これまでディープラーニング(深層学習)の実装にはKerasを利用していました。
近年は「PyTorchがディープラーニング系ライブラリでは良い」という話を聞きます。
![]()
今回はPytorchを使って前回扱った「Digit Recognizer」を解いてみます。
なお、Pytorchも未だPython3.8は未対応です。
[参考] 過去の機械学習関係の記事
なお、結論から言うと理解が追いつかず、学習モデルを構築してKaggleを実施するには敷居が高そうです。
ディープラーニングフレームワーク一覧
近年は様々なフレームワークが登場しています。
- TensorFlow(テンソルフロー)
- Keras(ケラス)
- Chainer(チェイナー)
- Pytorch(パイトーチ)
- MXNet(エムエックスネット) Deeplearning4j(DL4j)
- Microsoft Cognitive Toolkit(マイクロソフトコグニティブツールキット)
- PaddlePaddle(パドルパドル)
- Caffe(カフェ)
- Theano(テアノ)
その中で「Keras(TensorFlow)」「Pytorch」が人気という理解です。
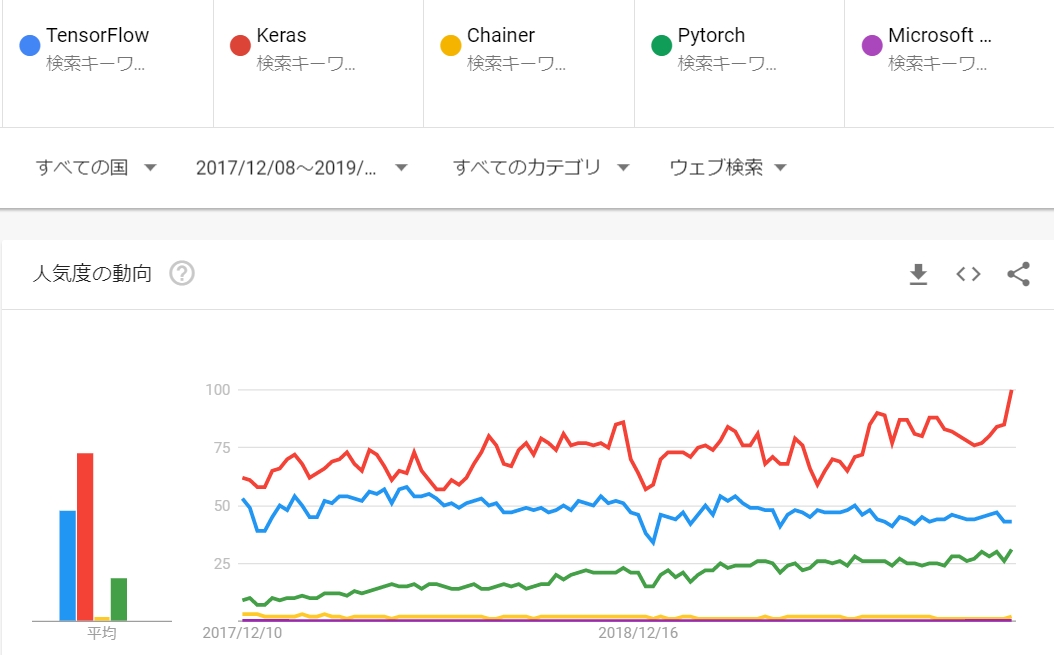
Googleトレンドで確認する限りは、人気は倍近い違いがあるように見えます。
ただ、Pytorchは研究者が続々と採用しており主要な論文が出ると即実装されるなど、R&D界隈では圧倒的に人気が高く、これだけでは判断できません。
Pytorchって何?何が凄いの?
PyTorchとはPython向けのオープンソース機械学習ライブラリで、Facebookの人工知能研究グループにより初期開発されました。
PyTorchは2016年後半に発表された比較的新しいライブラリです。
Kaggleの優勝者のJeremy Howardが「PyTorchの方が使い易い」と言っています。
【メリット】
- 研究者が続々と採用していて、主要な論文が出ると即座に実装される
- Define by run。学習処理内にbreakpointを置いたデバッグが可能
- modelもlayerもどっちも同じModuleクラスという設計なので複雑なネットワークも記述できる
- tensorオブジェクトにsqueeze、viewなどのメソッドが充実しているのでコードの可読性が高い
- gpuのon/offが簡単
【デメリット】
- 学習・予測処理を自分で一から書く必要がある。 dataloaderを作成するところを含めて、学習・予測処理を記述するのが面倒
- web上の情報が少ない
ようするに、私のような初心者にはPytorchはとっつきにくく難しいという事です。
ですが昨年「PyData.Tokyo Meetup #16 – 深層学習ライブラリ PyTorch」でPytorch押しな講演を聞き、それでもやらねば・・・と思ってます。
※同じDefine by runの「Chainer」は2019年12月5日に開発終了すると発表がありました。
Pytorchインストール
そもそもライブラリがPythonのバージョンアップに追従していない問題回避に仮想環境であるAnacondaを使うのが一般的です。
ただしAnacondaで苦い経験があるのでpip使って粛々とインストールしてみます。
※ Python3.6を利用しています。
|
1 |
/c/Python36/Scripts/pip install -U torch torchvision |
次のようなエラーが出ました。
|
1 2 |
from tools.nnwrap import generate_wrappers as generate_nn_wrappers ModuleNotFoundError: No module named 'tools.nnwrap' |
ダウンロードサイトから直接ダウンロードしたところ問題を回避できました。
|
1 2 |
/c/Python36/Scripts/pip install https://download.pytorch.org/whl/cu90/torch-1.1.0-cp36-cp36m-win_amd64.whl /c/Python36/Scripts/pip3 install https://download.pytorch.org/whl/cu90/torchvision-0.3.0-cp36-cp36m-win_amd64.whl |
PytorchでCNNを使ったDigit Recognizer実践
Kerasとソースコードを比較しながら理解を深めていきます。
学習モデルをつくる
この部分がディープラーニングで重要な部分です。
【Kerasの場合】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 畳込みニューラルネットワーク構築(Define and Run) def build_model_cnn(input_dim): inputs = Input(shape=(28, 28, 1)) layer1 = Conv2D(32, kernel_size=(3, 3), activation='relu')(inputs) layer2 = Conv2D(64, (3, 3), activation='relu')(layer1) layer3 = MaxPooling2D(pool_size=(2, 2))(layer2) layer4 = Dropout(0.25)(layer3) layer5 = Flatten()(layer4) layer6 = Dense(128, activation='relu')(layer5) layer7 = Dropout(0.5)(layer6) output = Dense(10, activation='softmax')(layer7) model = Model(inputs=inputs, outputs=output) return model |
【Pytorchの場合】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
class CNN(nn.Module): def __init__(self): # 畳み込み層 super(CNN, self).__init__() # 畳み込み層を定義する self.conv1 = nn.Conv2d(1, 32, 3, padding=1) self.conv2 = nn.Conv2d(32, 64, 3, padding=1) self.dropout1 = nn.Dropout2d(0.25) self.dropout2 = nn.Dropout2d(0.5) self.fc1 = nn.Linear(64*14*14, 128) self.fc2 = nn.Linear(128, 10) # Forward計算の定義 # 参考:Define by Runの特徴(入力xに合わせてForward計算を変更可) def forward(self, x): x = F.relu(self.conv1(x)) x = F.relu(self.conv2(x)) x = F.max_pool2d(x, (2, 2)) x = self.dropout1(x) x = x.view(-1, 64*14*14) x = F.relu(self.fc1(x)) x = self.dropout2(x) return F.relu(self.fc2(x)) |
Kerasはネットワーク構成を決めてからデータを投げます。
これを「Define and Run」と呼びます。
つまり定義の時点でデータは考えません。
一方でPyTorchがデータを投げて実行しながらネットワークを定義(forward(x)のx部分)します。
これは「Define by Run」と呼ばれます。
このメリットは次のようなものがあります。
- 柔軟な設計が可能
- 1イテレーションごとに設計を変えられる
このため、研究者界隈では「Define by Run」が主流です。
学習させる
これで終わっていれば、
PyTorch使ってみようかな・・・・
と思えます。
しかし、モデル(model)と学習データ(x_train, y_train)が用意できてからが大変です。
学習させてみましょう。
【Keras、scikit-learnの場合】
|
1 |
model.fit(X_train, y_train) |
一行です。
【Pytorchの場合】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# datasetオブジェクト作成 X_train_tensor = torch.Tensor(X_train).to(device) y_train_tensor = torch.Tensor(y_train).to(device) dataset = torch.utils.data.TensorDataset(X_train_tensor, y_train_tensor) # dataloaderオブジェクト作成 train_loader = DataLoader(X_train, batch_size=128, shuffle=True) # 学習処理 for epoch in range(2): # epochに関するイテレーション for i, data in enumerate(train_loader, 0): # batchに関するイテレーション inputs, labels = data # ミニバッチデータの取得 optimizer.zero_grad() # パラメータの勾配を初期化 outputs = model(inputs) # forward loss = criterion(outputs, labels) loss.backward() # backward optimizer.step() # パラメータの更新 |
datasetオブジェクト作成から数えると10行を超える記述が必要になってしまいます。
この部分に正直興味ないのです。
予測させる
こちらもPytorchは面倒です。
【Kerasの場合】
|
1 2 3 |
# 結果出力 [loss, accuracy] = model.evaluate(X_test, y_test, verbose = 0) print("loss:{0} -- accuracy:{1}".format(loss, accuracy)) |
一行です。
【Pytorchの場合】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# val model.eval() with torch.no_grad(): for images, labels in test_loader: images = images.to(device) labels = labels.to(device) outputs = model.forward(images) loss = criterion(outputs, labels) val_loss += loss.item() val_acc += (outputs.max(1)[1] == labels).sum().item() avg_val_loss = val_loss / len(test_loader.dataset) avg_val_acc = val_acc / len(test_loader.dataset) print ('Epoch [{}/{}], Loss: {loss:.4f}, val_loss: {val_loss:.4f}, val_acc: {val_acc:.4f}' .format(epoch+1, num_epochs, i+1, loss=avg_train_loss, val_loss=avg_val_loss, val_acc=avg_val_acc)) |
もう何をしているのか分かりません・・・・。
なぜ、ここまで記述が面倒なのかな・・・。
初心者には敷居が高く、自分で使いこなすのは大変そうです。
ほぼ写経で出てきたアウトプット
とりあえず記事末のスクリプトを動かすと次のような結果を得られます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
X_train:(33600, 1, 28, 28) y_train:(33600,) X_test:(8400, 1, 28, 28) y_test:(8400,) CNN( (conv1): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (dropout1): Dropout2d(p=0.25) (dropout2): Dropout2d(p=0.5) (fc1): Linear(in_features=12544, out_features=128, bias=True) (fc2): Linear(in_features=128, out_features=10, bias=True) ) Begin train Epoch [1/5], Loss: 0.0060, val_loss: 0.0020, val_acc: 0.9231 Epoch [2/5], Loss: 0.0027, val_loss: 0.0015, val_acc: 0.9423 Epoch [3/5], Loss: 0.0020, val_loss: 0.0012, val_acc: 0.9556 Epoch [4/5], Loss: 0.0016, val_loss: 0.0009, val_acc: 0.9689 Epoch [5/5], Loss: 0.0012, val_loss: 0.0007, val_acc: 0.9729 1155.3135521411896 90.32802486419678 |
5エポックでも計算時間が20分必要でした。
まとめ
難しいの一言。
学習モデル構築は何とかなりそうですが、学習させたり評価させる部分の実装が超面倒です。
このままだと私のような初心者は利用するメリットが全くありません・・・・。
ソースコード
正直、詳細の理解が追いついていません。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 |
import time import numpy as np import pandas as pd import matplotlib.pyplot as plt import torch import torch.nn.functional as F from torch import nn, optim from torch.utils.data import DataLoader, TensorDataset from sklearn.model_selection import train_test_split class CNN(nn.Module): def __init__(self): super(CNN, self).__init__() # 畳み込み層を定義する self.conv1 = nn.Conv2d(1, 32, 3, padding=1) self.conv2 = nn.Conv2d(32, 64, 3, padding=1) self.dropout1 = nn.Dropout2d(0.25) self.dropout2 = nn.Dropout2d(0.5) self.fc1 = nn.Linear(64*14*14, 128) self.fc2 = nn.Linear(128, 10) # Forward計算の定義 # Define by Runの特徴(入力xに合わせてForward計算を変更可) def forward(self, x): x = F.relu(self.conv1(x)) x = F.relu(self.conv2(x)) x = F.max_pool2d(x, (2, 2)) x = self.dropout1(x) x = x.view(-1, 64*14*14) x = F.relu(self.fc1(x)) x = self.dropout2(x) return F.relu(self.fc2(x)) # 学習用関数 def do_train(model, num_epochs, loader_train, loader_test, criterion, optimizer, device): train_loss_list = [] train_acc_list = [] val_loss_list = [] val_acc_list = [] for epoch in range(num_epochs): train_loss = 0 train_acc = 0 val_loss = 0 val_acc = 0 # train model.train() for i, (images, labels) in enumerate(loader_train): # GPUを使用するため,to()で明示的に指定 images, labels = images.to(device), labels.to(device) optimizer.zero_grad() # 勾配を初期化 outputs = model.forward(images) loss = criterion(outputs, labels) train_loss += loss.item() train_acc += (outputs.max(1)[1] == labels).sum().item() loss.backward() # 誤差を逆伝播させる optimizer.step() # 重みを更新する avg_train_loss = train_loss / len(loader_train.dataset) avg_train_acc = train_acc / len(loader_train.dataset) # val (エポック終了時点ごとにテスト用データで評価) model.eval() with torch.no_grad(): for images, labels in loader_test: images = images.to(device) labels = labels.to(device) outputs = model.forward(images) loss = criterion(outputs, labels) val_loss += loss.item() val_acc += (outputs.max(1)[1] == labels).sum().item() avg_val_loss = val_loss / len(loader_test.dataset) avg_val_acc = val_acc / len(loader_test.dataset) print ('Epoch [{}/{}], Loss: {loss:.4f}, val_loss: {val_loss:.4f}, val_acc: {val_acc:.4f}' .format(epoch+1, num_epochs, i+1, loss=avg_train_loss, val_loss=avg_val_loss, val_acc=avg_val_acc)) train_loss_list.append(avg_train_loss) train_acc_list.append(avg_train_acc) val_loss_list.append(avg_val_loss) val_acc_list.append(avg_val_acc) return train_loss_list, train_acc_list, val_loss_list, val_acc_list # テスト用関数 def do_test(model, new_loader_test, device): pred_list = [] # ミニバッチごとに推論 with torch.no_grad(): # 推論時には勾配は不要 model.eval() for images in new_loader_test: images = images.to(device) output = model.forward(images) # 推論結果の取得と正誤判定 _, pred = torch.max(output.data, 1) # 確率が最大のラベルを取得 pred_list.append(pred.item()) return pred_list # 学習用データ、検証用結果の割り当て def build_train_test_data(df_train): # 答えの削除 y_train = df_train["label"].values X_train = df_train.drop(labels = ["label"],axis = 1).values X_train = X_train.reshape(-1, 1, 28, 28) # 0~255を0~1に正規化 X_train = X_train / 255.0 # データを訓練用(学習用)とテスト用に分割 X_train, X_test, y_train, y_test = train_test_split(X_train, y_train, train_size=0.8) # 作成した行列出力 print("x_train:{}".format(X_train.shape)) print("y_train:{}".format(y_train.shape)) print("x_test:{}".format(X_test.shape)) print("y_test:{}".format(y_test.shape)) return X_train, X_test, y_train, y_test def main(): df_train = pd.read_csv('train.csv') X_train, X_test, y_train, y_test = build_train_test_data(df_train) # PyTorchのテンソルに変換 X_train = torch.tensor(X_train, dtype = torch.float32) y_train = torch.tensor(y_train, dtype = torch.int64) X_test = torch.tensor(X_test, dtype = torch.float32) y_test = torch.tensor(y_test, dtype = torch.int64) # 入力(x)とラベル(y)を組み合わせて最終的なデータを作成 train_set = TensorDataset(X_train,y_train) test_set = TensorDataset(X_test, y_test) # DataLoaderを作成 batch_sizes = 128 loader_train = DataLoader(train_set, batch_size = batch_sizes, shuffle = False) loader_test = DataLoader(test_set, batch_size = batch_sizes, shuffle = False) # GPUの設定(PyTorchでは明示的に指定する必要がある) device = 'cuda' if torch.cuda.is_available() else 'cpu' # モデル作成 model = CNN().to(device) print(model) # ネットワークの詳細を確認用に表示 size_check = torch.FloatTensor(10, 1, 28, 28) size_check = size_check.to(device) # 損失関数を定義 criterion = nn.CrossEntropyLoss() # 最適化手法を定義(ここでは例としてSGDを選択) optimizer = optim.SGD(model.parameters(), lr = 0.01, momentum = 0.9, weight_decay = 5e-4) # エポック終了時点ごとにテスト用データで評価 num_epochs = 5 print('Begin train') start = time.time() # 学習 train_loss_list, train_acc_list, val_loss_list, val_acc_list = do_train( model, num_epochs, loader_train, loader_test, criterion, optimizer, device) print(time.time() - start) # 学習結果図示 #plt.plot(train_acc_list, label = 'Training loss') #plt.plot(val_acc_list, label = 'Validation loss') #plt.legend(); test = pd.read_csv('test.csv') test = test.values test = test.reshape(-1, 1, 28, 28) test = test / 255 batch_sizes = 1 test = torch.tensor(test, dtype = torch.float32) test_sets = TensorDataset(test) new_loader_test = DataLoader(test, batch_size = batch_sizes, shuffle = False) pred_list = [] start = time.time() # テスト用データを推論 pred_list = do_test(model, new_loader_test, device) print(time.time() - start) pred_list = np.array(pred_list) ID_lists = np.arange(1, pred_list.shape[0] + 1) # 提出用CSV作成 submissions=pd.DataFrame({"ImageId": ID_lists, "Label": pred_list}) submissions.to_csv("submissions.csv", index = False, header = True) if __name__ == '__main__': main() |