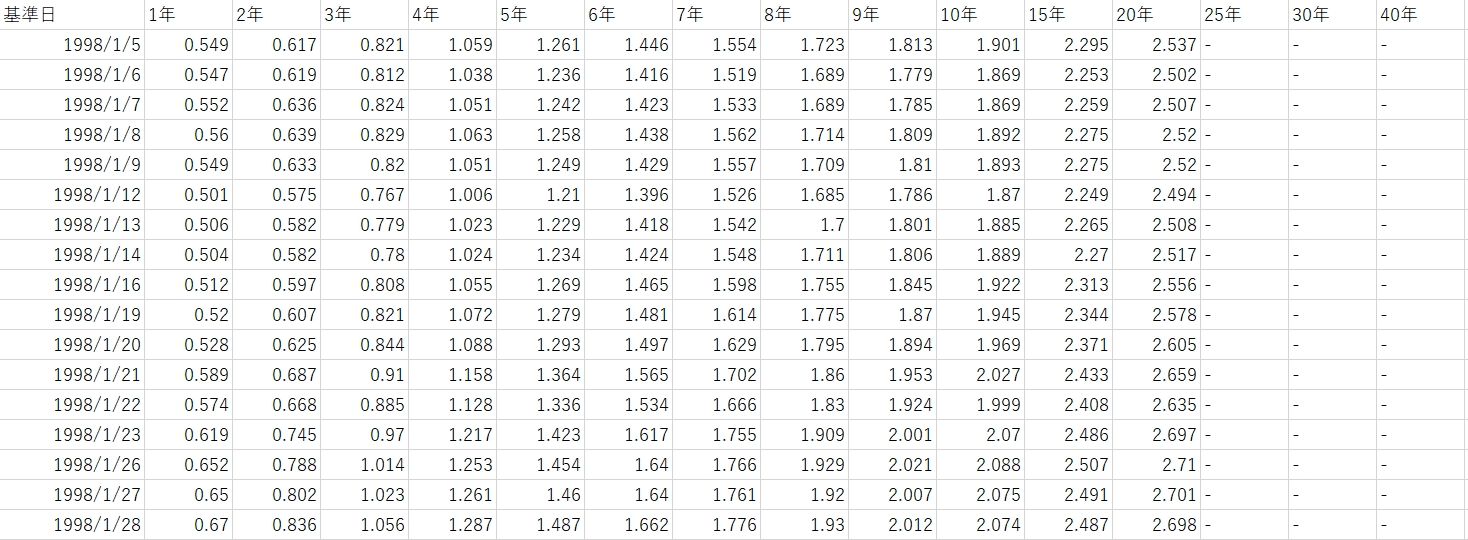
国債金利情報のページに行くとCSVがダウンロード可能です。
Excelで開いて、余計なヘッダを削除、UTF-8に変換、古いデータを削除、日付のフォーマットを和暦から西暦に変換しました。
上記の前処理もPythonで実装すれば常に最新データが自動的に使えますが、有効に作用するか分からなかったので実装してないです。
その上で読み込み方は次のとおりです。
|
1 2 3 4 5 6 7 8 9 10 |
# 国債金利結合 def add_national_bond(df_train): df = pd.read_csv("jgbcm_all.csv", names=["date", "a1","a2","a3","a4","a5","a6","a7","a8","a9","a10","a15","a20","a25","a30","a40"], skiprows=1) tmp = df["date"].str.split('/', expand=True) df["date"] = tmp[0].str.zfill(4) + "/" + tmp[1].str.zfill(2) + "/" + tmp[2].str.zfill(2) df_train = pd.merge(df_train, df, on="date", how="outer") del tmp, df return df_train["a1"] |
10年物国債金利と日経平均株価との関係をあらわすチャートです。
※ 青が「日経平均株価」
※ 赤が「10年物国債金利」
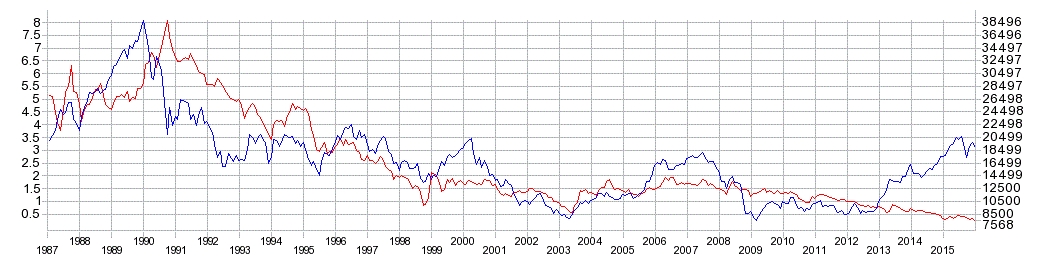
これらを見ると2013年までは相関があります。
ですが、2013年4月に日銀が国債を大量に買い取る異次元緩和と呼ばれる金融政策が実施されました。
これにより株価は大きく上昇し、長期金利は低下して両変数の乖離が大きくなっているのが分かります。
何度か記載してますが、これが過去のストラテジーが使えなくなった原因だと思ってます。
国債金利情報を追加した有効性の検証
赤字が今回の更新内容です。
【資金管理条件】
- 銘柄選定(証券コード毎に時価総額ランキング1位の9銘柄)
- 1回の購入資金 (100万円)
- 投資総額 (1000万円)
- 単利運用
【買いルール】
- 3日後の始値が80%以上の確率で3%以上上がると判断した場合
【手仕舞いルール】
- 3日経過
【機械学習データ】
- [説明変数] 調整後始値、調整後高値、
調整後安値、調整後終値、出来高、単純移動平均、移動平均乖離率、RSI、BB、MACD、VR、騰落レシオ、曜日、ADX、ATR、国債金利 - [目的変数] 翌日の始値から3日後の始値が3%以上上がった・下がった
- [学習モデル] 勾配ブースティング(LightGBM)
- [モデル評価] 5分割StratifiedKFold(層状K分割)
学習結果
9銘柄それぞれのAUC精度は次のとおりです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
1925 Starting cross_validation. Train shape: (1296, 19), test shape: (4917, 18) Full AUC score 0.724535 [0.54399315 0.52360046 0.51032795 ... 0.3985869 0.24929955 0.38859649] 2914 Starting cross_validation. Train shape: (1378, 19), test shape: (5409, 18) Full AUC score 0.713613 [0.19622937 0.19622937 0.25709223 ... 0.16842223 0.34343398 0.51609377] 3407 Starting cross_validation. Train shape: (1510, 19), test shape: (5409, 18) Full AUC score 0.731498 [0.76454171 0.80167935 0.80901525 ... 0.30311889 0.35601339 0.32277417] 4502 Starting cross_validation. Train shape: (946, 19), test shape: (5409, 18) Full AUC score 0.723015 [0.17448845 0.17206605 0.18246768 ... 0.09827502 0.15647025 0.20649272] 5108 Starting cross_validation. Train shape: (1495, 19), test shape: (5409, 18) Full AUC score 0.700892 [0.79987519 0.79987519 0.78486762 ... 0.88962816 0.91778898 0.92915713] 6758 Starting cross_validation. Train shape: (1754, 19), test shape: (5409, 18) Full AUC score 0.713438 [0.42070318 0.34603742 0.27770661 ... 0.20131054 0.22097333 0.29790089] 7203 Starting cross_validation. Train shape: (1201, 19), test shape: (5409, 18) Full AUC score 0.704142 [0.20992748 0.21635634 0.21255263 ... 0.33297241 0.39876979 0.48432061] 8306 Starting cross_validation. Train shape: (1522, 19), test shape: (5409, 18) Full AUC score 0.731400 [0.92500211 0.92500211 0.92500211 ... 0.04537662 0.05596931 0.04690588] 9432 Starting cross_validation. Train shape: (1235, 19), test shape: (5409, 18) Full AUC score 0.698462 [0.21304863 0.21469034 0.20455271 ... 0.20150381 0.32319426 0.36297863] Cross validation - done in 51s |
また、日経平均255銘柄の全データをpd.concatで接続して、計算させた結果は次のとおりです。
|
1 2 3 4 5 6 7 |
..省略 9531 9532 Starting cross_validation. Train shape: (427487, 19), test shape: (5409, 18) Full AUC score 0.711146 [0.60706715 0.62907421 0.59894199 ... 0.38131182 0.45600329 0.45200169] Cross validation - done in 83s |
ようするに、
AUC = 0.70~0.73
となり0.70を超えました。
バックテスト結果
Protraを使ったバックテストの見た目は過去の結果と大差が無いので省略します。
勝率、プロフィットファクターは上がってますが、フォワードテストがボロボロなのは変化ありません。
まとめ
今回は、銘柄毎に最適な学習モデルを作成しています。
これが全銘柄一括の学習モデルにするとどうなるのかが気になります。
が、「K-分割交差検証」の中で検証用データも一緒に計算してしまうサンプルしか見つからず実力不足で方法が分かりません。
具体的には、交差検証で作成した学習モデルの保存・ロードした上で、各銘柄に対し共通の学習済モデルを適用して利益計算がやりたいです。

