ビッグデータ分析、新卒年収は1000万円以上 東大生の人気職種に(産経新聞)

「官僚でもなく、有名企業でもなく、データサイエンティスト職を志望する東大生が目立ち始めている」(就職情報会社)。
滋賀大は平成29年度から、専門学部として全国初となる「データサイエンス学部」を新設。
横浜市立大も専門学部を開設した。東工大は今年4月から、全大学院生を対象にデータサイエンスとAIの教育を行うことを打ち出した。
AI専門家の大量生産時代が来ようとしています。
「Get started」の次のステップとされている「Playground」を体験してもメダルは出ません。
であれば、過去の「Featured」を体験して経験値を積むほうが早道です。
書籍も出ているようなので購入しました。
ただ「ディープラーニング」や「自然言語」「画像・音声処理」に関する記載はなく、「まずはLightGBMで解け」というKaggleに特化した書籍になっています(Kaggleで勝つことが目的の本なので仕方ないです)。
過去の「Featured」として、まずはタイタニック同様の「分類」コンテストで有名な次の問題を解いてみます。

このコンペは与えられた個人のクレジットの情報や以前の応募情報などから、各データが債務不履行になるかどうかを予測する問題です。
ただし、Titanicのように1ファイルではなく、複数ファイル(テーブル)でデータが与えられています。
[参考] 過去の機械学習関係の記事
今回はサブミットを目標する
「application_train.csv」には顧客一人一人の主要な情報(性別や家族の人数、ローンのタイプ(現金or資産運用など)、資産額、車の有無など)と、ある期間までにローンの支払いができたら「0」、できなかったら「1」のラベルがついています。
「application_test.csv」にはラベルが無く、このファイルのデータの予測が求められています。。
・・・・、とりあえず、これぐらいの理解で進めます。
探索的データ解析(データの理解:EDA)
データの特徴を確認してみます。
|
1 2 3 4 5 6 |
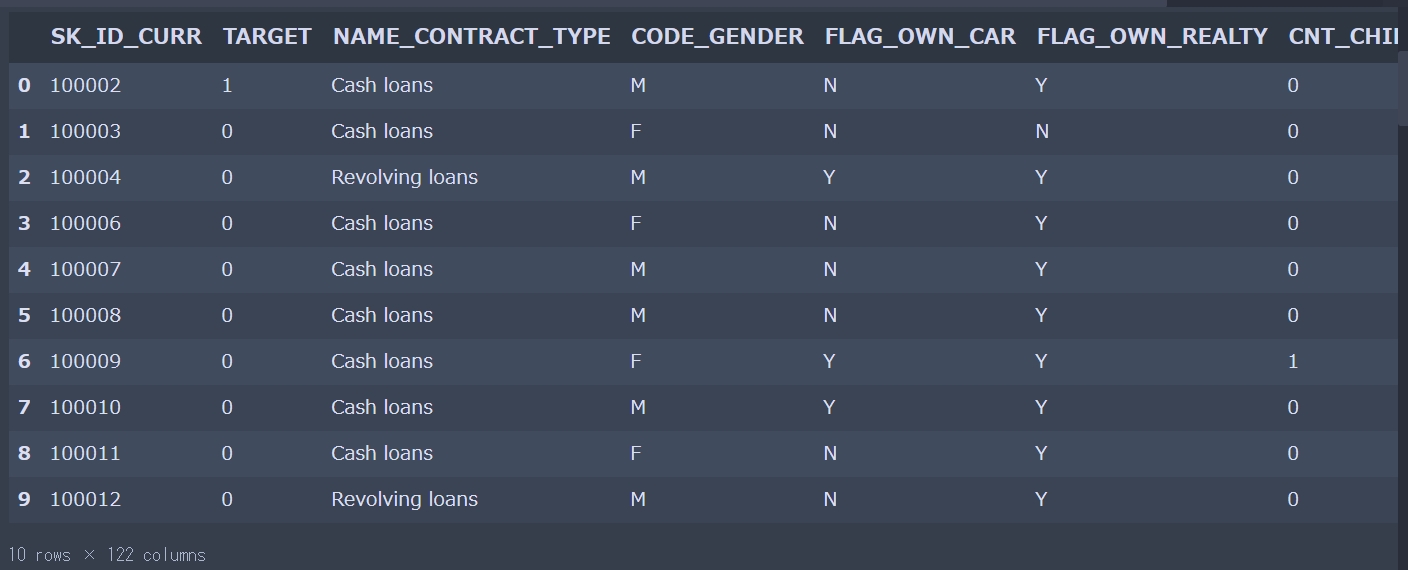
print("The size of train is : "+str(df_train.shape)) print("The size of test is : "+str(df_test.shape)) # 列名を表示 print(df_train.columns) # 表の一部分表示 display(df_train.head(10)) |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
The size of train is : (307511, 122) The size of test is : (48744, 121) Index(['SK_ID_CURR', 'TARGET', 'NAME_CONTRACT_TYPE', 'CODE_GENDER', 'FLAG_OWN_CAR', 'FLAG_OWN_REALTY', 'CNT_CHILDREN', 'AMT_INCOME_TOTAL', 'AMT_CREDIT', 'AMT_ANNUITY', ... 'FLAG_DOCUMENT_18', 'FLAG_DOCUMENT_19', 'FLAG_DOCUMENT_20', 'FLAG_DOCUMENT_21', 'AMT_REQ_CREDIT_BUREAU_HOUR', 'AMT_REQ_CREDIT_BUREAU_DAY', 'AMT_REQ_CREDIT_BUREAU_WEEK', 'AMT_REQ_CREDIT_BUREAU_MON', 'AMT_REQ_CREDIT_BUREAU_QRT', 'AMT_REQ_CREDIT_BUREAU_YEAR'], dtype='object', length=122) |
次にヒストグラムとヒートマップを確認します。
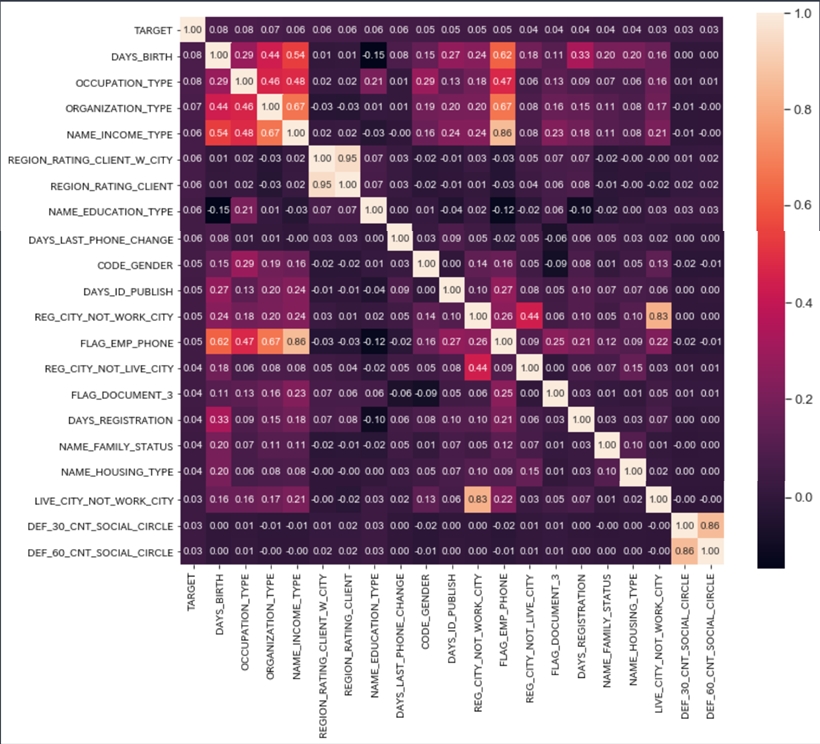
際立って相関のある特徴量はありません。
うーん、小さ過ぎてよく分かりません・・・。
特徴エンジニアリング(データの準備:前処理)
欠損値の補完と、変数の数値化(エンコーディング)だけ行い、学習データ80%と検証データ20%に分けました。
この辺りも、今まで作成した実装そのままです。
学習モデルの構築
とりあえず分類に関する機械学習アルゴリズム(ディープラーニング除く)を全て試してみます。
その中で最もスコアが高かった結果を利用してサブミットを行ってみます。
学習モデルの実行
実行時間は2時間ぐらい必要でした。
今まで、株のシステムトレードで2,3時間かけて計算していた事を考えれば待つのは苦ではないです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 |
X_train:(246008, 121) y_train:(246008,) X_valid:(61503, 121) y_valid:(61503,) LogisticRegression Accuracy: 0.9189701147930148 Time = 10.338585138320923 LinearSVC Accuracy: 0.9188115833631426 Time = 149.94293427467346 Perceptron Accuracy: 0.8757438782478618 Time = 2.5563747882843018 SVC Accuracy: 0.9189945042437644 Time = 5361.758109092712 GaussianNB Accuracy: 0.9189863744268479 Time = 2.413205862045288 AdaBoostClassifier Accuracy: 0.9191774251243862 Time = 80.90104365348816 ExtraTreesClassifier Accuracy: 1.0 Time = 136.27082109451294 GradientBoostingClassifier Accuracy: 0.9193359565542584 Time = 322.4067506790161 RandomForestClassifier Accuracy: 0.9999756105492504 Time = 169.71853947639465 BaggingClassifier Accuracy: 0.9860207798120386 Time = 195.86073398590088 PassiveAggressiveClassifier Accuracy: 0.9189945042437644 Time = 2.1733858585357666 RidgeClassifier Accuracy: 0.9189904393353062 Time = 1.811901330947876 SGDClassifier Accuracy: 0.9187262202855192 Time = 49.713196754455566 KNeighborsClassifier Accuracy: 0.9206692465285682 Time = 151.36826395988464 DecisionTreeClassifier Accuracy: 1.0 Time = 28.645012140274048 MLPClassifier Accuracy: 0.9189945042437644 Time = 489.26534485816956 LGBMClassifier Accuracy: 0.9201042242528699 Time = 13.73279333114624 CatBoostClassifier Accuracy: 0.9228602321875712 Time = 166.07307600975037 XGBClassifier Accuracy: 0.919173360215928 Time = 165.28887796401978 [[56605 1] [ 4897 0]] Model[LogisticRegression] Testing Accuracy = "0.9203616083768271 !" [[56588 18] [ 4897 0]] Model[LinearSVC] Testing Accuracy = "0.9200851990959791 !" [[53724 2882] [ 4654 243]] Model[Perceptron] Testing Accuracy = "0.8774693917369885 !" [[56606 0] [ 4897 0]] Model[SVC] Testing Accuracy = "0.9203778677462888 !" [[56606 0] [ 4897 0]] Model[GaussianNB] Testing Accuracy = "0.9203778677462888 !" [[56566 40] [ 4864 33]] Model[AdaBoostClassifier] Testing Accuracy = "0.9202640521600572 !" [[56602 4] [ 4891 6]] Model[ExtraTreesClassifier] Testing Accuracy = "0.9204103864852121 !" [[56576 30] [ 4858 39]] Model[GradientBoostingClassifier] Testing Accuracy = "0.9205242020714437 !" [[56602 4] [ 4893 4]] Model[RandomForestClassifier] Testing Accuracy = "0.9203778677462888 !" [[56336 270] [ 4785 112]] Model[BaggingClassifier] Testing Accuracy = "0.9178088873713477 !" [[56606 0] [ 4897 0]] Model[PassiveAggressiveClassifier] Testing Accuracy = "0.9203778677462888 !" [[56606 0] [ 4896 1]] Model[RidgeClassifier] Testing Accuracy = "0.9203941271157504 !" [[56577 29] [ 4897 0]] Model[SGDClassifier] Testing Accuracy = "0.9199063460319009 !" [[56196 410] [ 4846 51]] Model[KNeighborsClassifier] Testing Accuracy = "0.9145407541095556 !" [[51424 5182] [ 4107 790]] Model[DecisionTreeClassifier] Testing Accuracy = "0.848966717070712 !" [[56606 0] [ 4897 0]] Model[MLPClassifier] Testing Accuracy = "0.9203778677462888 !" [[56529 77] [ 4803 94]] Model[LGBMClassifier] Testing Accuracy = "0.9206542770271369 !" [[56503 103] [ 4754 143]] Model[CatBoostClassifier] Testing Accuracy = "0.9210282425247549 !" [[56601 5] [ 4890 7]] Model[XGBClassifier] Testing Accuracy = "0.9204103864852121 !" CatBoostClassifier was selected Finished. |
SVCはアホみたいに時間がかかりました。
その他、GradientBoostingClassifier、MLPClassifier なども遅いです。
一方でLGBMClassifier は早かったです。
そして正解率「0.920」と高いので、KaggleでLightGBMが人気なのも頷けます。
今回は「CatBoost」が最も良い正解率となりました。
結果のサブミット
サブミットした結果「スコア 0.53662」となりました。
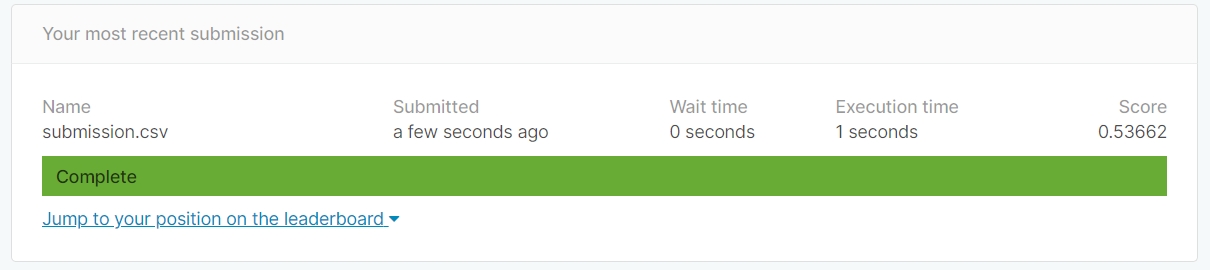
順位は終了コンペなので分かりませんが推定で「6812/7175 = Top 95%」という糞結果です。
[改良] サンプルの答えとフォーマットの違いに気づく
「sample_submission.csv」を見てみると「TARGET」が「1」「0」でなくて小数となっていました。
|
1 2 3 4 5 6 7 8 9 10 11 |
SK_ID_CURR,TARGET 100001,0.5 100005,0.5 100013,0.5 100028,0.5 100038,0.5 100042,0.5 100057,0.5 100065,0.5 100066,0.5 100067,0.5 |
今まではpredictを用いたラベル予測をしていましたが、実際にはどちらのラベルに分類されるか確率で表す事が求められていたようです。
このため、学習モデルをpredict_probaメソッドを使って予測させます。
|
1 2 3 |
predictions = model.predict_proba(do_data_cleansing(df_test)) print(predictions) df_test[target] = predictions[:,1] |
|
1 2 3 4 5 6 7 |
[[0.92253606 0.07746394] [0.89761672 0.10238328] [0.97179705 0.02820295] ... [0.97403776 0.02596224] [0.97241941 0.02758059] [0.61401276 0.38598724]] |
一列目が「0」である確率、二列目が「1」である確率です。
要するに、下記は同じ事を意味します。
|
1 2 3 |
# テスト値を読み込み predictions = model.predict(do_data_cleansing(df_test)) predictions = (model.predict_proba(do_data_cleansing(df_test))[:,0] < 0.5).astype(int) |
この小数の答えをサブミットしてみたところ、「スコア 0.70639」となりました。
順位は推定で「6119/7175 = Top 85%」という結果です。
まとめ
サブミットを最初の目標として進めました。
まずは準備ができたので、今後は他のKernelなどを見ながらスコアアップを目指していきます。
・・・が、インクリメンタルな開発の方が自分には向いているのかな。。
一度サブミットしてしまうと、モチベーションが下がってます。
全スコアを見る限り「0.81」〜「0.79」に大量に集中しています。
細かいチューニングが鍵ですが、面倒そうだなあ。
よく遭遇するエラー
TypeError: list indices must be integers or slices, not str
|
1 2 3 |
Traceback (most recent call last): File " TypeError: list indices must be integers or slices, not str |
【原因】
「indices」([]の中に入るもの)として渡されたものが文字列にも関わらず、listのindicesが整数かスライスではない。
|
1 2 |
lst = [0, 1, 2, 3] lst["hoge"] |
ソースコード
スコアは低いですが、今回のコードです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 |
import time import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import train_test_split from xgboost import XGBClassifier from lightgbm import LGBMClassifier from catboost import CatBoostClassifier from sklearn.linear_model import LogisticRegression,Perceptron,PassiveAggressiveClassifier,RidgeClassifier,SGDClassifier from sklearn.svm import LinearSVC,NuSVC,SVC from sklearn.ensemble import AdaBoostClassifier,ExtraTreesClassifier,GradientBoostingClassifier,RandomForestClassifier,BaggingClassifier from sklearn.gaussian_process import GaussianProcessClassifier from sklearn.neighbors import KNeighborsClassifier,RadiusNeighborsClassifier from sklearn.tree import DecisionTreeClassifier,ExtraTreeClassifier from sklearn.neural_network import MLPClassifier from sklearn.naive_bayes import GaussianNB from sklearn.metrics import confusion_matrix # 学習用データ、検証用データの割り当て def build_train_valid_data(df, target, train_size = 0.8): # 答えの削除 y_train = df[target] X_train = df.drop([target], axis = 1) # 80% を学習用データ X_train, X_valid, y_train, y_valid = train_test_split(X_train, y_train, train_size = train_size) # 作成した行列出力 print("X_train:{}".format(X_train.shape)) print("y_train:{}".format(y_train.shape)) print("X_valid:{}".format(X_valid.shape)) print("y_valid:{}".format(y_valid.shape)) return X_train, X_valid, y_train, y_valid # 外れ値の削除 def del_outlier(df): return df # 多重共線性の削除 def del_multicollinearity(df): return df # 欠損値補完 def do_imputation(df): for col in df: # check if it is a number if df[col].dtype != "object": df[col].fillna(0.0, inplace=True) else: df[col].fillna("NA", inplace=True) return df # 各変数の順序関係に従って、エンコーディング def do_encodiing(df, i, target): num = -1 mapping = {} for j in df.groupby(i)[target].mean().sort_values().index: num += 1 mapping[j] = num df[i] = df[i].map(mapping) return df # ラベルエンコーダー def encode_label(df, i): lbl = LabelEncoder() lbl.fit(list(df[i].values)) df[i] = lbl.transform(list(df[i].values)) return df # Data Cleansing def do_data_cleansing(df, target = ""): # 外れ値の削除 df = del_outlier(df) # 多重共線性の削除 df = del_multicollinearity(df) # 各変数の順序関係に従って、エンコーディング for i in df.loc[:, df.dtypes == "object"].columns: if (target != ""): df = do_encodiing(df, i, target) else: df = encode_label(df, i) # 欠損値補完 df = do_imputation(df) return df # ヒートマップによる相関の強い特徴量チェック def display_heatmap(df, k, target): corrmat = df.corr() cols = corrmat.nlargest(k, target)[target].index cm = np.corrcoef(df[cols].values.T) fig, ax = plt.subplots(figsize = (12, 10)) sns.set(font_scale = 1.2) hm = sns.heatmap(cm, cbar = True, annot = True, square = True, fmt = ".2f", annot_kws = {"size": 10}, yticklabels = cols.values, xticklabels = cols.values) plt.show() fig.savefig("figure4.png") # ヒストグラムによる分布の可視化 def display_chart(df): sns.set(font_scale = 0.8) df.hist(bins=50, figsize=(20,15)) # creates a figure with 10 (width) x 10 (height) inches plt.rcParams['figure.figsize'] = [10, 5] # グラフ同士が重ならないようにする関数 #plt.tight_layout() # グラフの表示 plt.show() # 概要出力 def display_overview(df_train, df_test): # それぞれのデータのサイズを確認 print("The size of train is : "+str(df_train.shape)) print("The size of test is : "+str(df_test.shape)) # 列名を表示 print(df_train.columns) # 表の一部分表示 display(df_train.head(10)) # 各列のデータの型を表示 print(df_train.dtypes.sort_values()) def output_accuracy(models, X, y): best_model = None best_name = "" total = 0.0 for name, model in models.items(): y_pred = model.predict(X) cm = confusion_matrix(y.ravel(), y_pred) print(cm) # extracting TN, FP, FN, TP TN, FP, FN, TP = confusion_matrix(y, y_pred).ravel() score = (TP + TN) / (TP + TN + FN + FP) print('Model[{}] Testing Accuracy = "{} !"'.format(name, score)) if total <= score: best_model = model best_name = name total = score print()# Print a new line print('%s was selected' % best_name) return best_model clf_names = [["LogisticRegression",""], ["LinearSVC",""], #["NuSVC",""], # Nu-Support Vector Classification ["Perceptron",""], ["SVC",""], # Support Vector Machine Classification ["GaussianNB",""], # Gaussian 型 Naive Bayes ["AdaBoostClassifier",""], ["ExtraTreesClassifier",""], ["GradientBoostingClassifier",""], ["RandomForestClassifier",""], ["BaggingClassifier",""], ["PassiveAggressiveClassifier",""], ["RidgeClassifier",""], ["SGDClassifier",""], # Stochastic Gradient Descent(SGD:確率的勾配降下法) #["GaussianProcessClassifier",""], # Gaussian Naive Bayes ["KNeighborsClassifier",""], # kNN (K近傍法) ["DecisionTreeClassifier",""], ["MLPClassifier",""], # Multilayer perceptron(MLP:多層パーセプトロン ["LGBMClassifier",""], ["CatBoostClassifier","logging_level='Silent'"], ["XGBClassifier",""], ] def sklearn_model(X_train, y_train): total_start = time.time() models = {} total = 0.0 name = "" for i in range(len(clf_names)): start = time.time() # インスタンス化 clf = eval("%s(%s)" % (clf_names[i][0], clf_names[i][1])) clf.fit(X_train, y_train) score = clf.score(X_train, y_train) print('%s Accuracy:' % clf_names[i][0], score) print(' Time = %s' % str(time.time() - start)) models[clf_names[i][0]] = clf if total <= score: total = score name = clf_names[i][0] print('Total Time = %s' % str(time.time() - total_start)) print('%s was selected' % name) return models def main(): # 分類するターゲット名 target = "TARGET" df_train = pd.read_csv("application_train.csv") df_test = pd.read_csv("application_test.csv") # 概要出力 #display_overview(df_train, df_test) df_train = do_data_cleansing(df_train, target) # 概要出力 #display_overview(df_train, df_test) # ヒートマップによる相関の強い特徴量チェック #display_heatmap(df_train, 21, target) # ヒストグラムによる分布の可視化 #display_chart(df_train) X_train, X_valid, y_train, y_valid = build_train_valid_data(df_train, target, 0.8) models = sklearn_model(X_train, y_train) model = output_accuracy(models, X_valid, y_valid) # テスト値を読み込み predictions = model.predict_proba(do_data_cleansing(df_test)) df_test[target] = predictions[:,1] # CSVに出力する df_test[["SK_ID_CURR", target]].to_csv("submission.csv", index = False) print("Finished.") if __name__ == '__main__': main() |