
近くの図書館に行くと、クリスマス装飾に変わっていた。
そして、トイレに次のようなステッカーが貼ってあった。

トイレと恋は勇気を出して
一歩前に踏み出しましょう
何このセンス!!
まさに、才能の無駄遣い!!
Kaggleの「Titanic : Machine Learning from Disaster」(タイタニック号の生存者予測)を使って機械学習を理解する事を目的とした記事第二弾です。
因みに、世間的にはタイタニック2号が2022年にドバイを出て最終的にはニューヨークへ初航海予定です。
データ分析とは何か?
分析の目的
「分析」の目的は「レポート」や「グラフ」の作成ではありません。
分析の本質は、あらゆる現象の実態(事実とその関係性)を論理やデータで解明していく事であり、
分析の目的は、情報やデータを正しく理解することを通して「正しい意思決定」「正しいアクション」を促すことである(意思決定・アクションの最大化)
「正しい」は、「真因に基づいた課題解決」を指しています。
なお、言い換えると「意思決定」や「アクション」につながらない作業は「分析」とは言いません。
分析方法の種類

[引用] 株式会社ブレインパッド
| 仮説検証型 | 仮説探索型 | |
|---|---|---|
| 概要 | データ分析前に、状況を鑑みて仮説を立て、裏付けするために分析し、結果に基づいて施策を行う | 目的を設定したら、まずデータ分析して、分析して見えてきた結果から仮説を立て、施策に落とし込む |
| メリット | 仮説を適切に設定すれば分析に要する時間はかなり短縮できる | データを起点にするので、客観的な視点を持ちやすく、新たな気付きを得られやすい |
| デメリット |
・正しく仮説を立てるためには一定のスキルが必要 ・アナリスト自身のスキルや経験が問われるため、属人的になりやすい ・スキルが高くても、主観によるバイアスが入る可能性もゼロではない ・仮説を立証するため以外の情報は見ない場合が多く、貴重な気付きを見逃す可能性も高い |
膨大なデータを分析する必要があるため、仮説検証型に比べると時間がかかる場合が多い |
仮説検証型は、データをにらんで原因を探るのではなく、まず自分なりの仮説を立て、いくつかの仮説を組み合わせて結果に至るストーリーを考えます。そのストーリーの正しさをデータを使って証明するアプローチです。
ただし、データを前提に仮説を立てないと、データを取った時点で主観の入った自分に都合のよいデータになってしまう。との声も聞こえます。
この辺りはケース・バイ・ケースかもしれません。
なお、機械学習は手段でしかありません。
ただし、総当たりでの分析が可能なので短時間で結果が出ます。また、主観もほぼ排除されるので、担当者によるばらつきを抑えられます。
Jupyter Notebook のテーマ変更
今回は表にしたりグラフにしたり・・と可視化に優れているのでJupyter Notebookを使います。
ただし、背景色が白色で苦手なんだよな・・・。
と思ったら、背景を黒色に変更し、グラフの文字が見えるようにCSSを変更されている記事があったので、そのまま拝借します。
まずは、Jupyter Notebook の背景変更
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
$ /c/Python36/Scripts/pip install --upgrade jupyterthemes $ /c/Python36/Scripts/jt.exe -l Available Themes: chesterish grade3 gruvboxd gruvboxl monokai oceans16 onedork solarizedd solarizedl $ /c/Python36/Scripts/jt.exe -t onedork -T -N -kl |
ヘッダーの表示項目を設定オプションは次のとおりです。
- -T: ツールバーを表示する
- -N: ノートブックの名前を表示する
- -kl: カーネルロゴを表示する

色々と変更しすぎて戻せなくなった場合のテーマをデフォルトに戻すコマンドも載せておきます。
|
1 |
$ /c/Python36/Scripts/jt.exe -r |
Jupyter Notebook のCSS変更
Windowsであれば「C:\Python36\Lib\site-packages\notebook\static\notebook\css」の下にあるoverride.cssを下記のように編集します。
|
1 2 3 4 5 6 7 8 9 10 11 |
/*This file contains any manual css for this page that needs to override the global styles. This is only required when different pages style the same element differently. This is just a hack to deal with our current css styles and no new styling should be added in this file.*/ #ipython-main-app { position: relative; } div.output_area img, div.output_area svg { background: #fff; } |
Jupyter Notebookを再起動してください。
これですべての準備は整いました。
データを集計して可視化していく
タイタニック号では、約1500人が犠牲となり、生存者は約700人でした。
まず、データの概要を見てみます。
|
1 2 3 |
import pandas as pd df_train = pd.read_csv("train.csv") display(df_train.head(10)) |
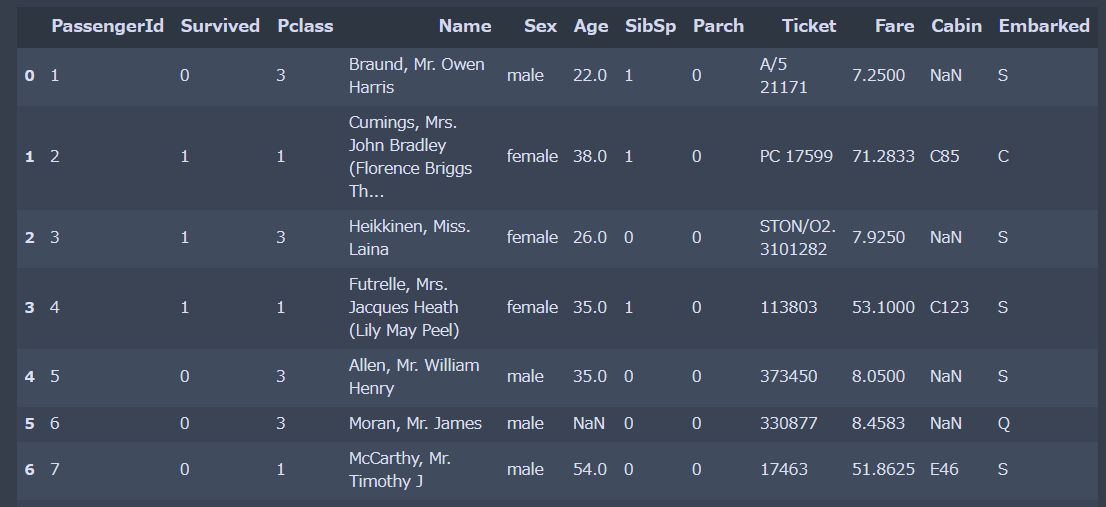
データの中身は次のような項目が書かれています。
| 項目 | 詳細 |
|---|---|
| PassengerId | kaggleが割り振った個人に割り振ったID |
| Survived | 生存・非生存(予測対象) |
| Pclass | 客室のクラスを表すコード1は1等、2は2等、3は3等 |
| Name | 名前 |
| Sex | 性別 |
| Age | 年齢 |
| SibSp | 同行した兄弟または配偶者の人数 |
| Parch | 同行した親または子どもの人数 |
| Ticket | チケット番号 |
| Fare | 料金 |
| Cabin | キャビン番号 |
| Embarked | 乗船した港(Cherbourg、Queenstown、Southampton) |
この「Survived(生存)」か否かを他の情報の傾向データを参考に仮説を立てるのが、今回のミッションです。
仮説の作りと検証
まずはデータの概要を確認します。
|
1 2 |
# データの概要 df_train.describe() |
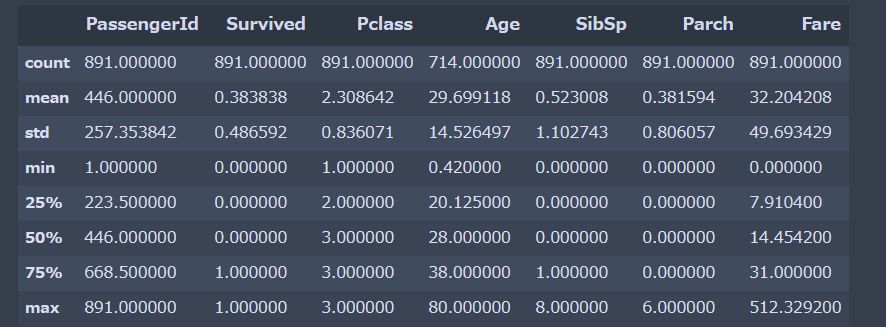
次のような事に気づけます。
- Survivedの平均が0.3なので、死んだ人の方が多い。
- Pclassの平均が2.3なので、中流〜下流の人が多い。
- 年齢の平均は29才。
- 乗船していた親や兄弟の数は平均して1人くらい。
- 運賃は、平均して32ドル。最低は0ドル、最高は512ドル。
因みに、乗客の男女比に大きな差はありません。
|
1 2 3 |
# 男女の割合 import seaborn as sns sns.barplot(x="Sex",y="PassengerId",data=df_train) |
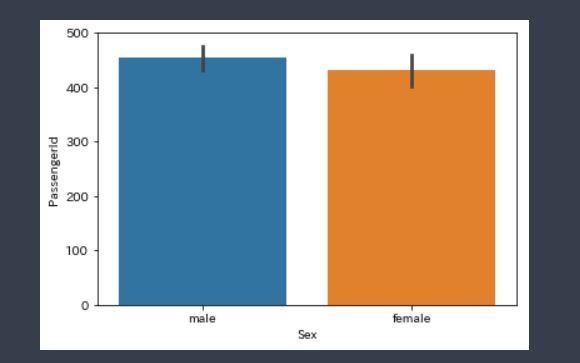
女性と男性で死亡率の関係性
女性と男性で死亡率を確認します。
|
1 2 |
# 男女の生き残っている割合 df_train.groupby("Sex")[["Survived"]].mean() |
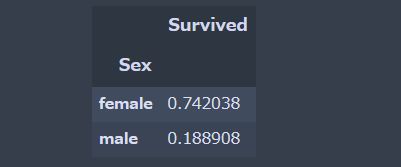
圧倒的に男性が死んでいます。
これが、タイタニック号沈没が多くの物語によって語り継がれている理由の一つです。
沈没に際し、船長が「女性と子ども優先(Women and children first)」と命じた。
ただし、タイタニック号の事例は例外的と考えたほうがよく、緊急事態での避難について多くの人間は利己的に振るまい、我先に逃げる傾向がある。
[引用] タイタニック号沈没と「女性と子ども優先」の議論
先にも後にも近年の海難事故で、この英国船のような偏った傾向になったものはありません。
客室の階級による関係性
客室の階級(一等級、二等級、三等級)で死亡率を確認します。
|
1 2 3 |
# 階級ごとの死亡率 import seaborn as sns sns.barplot(x="TicketClass",y="Survived",data=df_train) |
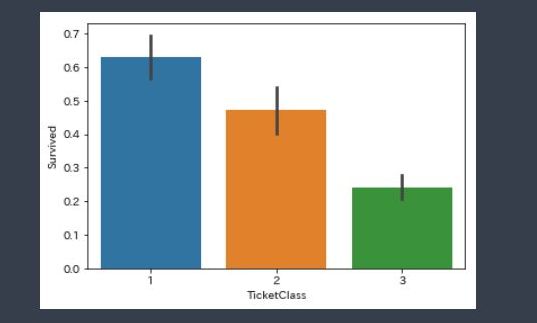
生き残ったのは上流階級の人が多いことが分かります。
上流(一等級):中流(二等級):下流(三等級)=6割:5割:2割
理由は色々と考えられれます。
- 上流の人は逃げやすい部屋にいた
- 下流の人は後回しにされた
- 下流の人は沈没していることを知らなかった
ここで一つの記事を見つけました。
ホワイト・スター・ライン社は、各等級の乗客をそれぞれのエリアに分けて滞在させ、裕福な乗客とそうでない乗客が船内で出会わないようにしました。
これによって船が沈んでいった時、階級を分けるゲートで分断されていた三等客室の乗客は、水が流れ込んで来るまで事態を知ることも無く、その結果この階から多くの犠牲者が出ました。
[引用] 映画『タイタニック』の驚くべき10の真実
やはり、階級によって生存率に差が生まれてしまったようです。
階級ごとの支払い金額の関係性
インターネット上で確認した限り、階級毎の値段差は大きかったようです。
- 1等は上流階級の貴族、アメリカンドリームで成功した事業者など。タイタニック号の乗船料金は、870ポンド(現在の550万円~180万円)。
- 2等は中流階級である医師、教師、牧師、上級会社員など。乗船料金は15~20万円ほどでした。
- 3等は、ヨーロッパ各地からアメリカンドリームを夢見て集まった移民たち。乗船料金は、3~6ポンド(2~4万円)。
データで確認します。
|
1 2 3 4 5 6 7 8 |
# 階級ごとの支払い金額 import matplotlib.pyplot as plt plt.scatter(df_train['Fare'], df_train['TicketClass'], color = 'blue', label='Passenger Paid') plt.ylabel('Class') plt.xlabel('Price / Fare') plt.title('Price Of Each Class') plt.legend() plt.show() |
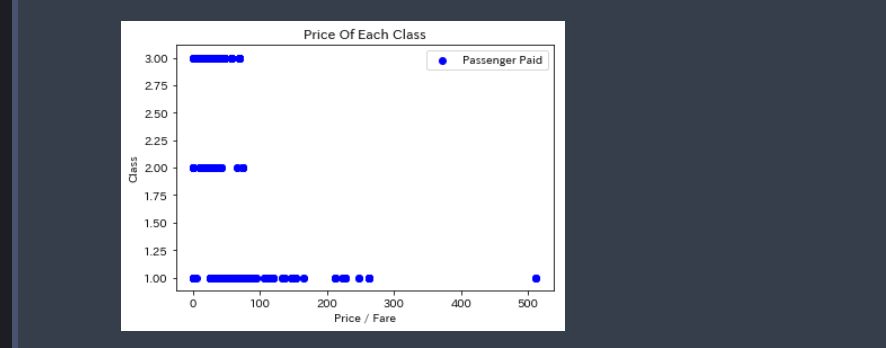
何となく上流(一等級)の支払い値段が高いように見えますが、この出力表示ではよく分かりません。
数値をプロットしてみます。
|
1 |
df_train.pivot_table("Fare","TicketClass") |
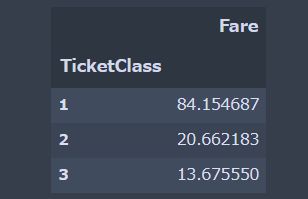
値段差が出てきました。
- 上級(一階級)は、84 ポンド?
- 中級(二階級)は、20 ポンド?
- 下級(三階級)は、13 ポンド?
ネットで仕入れた乗船料とは異なり、理由は分かりません。
少なくとも、上流階級の人たちは運賃を多めに払っており、さらに生存率が高いことは理解できました。
年齢、性別、階級の関係性
|
1 2 3 |
# 年齢、性別、階級の関係 age = pd.cut(df_train['Age'],[0,18,80]) df_train.pivot_table("Survived",["Sex",age],"TicketClass") |
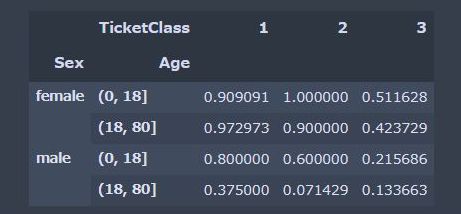
0-18才の子供の方がより多く生き残っていたことが分かります。二階級の0-18才の子供は100%生存していますね。
なお、三階級の0-18才の子供の生存率は20%程度です。
一緒に乗船した家族の人数の関係性
|
1 2 3 4 5 6 |
import seaborn as sns df_train = pd.read_csv('train.csv') # 家族数(子、親、配偶者、兄弟) df_train['FamilySize'] = df_train['Parch'] + df_train['SibSp'] + 1 sns.countplot(x='FamilySize', data=df_train, hue='Survived') |
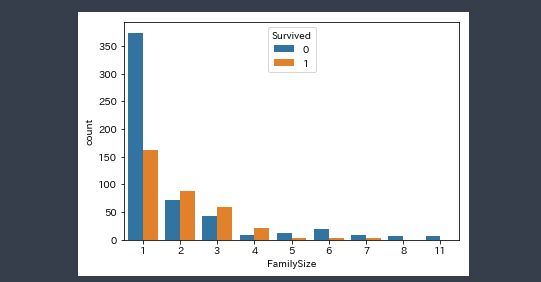
「Survived」が0は死亡です。
- 一緒に乗船した家族の人数が5人以上の場合、生存率が低い
- 1人で乗ると生存率が低い
ということが見えてきました。
ではなぜ大家族か一人で乗ると死亡率が高かったのでしょうか?
- 大家族であると当然お金もたくさんかかるので3等に乗った人が多かった
- 一人の方々も3等が多かった
というのが背景のようです(ソース割愛)。
乗船した港と生存の関係性
タイタニックの航路はイギリスの「サウサンプトン」→フランスの「シェルブール」→アイルランドの「クイーンズタウン」の順番でした。
|
1 2 3 4 5 |
df_train=pd.read_csv("train.csv") g = sns.factorplot(x="Embarked", y="Survived", data=df_train, size=6, kind="bar", palette="muted") g.despine(left=True) g.set_ylabels("survival probability") |
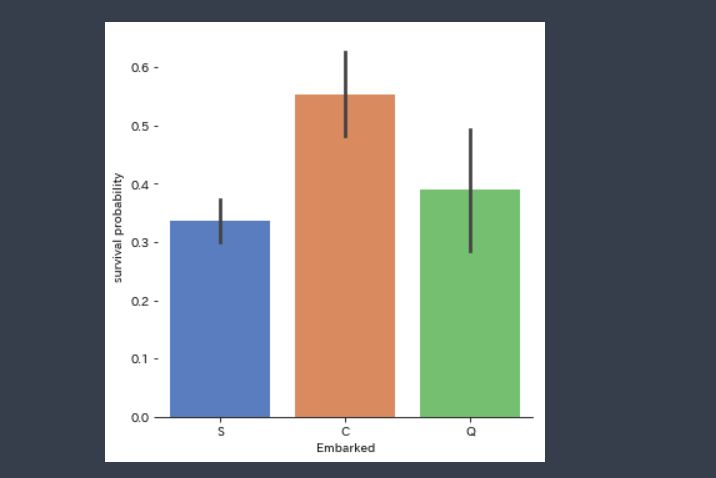
図を見るとS(シェルブール)から乗った人の生存率が高かったことがわかります。
その理由は一つは、一等に乗った人の割合が高かったからことが背景のようです(ソース割愛)。
年齢と生存の関係性
全年齢による生存の違いをカーネル密度推定(KDE)で出力してみます。
|
1 2 3 4 5 6 |
df_train=pd.read_csv("train.csv") plt.figure() sns.FacetGrid(data=df_train, hue="Survived", aspect=4).map(sns.kdeplot, "Age", shade=True) plt.ylabel('Passenger Density') plt.title('KDE plot of Age against Survival') plt.legend() |
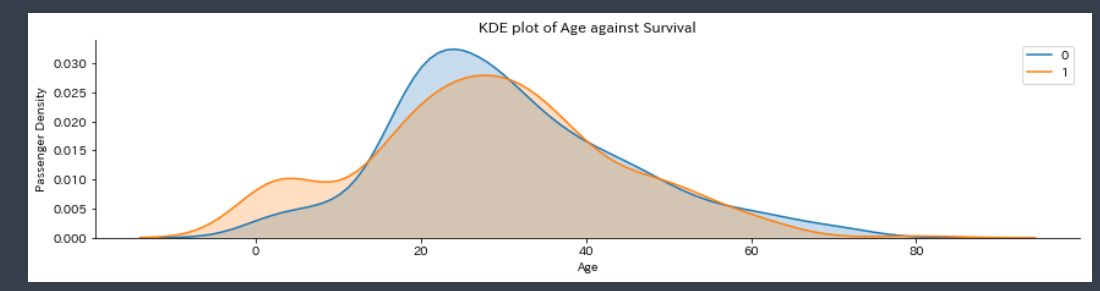
10代後半から30代ほどまでは死亡率が高く、子供の死亡率は低いです。
このころは15歳より上だとほとんど成人とみなされていたようです。
結局、言えること
女性、子供、上流階級、一緒に乗車した家族が少ないが1人旅行でない場合ほど生存できる可能性が高い。
という事が実データから立証されたことになります。
このように「仮説→検証」によって取るべき手を決め、「意思決定を加速」することが可能になります。
そして「可視化」には次のような目的があります。
- 仮説を検証すること
- 仮説を見つけること
最後に:自分が乗っていたらどうなっていたか?
私の場合だったら次のようなデータになります。
- 階級:底辺の社畜サラリーマンだが移民じゃないので中流(二等級)
- 性別:男性です。
- 年齢:39才です。
- 兄弟や夫妻:行くとしたら妻と行くので1人
- 親や子供:親と子供とは行かないので0人
- 運賃:二等級の平均20(ポンド?)
- 乗船町:Cherbourg(学習データとして使わない)
このデータを「test.csv」として保存します。
|
1 2 3 |
import pandas as pd df_train = pd.read_csv("nehori.csv") display(df_train.head(10)) |

そして、前回のソースコードをそのまま流用し「submission.csv」を出力します。
結果・・・・
83%の確率で「死亡」
ちなみに、100ポンド支払うと「死亡」を免れそうです。
結局、金ですね・・・。
近い未来にはAIによって、事前に行動予測してくれる時代が来るんだろうね。

