
日本では5つの要因でサラリーマンの給料は上りません。
- ① 労働組合の弱体化
- ② 非正規雇用者の増加
- ③ 少子高齢化の影響
- ④ 内部留保を貯め込んで賃金を上げない経営者
- ⑤ 規制緩和の遅れがもたらした賃金低迷
このため自分で稼ぐしかありません。
アフィリエイト等で稼いでいた5年前と比べ現在の副収入は「ほぼゼロ」です。
これは、「株の自動売買」を夢見て無駄な人生を費やしている一人の男の物語です。
- 【7回目】機械学習で株価予測(騰落レシオ+株価分割対応で複数銘柄)
- 【6回目】機械学習で株価予測(機械学習で株予測(3点チャージ法の有効性検証)
- 【5回目】機械学習で株価予測(Protraを使ったバックテスト解決編)
- 【4回目】機械学習で株価予測(Backtraderでバックテスト調査)
- 【3回目】機械学習で株価予測(Pythonのバックテストライブラリ調査)
- 【2回目】機械学習で株価予測(TA-LibとLightGBMを使った学習モデル構築)
- 【1回目】機械学習で株価予測(Two SigmaのKaggleコンペを確認)
オーバーフィッティングが発生する理由
「オーバーフィッティング(カーブフィッティング)」とはシステムを過去の相場にぴったり合うように過剰に最適化してしまうことです。
- 1 バックテスト用過去データの対象期間が短すぎる場合
- 2 採用しているテクニカル指標が多過ぎる場合
- 3 採用しているテクニカル指標が複雑過ぎる場合
- 4 機械的に検出したパラメータセットをそのまま採用してしまう場合
1以外は機械学習に関わります。
特に、テクニカル指標の利用方法は複雑で、最適化しまくりな手法です・・・。
理解できないような指標を採用し最適化した場合はこの検証が出来ないわけですので後々システムが破綻する可能性が大きくなるかと思います。
変数を確認して突拍子もない数値で構成されたパラの組み合わせであった場合はオーバーフィッティングになる可能性が大きいかと思います。
・・・・機械学習は全然駄目じゃん。
モデルの評価
「train_test_split関数」しか知りませんでしたが、過学習を回避する手法は多くあります。
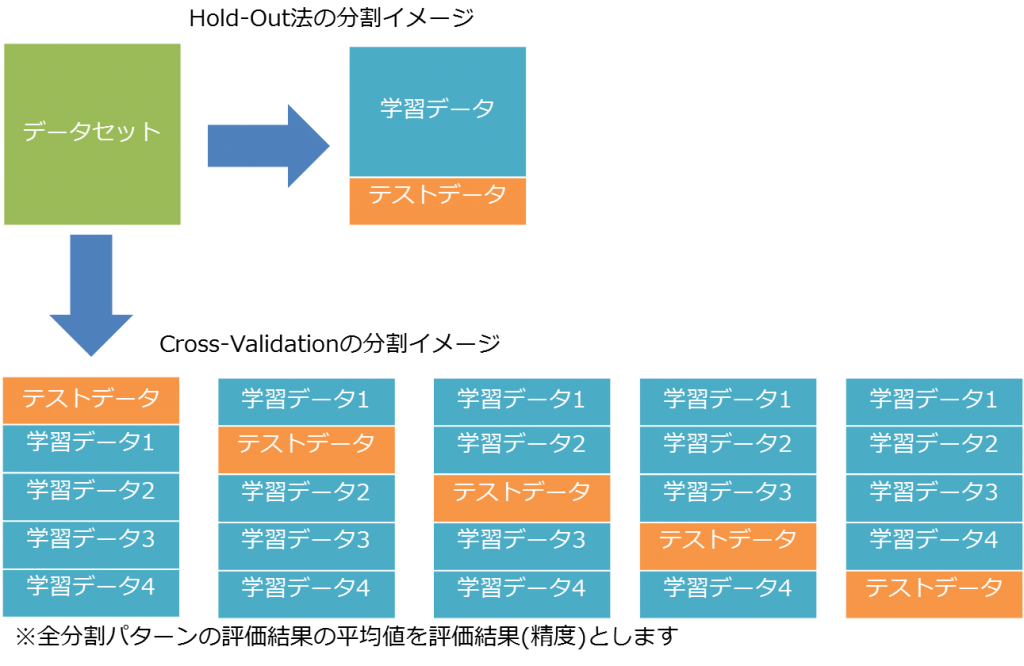
ホールドアウト検証 (Hold-out Validation)
train_test_split関数は、データをランダムに分割するのでscoreは偶然に左右されやすいです。
|
1 2 3 4 5 6 7 8 |
# 訓練セットとテストセットに分割 X_train, X_test, y_train, y_test = train_test_split(X,y,random_state=0) # モデルのインスタンスを生成し、訓練データで学習 logreg = LogisticRegression().fit(X_train,y_train) # テストセットでモデルを評価 print(logreg.score(X_test,y_test)) #=>0.868421052632 |
ホールドアウト検証法はデータを分割していますが一回だけの試行なので偏りが含まれる余地が比較的あります。
交差検証
決定木は、max_depthパラメータを大きくすればするほど精度が上がりますが、汎化性能が下がっていきます。
このため、交差検証(cross-validation)を使って、過学習が起こっていないかチェックすることが重要です。
交差検証は、全てのデータを訓練に1回用いて複数の検証結果をまとめることで、偶然性を軽減します。
sklearnでは、KFold、StratifiedKFold、ShuffleSplitがサポートされています。
KFold(K-分割交差検証)
最も一般的な交差検証として、k分割交差検証(k-fold cross-validation)があります。
これは、データをk分割し、それらを用いる検証法です。
|
1 2 3 4 5 |
from sklearn.model_selection import KFold kf = KFold(n_splits=5) for train_index, test_index in kf.split(x, y): print("train_index:", train_index, "test_index:", test_index) |
kは5 ~ 10が一般的です。
分割数が多くなるほど時間がかかります。
StratifiedKFold(層状K分割)
各分割内でのクラスの比率が全体の比率と同じになるように分割します。
cross_val_score() はパラメータ cv を用いることで分割方法を指定することができます。
|
1 2 3 4 5 |
from sklearn.model_selection import StratifiedKFold skf = StratifiedKFold(n_splits=2) for train_index, test_index in skf.split(x, y): print("train_index:", train_index, "test_index:", test_index) |
一般的には,回帰には単純な k 分割交差検証、クラス分類には層化 k 分割交差検証が用いられます。
ShuffleSplit(ランダム置換相互検証)
シャッフル分割交差検証は、テストデータ数、訓練データ数、繰り返し数を指定して検証する手法です。
|
1 2 3 4 5 |
from sklearn.model_selection import ShuffleSplit ss = ShuffleSplit(n_splits=3, test_size=0.25, random_state=0) for train_index, test_index in ss.split(x, y): print("train_index:", train_index, "test_index:", test_index) |
また、test_size + train_size < 1.0を指定することでデータの一部だけを用いた検証をおこなうことができます(サブサンプリング)。 これは大規模データで効率的に検証を行うときに有効です。
1つ抜き交差検証(leave-one-out)
テストデータとして1データを用い、訓練データとして他の全てのデータを用いる手法です。
大規模データにおいては時間がかかりますが、小規模データに関して短時間で検証ができます。
評価指標
評価指標とは、学習させたモデルの性能やその予測値の良し悪しを測る指標です。
ニ値分類のタスクに対する評価指標は大きく分けて、F-1 scoreやMCCのような混合行列を元にしたものと、loglossやAUCのように確率値をもとにした二種類があります。
混同行列(confusion matrix)
混同行列(confusion matrix)とは、機械学習モデルや検査等の性能を示すための方法です。
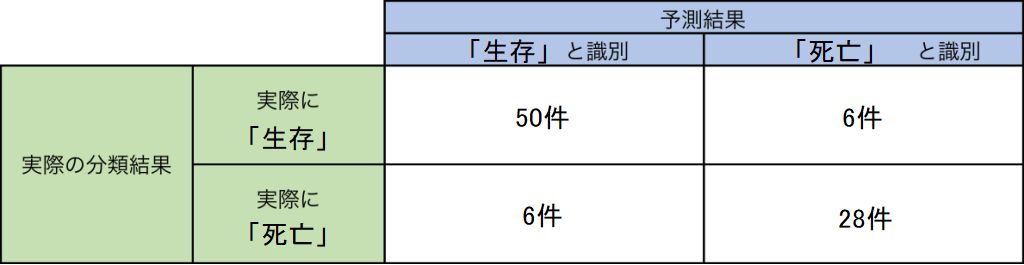
2×2の表に、実際のラベル(生存・死亡、など)と機械学習による予測結果の組み合わせごとに、その数を書き込むことで作成されます。
ROC 曲線とAUC
混合行列は、クラスに偏りがある場合、機能しなくなるという問題があります。
ROC曲線(Receiver Operating Characteristics Curve)やAUC(Area Under the receiver operating characteristics curve)は、 この問題を回避する目的で使われる指標です。
ROC は推測曲線と呼ばれ縦軸にTPR(True Positive Rate)、横軸にFPR(False Positive Rate) の割合をプロットしたものです。 AUC(Area Under the Curve) はその曲線の下部分の面のことで、AUC の面積が大きいほど一般的に機械学習の性能が良い事を意味します。
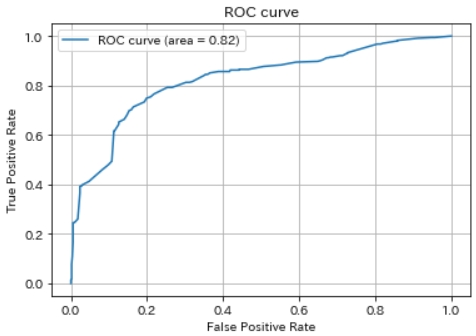
面積が大きいということはすなわち機械学習モデルがNegative と推測すべきものを間違えてPositive と推測している傾向が少なく、Positive と推測すべきものをしっかりとPositive と推測できている状態です。
ROC曲線下面積(AUC: area under the curve)は、0.5 – 1.0の値をとります。
一般的には、AUCの値に基づいて予測能・診断能を次の様に判断します。
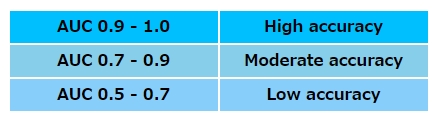
KFoldとAUCを利用したサンプル実装
ROC-AUCの場合、直接その値を算出する関数roc_auc_score()があるのでそちらを使ったほうが便利です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
import pandas as pd import numpy as np from sklearn.metrics import roc_auc_score from sklearn.model_selection import KFold from lightgbm import LGBMClassifier import gc data = pd.DataFrame({'date' : ['1/1','1/2','1/3','1/4','1/5','1/6','1/7','1/8','1/9','1/10','1/11','1/12'], 'close' : [300,100,400,500,600,700,400,500,600,100,400,500], 'volume' : [10, 13, 16, 30, 33, 66,10, 13, 16,10, 13, 16], 'TARGET' : [1, 0, 1,0, 1, 0, 1, 0, 1,0, 1, 0] }, ) test = pd.DataFrame({'date' : ['1/1','1/2','1/3','1/4','1/5','1/6','1/7','1/8','1/9','1/10','1/11','1/12'], 'close' : [300,100,400,500,600,700,400,500,600,100,400,500], 'volume' : [10, 13, 16, 30, 33, 66,10, 13, 16,10, 13, 16] } ) y = data['TARGET'] del data['TARGET'] excluded_feats = ['date'] features = [f_ for f_ in data.columns if f_ not in excluded_feats] # Modeling folds = KFold(n_splits=5, shuffle=True, random_state=123) oof_preds = np.zeros(data.shape[0]) sub_preds = np.zeros(test.shape[0]) for n_fold, (trn_idx, val_idx) in enumerate(folds.split(data)): trn_x, trn_y = data[features].iloc[trn_idx], y.iloc[trn_idx] val_x, val_y = data[features].iloc[val_idx], y.iloc[val_idx] clf = LGBMClassifier() clf.fit(trn_x, trn_y, eval_set= [(trn_x, trn_y), (val_x, val_y)], eval_metric='auc', verbose=250, early_stopping_rounds=150) oof_preds[val_idx] = clf.predict_proba(val_x, num_iteration=clf.best_iteration_)[:, 1] sub_preds += clf.predict_proba(test[features], num_iteration=clf.best_iteration_)[:, 1] / folds.n_splits print('Fold %2d AUC : %.6f' % (n_fold + 1, roc_auc_score(val_y, oof_preds[val_idx]))) del clf, trn_x, trn_y, val_x, val_y gc.collect() print('Full AUC score %.6f' % roc_auc_score(y, oof_preds)) test['TARGET'] = sub_preds test[['date', 'TARGET']].to_csv('submission.csv', index=False, float_format='%.8f') |
「clf.fit」の引数「early stopping 」は、過学習を防ぐ学習方法として LightGBMだけでなく DeepNeuralNetwork でもよく使われる手法です。
学習データだけではなくテストデータの Validation Error もモニタリングし、学習エラー(bias)と検証エラー(variance)のトレードオフが起きるところで学習を早期に終了させ、過学習を防ぎます。
|
1 2 3 4 5 6 7 8 |
2 1 11 0 Name: TARGET, dtype: int64 Training until validation scores don't improve for 150 rounds Did not meet early stopping. Best iteration is: [1] training's auc: 0.5 training's binary_logloss: 0.693147 valid_1's auc: 0.5 valid_1's binary_logloss: 0.693147 Fold 5 AUC : 0.500000 Full AUC score 0.375000 |
エラー「ValueError: y contains previously unseen labels」
3日間、各種エラーに悩まされました。
ようやくターゲットを次のように差し替えると、再現できました。
|
1 2 3 4 5 |
data = pd.DataFrame({'date' : ['1/1','1/2','1/3','1/4','1/5','1/6','1/7','1/8','1/9','1/10','1/11','1/12'], 'close' : [300,100,400,500,600,700,400,500,600,100,400,500], 'volume' : [10, 13, 16, 30, 33, 66,10, 13, 16,10, 13, 16], 'TARGET' : [1, 2, 3,4, 5, 6, 7, 8, 9,10, 11, 12] }, ) |
|
1 2 3 4 5 6 7 8 |
c:\python38\lib\site-packages\sklearn\preprocessing\_label.py in _encode_numpy(values, uniques, encode, check_unknown) 47 diff = _encode_check_unknown(values, uniques) 48 if diff: ---> 49 raise ValueError("y contains previously unseen labels: %s" 50 % str(diff)) 51 encoded = np.searchsorted(uniques, values) ValueError: y contains previously unseen labels: [1, 5, 6] |
原因はValidation setの中に、正解ラベルの一部が含まれてないためです。
一般的には十分なデータ量があるため問題ありませんが、動作確認のためデータの一部を使って学習している場合や、目的変数の数値が大量に存在している場合に発生します。
以前の実装では目的変数を「3日後の始値 – 明日の始値」としていましたが、その際にtrainとvalidに分けた際に、両方に含まれない変数値が存在した事が原因のようです。
エラー「LightGBMError: Multiclass objective and metrics don’t match」
データセットの目的変数(TARGET)を次のような値にすると発生します。
|
1 2 3 4 5 |
data = pd.DataFrame({'date' : ['1/1','1/2','1/3','1/4','1/5','1/6','1/7','1/8','1/9','1/10','1/11','1/12'], 'close' : [300,100,400,500,600,700,400,500,600,100,400,500], 'volume' : [10, 13, 16, 30, 33, 66,10, 13, 16,10, 13, 16], 'TARGET' : [1, 2, 0,0, 1, 2, 2, 0, 1,0, 1, 0] }, ) |
二値でないとダメなのか・・・・。
エラー「ValueError: Only one class present in y_true. ROC AUC score is not defined in that case.」
データセットの目的変数(TARGET)を次のような値にすると発生します。
|
1 2 3 4 5 |
data = pd.DataFrame({'date' : ['1/1','1/2','1/3','1/4','1/5','1/6','1/7','1/8','1/9','1/10','1/11','1/12'], 'close' : [300,100,400,500,600,700,400,500,600,100,400,500], 'volume' : [10, 13, 16, 30, 33, 66,10, 13, 16,10, 13, 16], 'TARGET' : [1, 0, 0,0, 1, 0, 0, 0, 1,0, 1, 0] }, ) |
なんだろう??偏りがあったから??
交差検証とAUCを用いた学習モデル有効性検証
過去のストラテジーテンプレートを使ったので次の通りです。
【資金管理条件】
- 銘柄選定(トヨタ)
- 1回の購入資金 (100万円)
- 投資総額 (1000万円)
- 単利運用
【買いルール】
- 3日後の始値が50%以上の確率で3%以上上がると判断した場合
【手仕舞いルール】
- 3日経過
【機械学習データ】
- [説明変数] 始値、高値、安値、調整後終値、出来高、移動平均、乖離率、RSI、BB、MACD、VR、騰落レシオ、曜日情報など
- [目的変数] 翌日の始値から3日後の始値が3%以上上がったもの
- [学習モデル] 勾配ブースティング(LightGBM)
- [その他] KFold(K-分割交差検証)を利用
AUCの精度、正解率の出力結果です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
Starting cross_validation. Train shape: (1201, 22), test shape: (5409, 21) Training until validation scores don't improve for 200 rounds Did not meet early stopping. Best iteration is: [66] training's auc: 1 training's binary_logloss: 0.157597 valid_1's auc: 0.630351 valid_1's binary_logloss: 0.740227 Fold 1 AUC : 0.630351 Training until validation scores don't improve for 200 rounds Did not meet early stopping. Best iteration is: [66] training's auc: 1 training's binary_logloss: 0.158626 valid_1's auc: 0.634393 valid_1's binary_logloss: 0.737874 Fold 2 AUC : 0.634393 Training until validation scores don't improve for 200 rounds Did not meet early stopping. Best iteration is: [60] training's auc: 1 training's binary_logloss: 0.182376 valid_1's auc: 0.676 valid_1's binary_logloss: 0.685114 Fold 3 AUC : 0.676000 Training until validation scores don't improve for 200 rounds Did not meet early stopping. Best iteration is: [78] training's auc: 1 training's binary_logloss: 0.130317 valid_1's auc: 0.641077 valid_1's binary_logloss: 0.752814 Fold 4 AUC : 0.641077 Full AUC score 0.645495 |
AUCは0.645であり、予測能が高いとは言えません。
説明変数の「feature_importances_」の結果です。
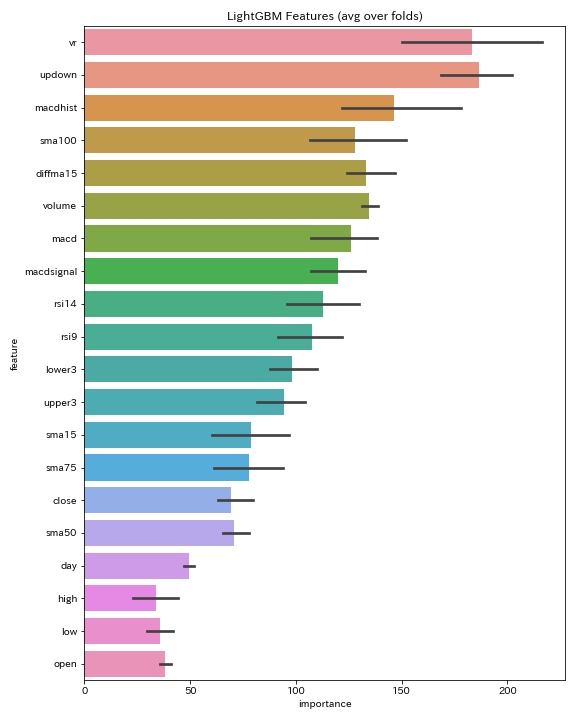
騰落レシオ、ボリュームレシオ、移動平均乖離率などのTA-Libに存在しない変数が高いです。
バックテスト結果
Protraを使ったバックテスト結果です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
株価データ: 日足 銘柄リスト: トヨタ 1998/01/05~2020/01/24における成績です。 ---------------------------------------- 全トレード数 622 勝ちトレード数(勝率) 413(66.40%) 負けトレード数(負率) 209(33.60%) 全トレード平均利率 1.58% 勝ちトレード平均利率 3.13% 負けトレード平均損率 -1.48% 勝ちトレード最大利率 18.33% 負けトレード最大損率 -5.25% 全トレード平均期間 4.41 勝ちトレード平均期間 4.49 負けトレード平均期間 4.24 ---------------------------------------- 必要資金 ¥870,000 最大ポジション(簿価) ¥1,017,000 最大ポジション(時価) ¥1,182,000 純利益 ¥7,493,100 勝ちトレード総利益 ¥9,854,100 負けトレード総損失 -¥2,361,000 全トレード平均利益 ¥12,047 勝ちトレード平均利益 ¥23,860 負けトレード平均損失 -¥11,297 勝ちトレード最大利益 ¥171,000 負けトレード最大損失 -¥45,000 プロフィットファクター 4.17 最大ドローダウン(簿価) -¥109,500 最大ドローダウン(時価) -¥128,000 ---------------------------------------- 現在進行中のトレード数 0 ---------------------------------------- 平均年利 43.06% 平均年利(直近5年) 24.17% 最大連勝 13回 最大連敗 5回 ---------------------------------------- [年度別レポート] 年度 取引回数 運用損益 年利 勝率 PF 最大DD 2019年 15回 ¥108,200円 12.44% 66.67% 3.11倍 -4.01% 2018年 25回 ¥227,300円 26.13% 72.00% 3.88倍 -3.58% 2017年 23回 ¥128,300円 14.75% 69.57% 3.22倍 -3.89% 2016年 35回 ¥311,800円 35.84% 65.71% 3.47倍 -5.21% 2015年 15回 ¥275,700円 31.69% 86.67% 29.13倍 -1.16% 2014年 30回 ¥190,900円 21.94% 66.67% 3.21倍 -3.51% 2013年 37回 ¥561,000円 64.48% 83.78% 9.77倍 -4.05% 2012年 41回 ¥625,200円 71.86% 73.17% 3.76倍 -4.76% 2011年 48回 ¥273,100円 31.39% 56.25% 2.10倍 -5.00% 2010年 41回 ¥385,600円 44.32% 68.29% 4.28倍 -4.05% 2009年 35回 ¥845,500円 97.18% 80.00% 6.56倍 -5.25% 2008年 36回 ¥836,500円 96.15% 77.78% 10.29倍 -3.41% 2007年 23回 ¥338,000円 38.85% 82.61% 13.07倍 -2.66% 2006年 38回 ¥171,000円 19.66% 57.89% 2.13倍 -4.55% 2005年 16回 ¥238,000円 27.36% 81.25% 24.80倍 -1.11% 2004年 18回 ¥326,000円 37.47% 72.22% 6.26倍 -2.70% 2003年 46回 ¥256,500円 29.48% 52.17% 1.77倍 -3.86% 2002年 37回 ¥405,500円 46.61% 67.57% 3.16倍 -4.79% 2001年 24回 ¥454,000円 52.18% 66.67% 4.52倍 -3.88% 2000年 39回 ¥535,000円 61.49% 64.10% 4.50倍 -3.37% |
利益曲線は次のようになります。

勝率66%、プロフィットファクター4、年利は20%超え、最大ドローダウンも5%以下です。
まとめ
「テクニカル指標が多過ぎる」「テクニカル指標が複雑過ぎる」「機械的に検出したパラメータセットをそのまま採用」というオーバーフィッティングになりうる要素を、交差検証を使って避けることができました。
学習精度は0.64と低いですが、Kaggle流のスコアアップの手法はまだ多くあります。
ようやく機械学習としては次の章に進んだ感じです。
ソースコード
機械学習の説明が主目的なので、株のストラテジー部分は割愛します。
とは言え、tilibは以前公開したものが古いですが利用できます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 |
import os import time import pickle import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt from nehori import tilib from sklearn.model_selection import KFold from lightgbm import LGBMClassifier from sklearn.metrics import roc_auc_score import gc # 概要出力 def display_overview(df): # それぞれのデータのサイズを確認 print("The size of df is : "+str(df.shape)) # 列名を表示 print(df.columns) # 表の一部分表示 display(df.head().append(df.tail())) def get_target_value(df): # 予測値(3日後の始値の上昇値) df['target'] = (df['open'].shift(-3) - df['open'].shift(-1)) / df['open'].shift(-1) df.loc[(df['target'] > 0.03), 'target'] = 1 df.loc[(-0.03 > df['target']), 'target'] = 0 return df def pre_processing(stock_id, skiprows=2000, skipfooter=2000): df_train = pd.read_csv("tosho/" + stock_id + ".csv", skiprows=skiprows, skipfooter=skipfooter, engine="python", names=("date", "open", "high", "low", "close", "volume")) # 目的変数(3日後の始値の上昇値) df_train = get_target_value(df_train) # 曜日追加 df_train['day'] = pd.to_datetime(df_train['date']).dt.dayofweek # 新特徴データ df_train = tilib.add_new_features(df_train) # 欠損値を列の1つ手前の値で埋める df_train = df_train.fillna(method='ffill') return df_train # Display/plot feature importance def display_importances(feature_importance_df_): cols = feature_importance_df_[["feature", "importance"]].groupby("feature").mean().sort_values(by = "importance", ascending = False)[:40].index best_features = feature_importance_df_.loc[feature_importance_df_.feature.isin(cols)] plt.figure(figsize = (8, 10)) sns.barplot(x = "importance", y = "feature", data = best_features.sort_values(by = "importance", ascending=False)) plt.title('LightGBM Features (avg over folds)') plt.tight_layout() plt.savefig('lgbm_importances01.png') # Cross validation with KFold def cross_validation(df_train, y, df_test, excluded_feats, num_folds = 4, stratified = False, debug = False): print("Starting cross_validation. Train shape: {}, test shape: {}".format(df_train.shape, df_test.shape)) # Cross validation model if stratified: folds = StratifiedKFold(n_splits = num_folds, shuffle = True, random_state = 1001) else: folds = KFold(n_splits = num_folds, shuffle = True, random_state = 1001) # Create arrays and dataframes to store results oof_preds = np.zeros(df_train.shape[0]) sub_preds = np.zeros(df_test.shape[0]) df_feature_importance = pd.DataFrame() feats = [f for f in df_train.columns if f not in excluded_feats] for n_fold, (train_idx, valid_idx) in enumerate(folds.split(df_train[feats], y)): X_train, y_train = df_train[feats].iloc[train_idx], y.iloc[train_idx] X_valid, y_valid = df_train[feats].iloc[valid_idx], y.iloc[valid_idx] clf = LGBMClassifier() # trainとvalidを指定し学習 clf.fit(X_train, y_train, eval_set = [(X_train, y_train), (X_valid, y_valid)], eval_metric = 'auc', verbose = 200, early_stopping_rounds = 200) oof_preds[valid_idx] = clf.predict_proba(X_valid, num_iteration = clf.best_iteration_)[:, 1] sub_preds += clf.predict_proba(df_test[feats], num_iteration = clf.best_iteration_)[:, 1] / folds.n_splits df_fold_importance = pd.DataFrame() df_fold_importance["feature"] = feats df_fold_importance["importance"] = clf.feature_importances_ df_fold_importance["fold"] = n_fold + 1 df_feature_importance = pd.concat([df_feature_importance, df_fold_importance], axis=0) print('Fold %2d AUC : %.6f' % (n_fold + 1, roc_auc_score(y_valid, oof_preds[valid_idx]))) del clf, X_train, y_train, X_valid, y_valid gc.collect() print('Full AUC score %.6f' % roc_auc_score(y, oof_preds)) display_importances(df_feature_importance) return sub_preds def main(df_train): # 概要出力 #display_overview(df_train) # 学習モデル構築 df_test = df_train.drop("target", axis=1) df_train = df_train.dropna(subset=["target"]) date = df_train["date"] df_train = df_train[(df_train['target'] == 1) | (df_train['target'] == 0)] excluded_feats = ['target', 'date'] y = df_train['target'] y_pred = cross_validation(df_train, y, df_test, excluded_feats, 4, False, True) print(y_pred) s = tilib.create_protra_dataset(stock_id, date, y_pred, 0.5) return s if __name__ == '__main__': df = pre_processing(str("7203"), 0, 0) # closeの欠損値が含まれている行を削除 df = df.dropna(subset=["close"]) s = main(df) with open("LightGBM.pt", mode='w') as f: f.write(tilib.merge_protra_dataset(s)) |

