
前回、機械学習で解いた学習モデルが勝率50.48%、プロフィットファクター1.15、平均年利5.91%、最大損失年利-37.23%という事が分かりました。
今回は、現時点で考えている特徴量を追加して成績が改善するか確認してみます。
株式投資の種類と手法をまとめました。
私は利益は出てませんが、たまに株式投資を教える事があるため用です。
- 【5回目】機械学習で株価予測(Protraを使ったバックテスト解決編)
- 【4回目】機械学習で株価予測(Backtraderでバックテスト調査)
- 【3回目】機械学習で株価予測(Pythonのバックテストライブラリ調査)
- 【2回目】機械学習で株価予測(TA-LibとLightGBMを使った学習モデル構築)
- 【1回目】機械学習で株価予測(Two SigmaのKaggleコンペを確認)
今回はテクニカル指標(ボリュームレシオ)、ストラテジー(3点チャージ法)を特徴量として追加してみます。
「三点チャージ法」を指標として追加する
テーブルデータのコンペにおいて特徴量の作成は非常に重要な要素で、良い特徴量が作れたかどうかで順位が決まることがほとんどです。
複数の変数を組み合わせることで、変数同士の相互作用を表現する特徴量を作成できるからです。
たとえば、
「物件の面積」と「部屋数」という変数を割り算して、「1部屋当たりの面積」という新特徴量を作成する
ことで、精度が上がったりします。
これって不思議なんだよね。
このような特徴を自動的に見つけるのが機械学習なんじゃないのかな?局所解に陥らないようになるから良くなるの??
まあ理由はさておき、それならば・・・・みんな大好き「三点チャージ法」!
手法は次の通りです。
- 1) 終値と26日移動平均線の乖離率が-15%以下
- 2) VR:ボリュームレシオ(25日)が70以下
- 3) RSI(14日)が25以下
これを実装して、特徴量として追加します。
・・・・
ボリュームレシオがTa-libに存在しない!

ProtraのTIlibを使えないと、ここから実装する必要があるのか・・・・
先が思いやられる・・・な。
VR(ボリュームレシオ)の計算方法
Protraの公式マニュアルを見てみると、次のような計算になっていました。
U=期間内の株価上昇日の出来高合計
D=期間内の株価下落日の出来高合計
S=期間内の株価変わらずの日の出来高合計
とすると、
VR[A]=(U+S/2)÷(D+S/2)×100
※ 指標値は0以上で上限はない。500~1000近くまで上がるときもある。上昇と下落が均衡しているとき(U=D)は100
VR[B]=(U+S/2)÷(U+D+S)×100
※ 指標値は0~100の間に収まる。上下均衡しているときは50
和光VR=(U-D-S)÷(U+D+S)×100
指標値は-100~100の間に収まる。上下均衡していて株価の変わらずの日が無ければ0
となる。
なお、「3点チャージ投資法」ではVR[A]を用いているそうです。
ググってみると、Pythonのテクニカル指標ライブラリ「Ta-lib(タリブ)」以外にも、「pyti(パイタイ)」「ta」「stockstats」などが見つかりました。
また、脱talibで自作しようとしている人もいました。
一応、ボリュームレシオの実装らしいものが見つかりましたが、計算式が異なるので、やっぱり自作します。
Pythonによるボリュームレシオ実装方法
そもそもpandas は 2008 年頃から金融の現場で開発され始めたデータツールです。
そのため、金融・経済データの実践的な分析ツールとして強力な機能をいくつも備えています。
株価上昇率を求めるには、前日の終値との差分が必要です。
差分にはpandasのdiff()を使います。
|
1 2 3 4 5 6 |
df = pd.DataFrame({'a': range(1, 6), 'b': [x**2 for x in range(1, 6)], 'c': [x**3 for x in range(1, 6)]}) print(df) print(df['a'].diff()) |
デフォルトでは1行前の値との差分が算出されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
a b c 0 1 1 1 1 2 4 8 2 3 9 27 3 4 16 64 4 5 25 125 0 NaN 1 1.0 2 1.0 3 1.0 4 1.0 Name: a, dtype: float64 |
また、窓関数(ある有限区間以外で0となる関数)には、pandasのrolling()を使います。
作成したボリュームレシオ関数は次のとおりです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
def vr(df, window=26, type=1): """ Volume Ratio (VR) Formula: VR[A] = SUM(av + cv/2, n) / SUM(bv + cv/2, n) * 100 VR[B] = SUM(av + cv/2, n) / SUM(av + bv + cv, n) * 100 Wako VR = SUM(av - bv - cv, n) / SUM(av + bv + cv, n) * 100 av = volume if close > pre_close else 0 bv = volume if close < pre_close else 0 cv = volume if close = pre_close else 0 """ df['av'] = np.where(df['close'].diff() > 0, df['volume'], 0) avs = df['av'].rolling(window=window, center=False).sum() df['bv'] = np.where(df['close'].diff() < 0, df['volume'], 0) bvs = df['bv'].rolling(window=window, center=False).sum() df['cv'] = np.where(df['close'].diff() == 0, df['volume'], 0) cvs = df['cv'].rolling(window=window, center=False).sum() df.drop(['av', 'bv', 'cv'], inplace=True, axis=1) if type == 1: # VR[A] vr = (avs + cvs / 2) / (bvs + cvs / 2) * 100 elif type == 2: # VR[B] vr = (avs + cvs / 2) / (avs + bvs + cvs) * 100 else: # Wako VR vr = (avs - bvs - cvs) / (avs + bvs + cvs) * 100 return vr |
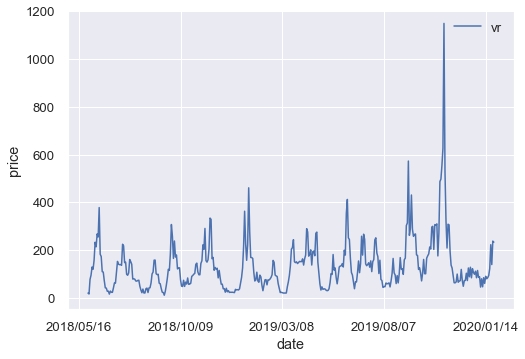
Protraと同じ結果となったので、正しく動いているかと思います。
Pythonによる3点チャージの実装方法
こちらは簡単です。一行です。
|
1 2 3 4 5 6 7 8 9 |
def three_charge(df): """ 3点チャージ法 Formula: 1) [RSI(14)]が[25]より[小さい] 2) [移動平均乖離率(15)]が[-18]より[小さい] 3) [VR(25)]が[70]より[小さい] """ return (25 > df['rsi14']) & (-18 > df['diffma15']) & (70 > df['vr']) |
ボリュームレシオ追加の学習モデル有効性検証
過去のストラテジーテンプレートを使ったので次の通りです。
【資金管理条件】
- 1) 銘柄選定(トヨタ)
- 2) 1回の購入資金 (100万円)
- 3) 投資総額 (1000万円)
- 4) 単利利用
【買いルール】
- 1) LightGBMがSMA、RSI、BB、MACD、VR、三点チャージ法から自動買い選定
【手仕舞いルール】
- 1) 3日経過
これを引数なしのLightGBMで解いてみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
X_train:(2727, 27) y_train:(2727,) X_valid:(682, 27) y_valid:(682,) LGBMClassifier Accuracy: 1.0 Time = 377.6002974510193 Total Time = 377.6002974510193 LGBMClassifier was selected total profit = 5851.0 [[202 144] [149 187]] Model[LGBMClassifier] Testing Accuracy = "0.5703812316715543 !" |
デフォルトのパラメータで訓練データの精度(Accuracy)がほぼ100%で分類できてしまう状態になりました。
当然過学習を起こしている状態で、検証データ・テストデータに対しては精度が57%となってしまいました。
そして「feature_importances_」のデータ結果です。

決定木が重要な特徴と判断したデータの上位にボリュームレシオが入っています。
この特徴量は作ってよかった。
因みに三点ジャージ法は、トヨタのような優良株ではそもそもシグナルが出ていないようなので役に立っていません。
バックテスト結果
Protraを使ったバックテスト結果は次のようになりました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
株価データ: 日足 銘柄リスト: トヨタ 1998/01/05~2020/01/24における成績です。 ---------------------------------------- 全トレード数 421 勝ちトレード数(勝率) 329(78.15%) 負けトレード数(負率) 92(21.85%) 全トレード平均利率 2.27% 勝ちトレード平均利率 3.43% 負けトレード平均損率 -1.85% 勝ちトレード最大利率 18.33% 負けトレード最大損率 -7.58% 全トレード平均期間 4.45 勝ちトレード平均期間 4.52 負けトレード平均期間 4.18 ---------------------------------------- 必要資金 ¥980,000 最大ポジション(簿価) ¥1,017,000 最大ポジション(時価) ¥1,182,000 純利益 ¥7,002,100 勝ちトレード総利益 ¥8,273,800 負けトレード総損失 -¥1,271,700 全トレード平均利益 ¥16,632 勝ちトレード平均利益 ¥25,148 負けトレード平均損失 -¥13,823 勝ちトレード最大利益 ¥171,000 負けトレード最大損失 -¥74,000 プロフィットファクター 6.51 最大ドローダウン(簿価) -¥236,000 最大ドローダウン(時価) -¥248,500 ---------------------------------------- 現在進行中のトレード数 0 ---------------------------------------- 平均年利 34.02% 平均年利(直近5年) 29.41% 最大連勝 34回 最大連敗 5回 ---------------------------------------- [年度別レポート] 年度 取引回数 運用損益 年利 勝率 PF 最大DD 2020年 1回 ¥10,100円 1.03% 100.00% ∞倍 0.00% 2019年 21回 ¥357,300円 36.46% 100.00% ∞倍 0.00% 2018年 27回 ¥284,800円 29.06% 74.07% 4.96倍 -3.84% 2017年 20回 ¥282,800円 28.86% 95.00% 36.35倍 -1.12% 2016年 32回 ¥506,200円 51.65% 84.38% 16.58倍 -3.84% 2015年 32回 ¥497,600円 50.78% 81.25% 19.43倍 -1.20% 2014年 25回 ¥426,600円 43.53% 96.00% 100.21倍 -0.69% 2013年 33回 ¥716,000円 73.06% 78.79% 12.55倍 -2.72% 2012年 17回 ¥756,500円 77.19% 100.00% ∞倍 0.00% 2011年 13回 ¥331,000円 33.78% 84.62% 19.39倍 -1.33% 2010年 12回 ¥357,200円 36.45% 91.67% 80.38倍 -0.46% 2009年 22回 ¥940,500円 95.97% 95.45% 19.09倍 -6.52% 2008年 32回 ¥772,000円 78.78% 81.25% 7.89倍 -6.85% 2007年 26回 ¥349,000円 35.61% 88.46% 6.06倍 -4.51% 2006年 26回 ¥282,000円 28.78% 80.77% 3.94倍 -5.45% 2005年 18回 -¥24,000円 -2.45% 38.89% 0.81倍 -4.90% 2004年 11回 -¥14,000円 -1.43% 54.55% 0.84倍 -4.05% 2003年 13回 ¥136,500円 13.93% 69.23% 5.79倍 -3.18% 2002年 4回 ¥48,000円 4.90% 75.00% 6.33倍 -0.98% 2001年 15回 -¥39,000円 -3.98% 46.67% 0.77倍 -6.13% 2000年 21回 ¥25,000円 2.55% 47.62% 1.09倍 -7.58% |
利益曲線は次の通りです。
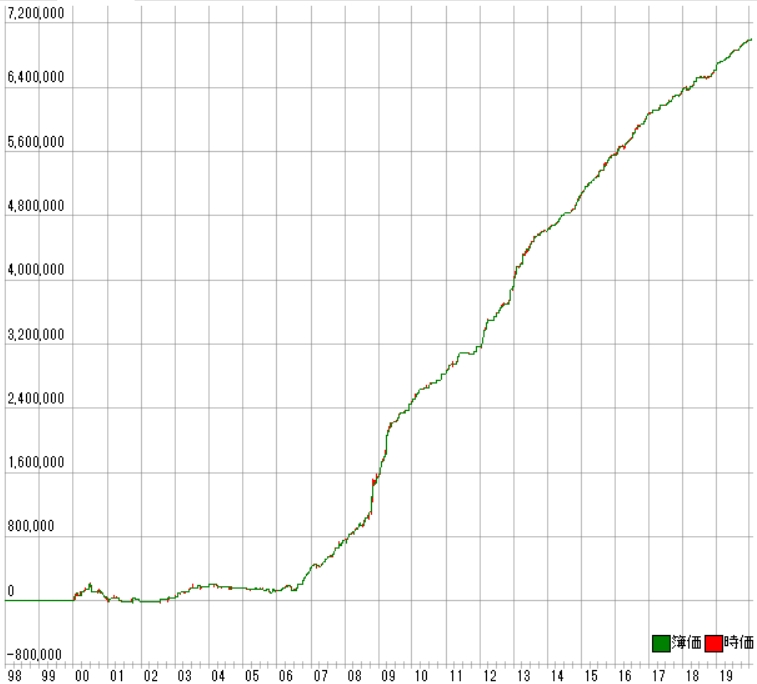
すごい結果になりました!!!
勝率8割近くでプロフィットファクターが7近くあります。
さらに年利は30%を超えています。
さっそく「聖杯」が見つかりました!
が、このストラテジーは今までの経験上、未来データを使った「呂布」なのか???

が・・・・未来データが入る実装ミスはありませんでした。
このストラテジーが何者なのか簡単に考察してみます。
この学習モデルの構築には「2006/02/20~2020/01/24」までの結果を利用しています。
このため2000年~2006年の株価は学習モデルが一切知らない相場となります。
その部分だけ見てみます。
|
1 2 3 4 5 6 |
2005年 21回 ¥120,000円 11.22% 61.90% 2.33倍 -3.05% 2004年 21回 ¥100,000円 9.35% 66.67% 2.25倍 -2.75% 2003年 16回 ¥110,000円 10.29% 68.75% 2.93倍 -2.73% 2002年 9回 -¥2,000円 -0.19% 33.33% 0.98倍 -4.87% 2001年 19回 ¥26,000円 2.43% 57.89% 1.13倍 -6.13% 2000年 23回 -¥81,000円 -7.57% 43.48% 0.71倍 -5.19% |
負ける年もあり勝率は高くありません。
確かに利益曲線も寝ています。
ようするに
過学習(オーバフィッティング)が発生しています!
これがオーバーフィッティングというヤツかぁ・・・・・。
初めて体験しました。
やっぱり過去のデータから未来は予測できない・・・・という事なのか?
厄介な問題にぶつかりました・・・。
なお、作成された「model.pickle」は150MB近くあります。今までは40MB程度でしたがサイズが大きいです・・・・。
本気で機械学習で学習モデルを作ってシステムトレードするならハードディスクの増設が必要そうです。
まとめ
試そうと思っているストラテジーは大量にあります。
ですが、その前にオーバーフィッティングをどうにかしないとリアルでは勝てなそうです。
すでに与える特徴量が多すぎるのか・・・。
ただ、Protraの結果を見る限り期待通りにストラテジーが作られている事が分かったので、安心しました。
「Protra+機械学習」の手法は、(オーバーフィッティングはしますが)思った以上に高い年利のストラテジーが作成できるようです。
ソースコード
学習させるときは、 read_csv の引数はskiprows=2000(2006/02/20~現在まで)、学習済データで予測させるときはskiprows=0に変更して出力しました。
まずはライブラリです。
「nehori」という下に「tilib.py」というファイルを置きます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
import numpy as np import pandas as pd # グラフ出力 def display_chart(data, x): sns.set(font_scale = 1.2) fig = plt.figure() for i in range(len(data)): plt.plot(x, data[i][0], label=data[i][1]) plt.xticks(range(0, len(x), 100), x[::100]) plt.xlabel('date') plt.ylabel('price') plt.legend() plt.show() # ファイルに保存 fig.savefig("img.png") def vr(df, window=26, type=1): """ Volume Ratio (VR) Formula: VR[A] = SUM(av + cv/2, n) / SUM(bv + cv/2, n) * 100 VR[B] = SUM(av + cv/2, n) / SUM(av + bv + cv, n) * 100 Wako VR = SUM(av - bv - cv, n) / SUM(av + bv + cv, n) * 100 av = volume if close > pre_close else 0 bv = volume if close < pre_close else 0 cv = volume if close = pre_close else 0 """ df['av'] = np.where(df['close'].diff() > 0, df['volume'], 0) avs = df['av'].rolling(window=window, center=False).sum() df['bv'] = np.where(df['close'].diff() < 0, df['volume'], 0) bvs = df['bv'].rolling(window=window, center=False).sum() df['cv'] = np.where(df['close'].diff() == 0, df['volume'], 0) cvs = df['cv'].rolling(window=window, center=False).sum() df.drop(['av', 'bv', 'cv'], inplace=True, axis=1) if type == 1: # VR[A] vr = (avs + cvs / 2) / (bvs + cvs / 2) * 100 elif type == 2: # VR[B] vr = (avs + cvs / 2) / (avs + bvs + cvs) * 100 else: # Wako VR vr = (avs - bvs - cvs) / (avs + bvs + cvs) * 100 return vr def three_charge(df): """ 3点チャージ法 Formula: 1) [RSI(14)]が[25]より[小さい] 2) [移動平均乖離率(15)]が[-18]より[小さい] 3) [VR(25)]が[70]より[小さい] """ return (25 > df['rsi14']) & (-18 > df['diffma15']) & (70 > df['vr']) |
そして、上記ライブラリを読み込んで特徴量を作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 |
import os import time import talib import pickle import numpy as np import pandas as pd import seaborn as sns import pandas_profiling as pdp import matplotlib.pyplot as plt from xgboost import XGBClassifier from lightgbm import LGBMClassifier from catboost import CatBoostClassifier from sklearn.metrics import confusion_matrix from sklearn.model_selection import train_test_split from nehori import tilib # 学習用データ、検証用データの割り当て def build_train_valid_data(df, target, train_size = 0.8): # 答えの削除 y_train = df[target] X_train = df.drop([target], axis = 1) # 80% を学習用データ X_train, X_valid, y_train, y_valid = train_test_split(X_train, y_train, train_size = train_size) # 作成した行列出力 print("X_train:{}".format(X_train.shape)) print("y_train:{}".format(y_train.shape)) print("X_valid:{}".format(X_valid.shape)) print("y_valid:{}".format(y_valid.shape)) return X_train, X_valid, y_train, y_valid # 概要出力 def display_overview(df): # それぞれのデータのサイズを確認 print("The size of df is : "+str(df.shape)) # 列名を表示 print(df.columns) # 表の一部分表示 display(df.head(-10)) # 各列のデータの型を表示 #print(df.dtypes.sort_values()) clf_names = [ ["LGBMClassifier",""], # ["CatBoostClassifier","logging_level='Silent'"], # ["XGBClassifier",""], ] # 学習モデル構築 def sklearn_model(X_train, y_train): total_start = time.time() models = {} total = 0.0 name = "" for i in range(len(clf_names)): start = time.time() # インスタンス化 clf = eval("%s(%s)" % (clf_names[i][0], clf_names[i][1])) clf.fit(X_train, y_train) score = clf.score(X_train, y_train) print('%s Accuracy:' % clf_names[i][0], score) print(' Time = %s' % str(time.time() - start)) models[clf_names[i][0]] = clf if total <= score: total = score name = clf_names[i][0] print('Total Time = %s' % str(time.time() - total_start)) print('%s was selected' % name) return models # テクニカル指標 def add_new_features(df): # 単純移動平均(Simple Moving Average) close = df['close'] df['sma3'] = talib.SMA(close, timeperiod=3) df['sma5'] = talib.SMA(close, timeperiod=5) df['sma15'] = talib.SMA(close, timeperiod=15) df['sma25'] = talib.SMA(close, timeperiod=25) df['sma50'] = talib.SMA(close, timeperiod=50) df['sma75'] = talib.SMA(close, timeperiod=75) df['sma100'] = talib.SMA(close, timeperiod=100) #display_chart( [[df['sma5'],"sma5"],[df['sma25'],"sma25"],[df['sma50'],"sma50"], # [df['sma75'],"sma75"],[df['sma100'],"sma100"]], df['date']) # ボリンジャーバンド(Bollinger Bands) df['upper1'], middle, df['lower1'] = talib.BBANDS(close, timeperiod=25, nbdevup=1, nbdevdn=1, matype=0) df['upper2'], middle, df['lower2'] = talib.BBANDS(close, timeperiod=25, nbdevup=2, nbdevdn=2, matype=0) df['upper3'], middle, df['lower3'] = talib.BBANDS(close, timeperiod=25, nbdevup=3, nbdevdn=3, matype=0) #display_chart( [[df['upper1'],"upper1"],[df['lower1'],"lower1"],[df['upper2'],"upper2"], # [df['lower2'],"lower2"],[df['upper3'],"upper3"],[df['upper1'],"lower3"]], df['date']) # MACD - Moving Average Convergence/Divergence df['macd'], df['macdsignal'], df['macdhist'] = talib.MACD(close, fastperiod=12, slowperiod=26, signalperiod=9) #display_chart( [[df['macd'],"macd"],[df['macdsignal'],"macdsignal"],[df['macdhist'],"macdhist"]], df['date']) # RSI - Relative Strength Index df['rsi9'] = talib.RSI(close, timeperiod=9) df['rsi14'] = talib.RSI(close, timeperiod=14) #display_chart( [[df['rsi9'],"rsi9"],[df['rsi14'],"rsi14"]], df['date']) # 移動平均乖離率(MA Deviation) df['diffma15'] = 100 * (close - df['sma15']) / df['sma15'] # VR - Volume Ratio df['vr'] = tilib.vr(df, 25) #display_chart( [[df['vr'],"vr"]], df['date']) df['charge3'] = tilib.three_charge(df) return df # 利益計算 def cal_profit(y, y_pred): # 予測 y_pred = np.where(y_pred < 10, 0, 1) csv_df = pd.DataFrame() sum = 0 for i in range(len(y_pred)): if (y_pred[i]): csv_df = csv_df.append([y[i]], ignore_index=True) sum += y[i] else: csv_df = csv_df.append([0], ignore_index=True) print("total profit = " + str(sum)) csv_df.to_csv("profit.csv", index = False) # 正解率確認 def output_accuracy(models, X, y): best_model = None best_name = "" total = 0.0 for name, model in models.items(): y_pred = model.predict(X) #print(y_pred) #print("The size of df is : "+str(y_pred.shape)) #print("--------------------------") #print(y.ravel()) cal_profit(y.ravel(), y_pred) #print("The size of df is : "+str(y.shape)) y = np.where(y < 0, 0, 1) y_pred = np.where(y_pred < 0, 0, 1) cm = confusion_matrix(y, y_pred) print(cm) # extracting TN, FP, FN, TP TN, FP, FN, TP = confusion_matrix(y, y_pred).ravel() score = (TP + TN) / (TP + TN + FN + FP) # Accuracy を計算する print('Model[{}] Testing Accuracy = "{} !"'.format(name, score)) print() # feature importances fi = model.feature_importances_ fi_df = pd.DataFrame({'feature': list(X.columns), 'feature importance': fi[:]}).sort_values('feature importance', ascending = False) fi_df sns.barplot(fi_df['feature importance'],fi_df['feature']) plt.title("imporance in the Light GBM Model") if total <= score: best_model = model best_name = name total = score print()# Print a new line print('%s was selected' % best_name) return best_model def load_model(): clf = None file = 'model.pickle' if os.path.exists(file): with open(file, mode='rb') as fp: clf = pickle.load(fp) return clf def save_model(clf): with open('model.pickle', mode='wb') as fp: pickle.dump(clf, fp, protocol=2) # Protraファイルの作成 def create_protra_dataset(code, date, y): # 利益が高いと判定したものだけ残す y = np.where(y < 100, False, True) s = "def IsBUYDATE\n" s += " if ((int)Code == " + code + ")\n" s += " if ( \\\n" for i in range(len(y)): if(y[i]): (year, month, day) = date[i].split('/') s += "(Year == " + str(int(year)) + " && Month == " + str(int(month)) + " && Day == " + str(int(day)) + ") || \\\n" s += " (Year == 3000))\n" s += " return 1\n" s += " else\n" s += " return 0\n" s += " end\n" s += " end\n" s += "end\n" with open("LightGBM.pt", mode='w') as f: f.write(s) def main(): df_train = pd.read_csv("7203.csv", skiprows=2000, names=("date", "open", "high", "low", "close", "volume")) # 予測値(3日後の始値の上昇値) df_train['target'] = df_train['open'].shift(-3) - df_train['open'].shift(-1) # 曜日追加 df_train['day'] = pd.to_datetime(df_train['date']).dt.dayofweek # 新特徴データ df_train = add_new_features(df_train) # 欠損値を列の1つ手前の値で埋める df_train = df_train.fillna(method='ffill') model = load_model() if (not model): # 概要出力 display_overview(df_train) # dateは不要 df_train = df_train.drop("date", axis=1) # データ分割 X_train, X_valid, y_train, y_valid = build_train_valid_data(df_train, 'target', 0.8) # 学習モデル構築 models = sklearn_model(X_train, y_train) # 正解率確認 model = output_accuracy(models, X_valid, y_valid) save_model(model) else: # 概要出力 display_overview(df_train) #profile = pdp.ProfileReport(df_train) #profile.to_file("myoutputfile.html") # dateは不要 date = df_train["date"] df_train = df_train.drop("date", axis=1) df_train = df_train.drop("target", axis=1) y_pred = model.predict(df_train) print(y_pred) create_protra_dataset("7203", date, y_pred) if __name__ == '__main__': main() |

