
前回の日記で「Pytorchは難しい」という記載しましたが、このままで終わることはできません。
なぜなら、将来的に「Tensorflow」と「Pytorch」のどちらが生き残るか現時点では分からないからです。

ネットで調べると、PytorchをラップするScikit-Learning互換のニューラルネットワークライブラリ「skorch」というものを見つけました。

今回は「skorch」を試してみます。
[参考] 過去の機械学習関係の記事
skorchとは何?
前述通り、PytorchをラップするScikit-Learning互換のニューラルネットワークライブラリです。
つまり、skorchを用いて作成したmodelオブジェクトには、scikit-learnのようにfitやpredictなどのメソッドが一通り揃っています。
ただし、マイナーなライブラリで利用者は少ないです。
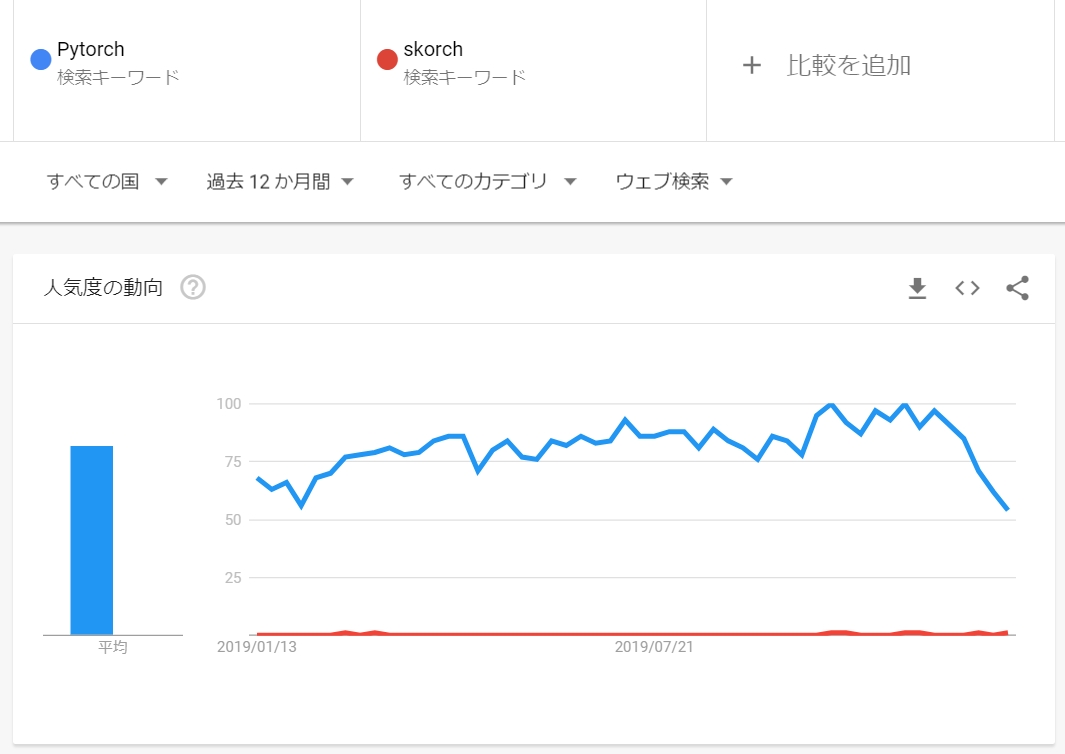
少ないというか皆無です。比例するようにググっても情報が少ないです。
現在の最新は2019年11月の0.7.0です。
v0.1.0が2017年12月に登場し、Pytorchのバージョンアップに伴い進化してきていますが、未だにalpha版的な扱いです。
コミュニティもあまり活発ではなく、急に辞めてしまう可能性があります。
ただ、このままではPytorchの学習が進まないので、使ってみます。
インストール
pipでインストールができました。
|
1 2 3 4 |
/c/Python36/Scripts/pip install skorch Collecting skorch Downloading https://files.pythonhosted.org/packages/fb/1e/cc4e1f23cd1faab06672f309e0857294aaa80c5f84670f4d3d19b08ab10b/skorch-0.7.0-py3-none-any.whl (105kB) ...(省略) |
使い方
結論から言うとScikit-Learning形式なので超簡単でした。
学習モデルの記載方法
これはPytorchの記述をそのまま利用します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
class CNN(nn.Module): def __init__(self): #畳み込み層 super(CNN, self).__init__() # 畳み込み層を定義する self.conv1 = nn.Conv2d(1, 32, 3, padding=1) self.conv2 = nn.Conv2d(32, 64, 3, padding=1) self.dropout1 = nn.Dropout2d(0.25) self.dropout2 = nn.Dropout2d(0.5) self.fc1 = nn.Linear(64*14*14, 128) self.fc2 = nn.Linear(128, 10) # Forward計算の定義 # Define by Runの特徴(入力に合わせてForward計算を変更可) def forward(self, x): x = F.relu(self.conv1(x)) x = F.relu(self.conv2(x)) x = F.max_pool2d(x, (2, 2)) x = self.dropout1(x) x = x.view(-1, 64*14*14) x = F.relu(self.fc1(x)) x = self.dropout2(x) return F.relu(self.fc2(x)) |
要するに「Define by run」な学習モデルを記載可能です。
学習用データ、検証用データの作成方法
今まで通りです。
ただし、Kerasとはデータのフォーマットの変換形式が異なります。
【Kerasの場合】
|
1 2 3 4 5 6 7 8 9 10 11 |
# 答えの削除 y_train = df_train["label"] X_train = df_train.drop(labels = ["label"],axis = 1) # 0~255を閉区間[0, 1]に正規化 X_train = X_train / 255.0 # データのフォーマットを変換:TensorFlowでの形式 = [サンプル数,高さ,幅,チャネル数] X_train = X_train.values.reshape(-1, 28, 28, 1) # ラベルをone hot vectorsに (ex : 2 -> [0,0,1,0,0,0,0,0,0,0]) y_train = to_categorical(y_train, num_classes = 10) # データを訓練用と検証用に分割 X_train, X_valid, y_train, y_valid = train_test_split(X_train, y_train, train_size=0.8) |
【Pytorchの場合】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 答えの削除 y_train = df_train["label"] X_train = df_train.drop(labels = ["label"],axis = 1) # 0~255を閉区間[0, 1]に正規化 X_train = X_train / 255.0 # データのフォーマットを変換:PyTorchでの形式 = [サンプル数,チャネル数,高さ,幅] X_train = X_train.values.reshape(-1, 1, 28, 28).astype('float32') # 値だけ取得 [1 0 1 ... 7 6 9] y_train = y_train.values # ラベルをone hot vectorsに (ex : 2 -> [0,0,1,0,0,0,0,0,0,0]) # y_train = torch.eye(10)[y_train].numpy() # データを訓練用と検証用に分割 X_train, X_valid, y_train, y_valid = train_test_split(X_train, y_train, train_size = 0.8) |
ただ、Kerasのようにy_train に対してOnehotエンコーディングをすると、うまく学習が進みませんでした・・・(誰か理由を教えて下さい・・・)
学習方法の記載方法
skorch.net に次の3種類が用意されています。
| 関数 | 説明 |
|---|---|
| NeuralNet | scikit-learnライクなmodelオブジェクトを作成するskorchのクラス。GridSearchCV(model, param_grid, scoring=’accuracy’)はできない |
| NeuralNetClassifier | 分類器をsklearn風に。Netオブジェクトのforwardメソッドの最後の活性化関数は必ずF.softmax(dim=-1)すること |
| NeuralNetRegressor | 回帰をsklearn風に |
説明を読む限り、少し挙動に制限がありそうです。
初期化の際に、学習の仕方を決めます。パラメータは、PyTorchの関数を使用できます。
- criterion : 損失関数の設定
- optimizer : 最適化関数の設定
- lr : 学習率の決定
- module : pytorchで実装したnn.Module継承クラス
- max_epochs : Epoch数
- batch_size : ミニバッチサイズ
- device : GPUの設定
|
1 2 3 4 5 6 7 8 9 10 |
# scikit-learnライクなmodelオブジェクトを作成 model = NeuralNet( module = CNN, # pytorchで実装したnn.Module継承クラス max_epochs = 128, # Epoch数 batch_size = 1, # ミニバッチサイズ optimizer = optim.Adam, # Adamによる最適化 # CrossEntropyLossはlog softmaxによる変換も実行 criterion = nn.CrossEntropyLoss, # 損失関数の設定 device = device, # GPUの設定 lr = 0.1) # 学習率の決定 |
その上で、訓練データの学習はScikit-Learning形式で次のように記載します。
|
1 2 |
# 訓練データ学習 model.fit(X_train, y_train) |
予測の記載方法
これもScikit-Learning形式なので簡単です。
|
1 2 3 4 5 6 7 8 |
# 検証データ予測 y_pred = model.predict(X_valid) # one-hotベクトルで結果が返るので、数値に変換 y_pred = [np.argmax(v, axis = None, out = None) for v in y_pred] # 正解率・正解数を確認 score = accuracy_score(y_valid, y_pred) # 正解率・正解数を出力 print("score skorch: {:.4f}".format(score)) |
なお、skorch.NeuralNetを用いて作成したmodelオブジェクトは、最後のLinear層->log_softmaxの活性化が施された値で「y_pred.shape=(10000, 10)」となります。
このため、y_predに対してargmax(axis=1)を取る必要があります。
|
1 |
y_pred = y_pred.argmax(axis=1) |
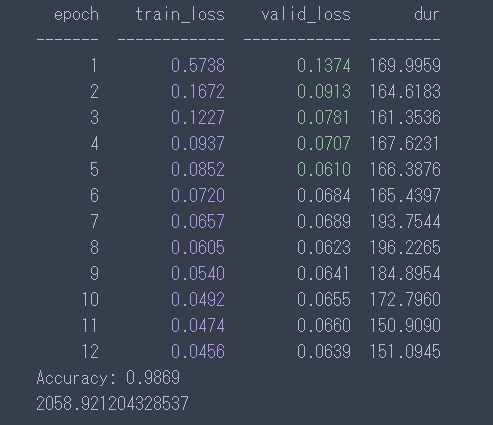
結果
出力されたCSVをサブミットすると「scored 0.98585」でKerasの「scored 0.98700」より少し低かったです。なぜ・・・。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
cpu X_train:(33600, 1, 28, 28) y_train:(33600,) X_valid:(8400, 1, 28, 28) y_valid:(8400,) CNN( (conv1): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (dropout1): Dropout2d(p=0.25) (dropout2): Dropout2d(p=0.5) (fc1): Linear(in_features=12544, out_features=128, bias=True) (fc2): Linear(in_features=128, out_features=10, bias=True) ) epoch train_loss valid_loss dur ------- ------------ ------------ -------- 1 0.5738 0.1374 169.9959 2 0.1672 0.0913 164.6183 3 0.1227 0.0781 161.3536 4 0.0937 0.0707 167.6231 5 0.0852 0.0610 166.3876 6 0.0720 0.0684 165.4397 7 0.0657 0.0689 193.7544 8 0.0605 0.0623 196.2265 9 0.0540 0.0641 184.8954 10 0.0492 0.0655 172.7960 11 0.0474 0.0660 150.9090 12 0.0456 0.0639 151.0945 Accuracy: 0.9869 2058.921204328537 |
なお、実際の出力画面は前回に比べて良くなったエポックに関しては色がつくよう仕様になっています。
まとめ
容易さはKerasと同じレベルです。
しばらくディープラーニングで解く場合には両方で記述するように努力してみます。
ただ「skorch」は癖も強そうなので、早めに「Pytorch」を使えるようになる必要はありそうです。
ソースコード
後学に向けてコメントも多くつけてます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 |
import time import numpy as np import pandas as pd import matplotlib.pyplot as plt import torch import torch.nn.functional as F from torch import nn, optim from torch.utils.data import Dataset, DataLoader,TensorDataset from sklearn.metrics import accuracy_score, precision_score from sklearn.model_selection import train_test_split from skorch import NeuralNet class CNN(nn.Module): def __init__(self): super(CNN, self).__init__() # 畳み込み層を定義する self.conv1 = nn.Conv2d(1, 32, 3, padding=1) self.conv2 = nn.Conv2d(32, 64, 3, padding=1) self.dropout1 = nn.Dropout2d(0.25) self.dropout2 = nn.Dropout2d(0.5) # 全結合を定義する # チェンネル数*最後のプーリング層の出力のマップサイズ=特徴量の数 self.fc1 = nn.Linear(64*14*14, 128) self.fc2 = nn.Linear(128, 10) # softmaxは損失関数でやらせるので nn.Linearで止めるのが流儀 # Forward計算の定義 # Define by Runの特徴(入力に合わせてForward計算を変更可) def forward(self, x): x = F.relu(self.conv1(x)) x = F.relu(self.conv2(x)) x = F.max_pool2d(x, (2, 2)) x = self.dropout1(x) # -1を引数とすると 第二引数から自動的に決まる x = x.view(-1, 64*14*14) x = F.relu(self.fc1(x)) x = self.dropout2(x) return F.relu(self.fc2(x)) # 学習用データ、検証用データの割り当て def build_train_valid_data(df_train): # 答えの削除 y_train = df_train["label"] X_train = df_train.drop(labels = ["label"],axis = 1) # 0~255を閉区間[0, 1]に正規化 X_train = X_train / 255.0 # データのフォーマットを変換:PyTorchでの形式 = [サンプル数,チャネル数,高さ,幅] X_train = X_train.values.reshape(-1, 1, 28, 28).astype('float32') # 値だけ取得 [1 0 1 ... 7 6 9] y_train = y_train.values # Onehotエンコーディング # y_train = torch.eye(10)[y_train].numpy() # データを訓練用と検証用に分割 X_train, X_valid, y_train, y_valid = train_test_split(X_train, y_train, train_size = 0.8) # 作成した行列出力 print("X_train:{}".format(X_train.shape)) print("y_train:{}".format(y_train.shape)) print("X_valid:{}".format(X_valid.shape)) print("y_valid:{}".format(y_valid.shape)) return X_train, X_valid, y_train, y_valid def main(): # GPUの設定(PyTorchでは明示的に指定する必要がある) device = 'cuda' if torch.cuda.is_available() else 'cpu' print(device) # CSV読み込み df_train = pd.read_csv('train.csv') # 学習用データ、検証用データの割り当て X_train, X_valid, y_train, y_valid = build_train_valid_data(df_train) # 計算時間計測 start = time.time() # scikit-learnライクなmodelオブジェクトを作成 model = NeuralNet( module = CNN, # pytorchで実装したnn.Module継承クラス max_epochs = 1, # Epoch数 batch_size = 128, # ミニバッチサイズ optimizer = optim.Adam, # Adamによる最適化 # CrossEntropyLossはlog softmaxによる変換も実行 criterion = nn.CrossEntropyLoss, # 損失関数の設定 device = device, # GPUの設定 lr = 0.001) # 学習率の決定 # 学習モデル出力 print(CNN()) # 訓練データ学習 model.fit(X_train, y_train) # 検証データ予測 y_pred = model.predict(X_valid) # one-hotベクトルで結果が返るので、数値に変換 #y_pred = [np.argmax(v, axis = None, out = None) for v in y_pred] # 活性化が施された値の変換(10000, 10)→(10000, 1)が必要 y_pred = y_pred.argmax(axis=1) # 正解率 (Accuracy) = (TP + TN) / (TP + TN + FP + FN) accuracy = accuracy_score(y_valid, y_pred) print("Accuracy: {:.4f}".format(accuracy)) # 計算時間出力 print(str(time.time() - start)) ################################ # テストデータ読み込み df_test = pd.read_csv("test.csv") # 0~255を0~1に正規化 X_test = df_test / 255.0 # 1×784→28×28に変換(1次元→2次元に変換) X_test = X_test.values.reshape(-1, 1, 28, 28).astype('float32') # テストデータ予測 predictions = model.predict(X_test) # one-hotベクトルで結果が返るので、数値に変換 # df_out = [np.argmax(v, axis = None, out = None) for v in predictions] # 活性化が施された値の変換(10000, 10)→(10000, 1)が必要 df_out = predictions.argmax(axis=1) # 整形 df_out = pd.Series(df_out, name = "Label") submission = pd.concat([pd.Series(range(1, df_test.shape[0] + 1), name = "ImageId"),df_out],axis = 1) # CSVに出力する submission.to_csv("submission.csv",index=False) if __name__ == '__main__': main() |

