
株式投資は、予測するものではなくルールに沿って選ぶものです。
その際に、選んだ銘柄が当たろうが外れようが、つねに勝てるルールを作り出す事が大切です。
- 【11回目】機械学習を使った株価予測(ファンダメンタルズ指標導入でAUC=0.70超え)
- 【10回目】機械学習を使った株価予測(関連論文・サイトを調査してみる)
- 【9回目】機械学習で株価予測(年利・勝率向上の分析)
- 【8回目】機械学習で株価予測(交差検証+ROC 曲線とAUCで精度65%)
- 【7回目】機械学習で株価予測(騰落レシオ+株価分割対応で複数銘柄)
- 【6回目】機械学習で株価予測(機械学習で株予測(3点チャージ法の有効性検証)
これは、「株の自動売買で億り人」を夢見て無駄な人生を費やしている一人の中年男の物語です。

[引用] 「全シ連」坂本タクマ
株価の自動予測の問題点
システムトレードは、過去に儲かっていたパターンを探索する作業ではありません。
投資家や市場の心理から優位性があると思われるチャートなどのテクニカルパターンを再現して、その再現にマッチしている銘柄を検索する事です。
作成されたストラテジーの中には、実践投入すると利益曲線が寝ることがあります。
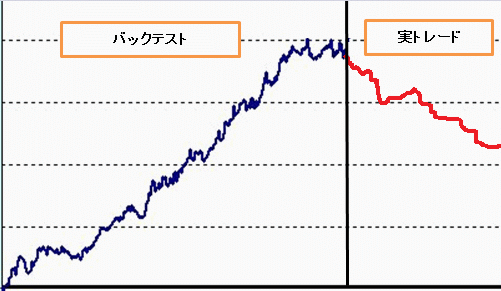
これは、過学習(オーバーフィッティング)と呼ばれます。
知っているテクニカル指標や、思いつく限りの条件を盛り込んで、学習システムに食わせて複雑怪奇なルールを作ってしまうことは簡単です。
ですが、無駄な贅肉が付きすぎたルールは、市場に不測の事態が起きたときに、機敏に対応できなくなります。

実際に、手動でテクニカル指標を組み合わせた方法(左)に対して、学習システムで作成したルール(右)の利益曲線です。
フォワードテスト(実践投入テスト)をすると、学習システムで作成したルール(右)はより利益曲線が寝てしまう結果になりました。
今回は、データの可視化によって理解を深め次アクションを決めます。
データの可視化の目的は?
「可視化」とは「人間が直接見ることのできない現象や物事の関係を画像、グラフ、図、表などを用いて目に見える状態にすること」です。
多くの人は「デザインの良さ」とか「ツールの利用性」に頭が行きがちです。
「見える化」「診る化」「魅せる化」という造語がはびこり、そもそもの目的を見失ってます。
これは根底に、
視覚化すれば何か示せるだろう
という安直な考えがあるためです。
しかし、対象を数値データや数理モデルなどに対応付ける部分に本質があり、実際には敢えて可視化を強調する必要がないものが多いです。
改めて、可視化の目的は、
(アクションに対する)意思決定を早期化すること
です。
要するにアクションなき可視化は、自己満足に過ぎません。
pandas-profilingを使った探索的データ解析の可視化
pandas-profilingが探索的データ解析(EDA)には便利です。
インストールはpipから行えます。
|
1 2 3 4 5 6 7 |
# # /c/Python38/Scripts/pip install pandas-profiling Collecting pandas-profiling Downloading https://files.pythonhosted.org/packages/1d/08/1f614fb2d31b59cd69896b900044c8d7119389b9151983a872d047ea021f/pandas-profiling-2.4.0.tar.gz (150kB) Requirement already satisfied: pandas>=0.19 in c:\python38\lib\site-packages (from pandas-profiling) (0.25.3) Requirement already satisfied: matplotlib>=1.4 in c:\python38\lib\site-packages (from pandas-profiling) (3.1.2) Collecting confuse>=1.0.0 ...(省略) |
Jupter notebook上に表示するには次のようなコードを書きます。
|
1 2 3 4 |
import pandas as pd import pandas_profiling as pdp df = pd.read_csv('train.csv') pdp.ProfileReport(df) |
出力された結果です。
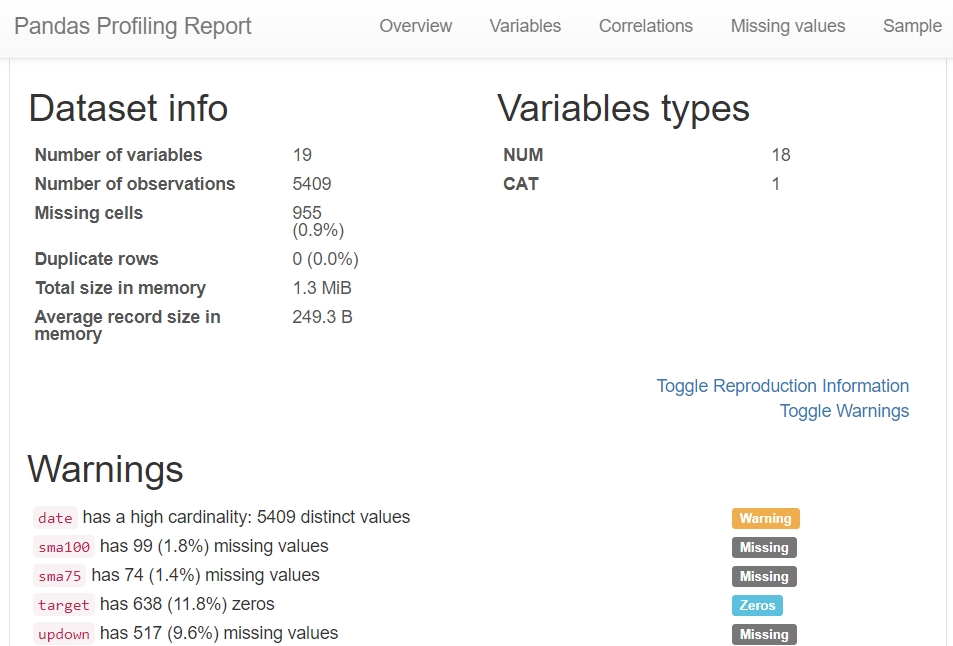
データ型別の基本統計量がグラフで出力されます。
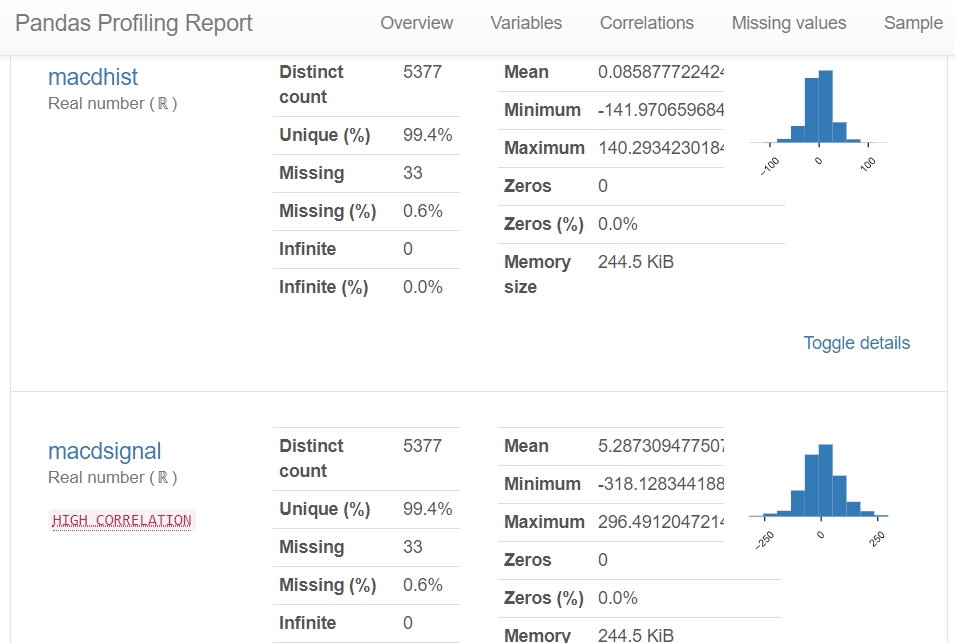
線形回帰モデルでは、出力から得られる値の誤差が正規分布に従うことを仮定するため、歪度が正の値の場合には対数変換をすることで正規分布に近づける必要があります。
各説明変数の欠損値、合計数も出力されます。
ヒートマップも次のように表示可能です。
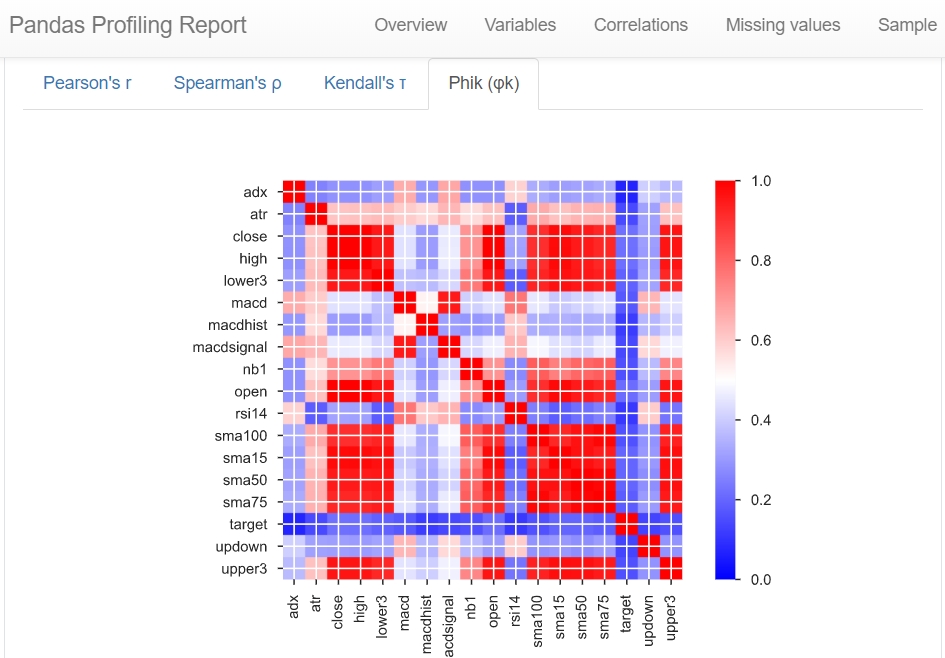
今回の例だと「Target」が目的関数です。
もっとも他の説明変数と相関がない(=青色)となっています。
また、日にちを変えただけの単純移動平均線同士は当たり前ですが強い相関があります。
これらは、多重共線性の点から一つに絞る必要があるかもしれません。
なお、HTMLファイルの作成も可能です。
|
1 2 3 4 5 |
import pandas as pd import pandas_profiling as pdp df = pd.read_csv('train.csv') profile = pdp.ProfileReport(df) profile.to_file("myoutputfile.html") |
その他、データフレームの構造に、数値データはピアソンの積率相関とスピアマンの順位相関などが出力されます。
LightGBMの決定木を可視化
plot_tree、create_tree_digraphのメソッドによって作成された木を可視化することができます。
create_tree_digraphは内部でGraphvizを呼んでいます。
Graphvizは.dotという独自形式を使ってテキストをグラフに変換するツールです.
|
1 2 3 4 5 6 7 8 9 |
import lightgbm as lgb # 決定木を可視化 def display_tree(clf): ax = lgb.plot_tree(clf, tree_index=0, figsize=(20, 20), show_info=['split_gain']) plt.show() print('Plotting tree with graphviz...') graph = lgb.create_tree_digraph(clf, tree_index=0, format='png', name='Tree') graph.render(view=True) |
交差検証時に作られたモデルを出力してみました。
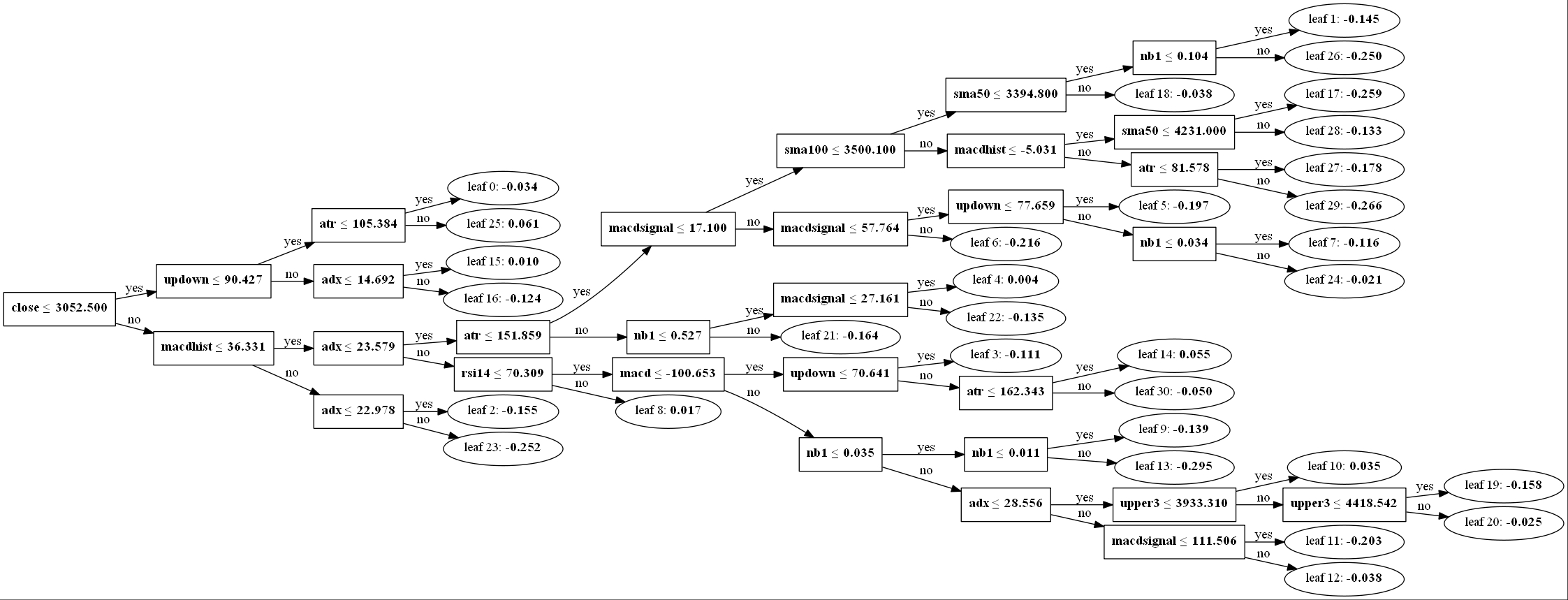
水平向きの出力なので読みにくい・・・・。
APIマニュアルには決定木を垂直向ききに出力できるオプションが書いてありましたが、私の利用しているバージョン(2.3.1)が古いのかサポートされていませんでした。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
def create_tree_digraph(booster, tree_index=0, show_info=None, precision=3, old_name=None, old_comment=None, old_filename=None, old_directory=None, old_format=None, old_engine=None, old_encoding=None, old_graph_attr=None, old_node_attr=None, old_edge_attr=None, old_body=None, old_strict=False, orientation='horizontal', **kwargs): """Create a digraph representation of specified tree. .. note:: For more information please visit https://graphviz.readthedocs.io/en/stable/api.html#digraph. Parameters |
手元の環境のソースコードには「orientation」という引数が存在していません。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
def create_tree_digraph(booster, tree_index=0, show_info=None, precision=3, old_name=None, old_comment=None, old_filename=None, old_directory=None, old_format=None, old_engine=None, old_encoding=None, old_graph_attr=None, old_node_attr=None, old_edge_attr=None, old_body=None, old_strict=False, **kwargs): """Create a digraph representation of specified tree. .. note:: For more information please visit https://graphviz.readthedocs.io/en/stable/api.html#digraph. Parameters ---------- |
他に出力される決定木は次のような感じです・・・・。

はい、過学習しています。
木が深すぎて、一体何を学習しているのか分かりません。
もともとバックテストとフォワードテストの結果に差があり過ぎるので過学習を疑っていましたが、決定木が凄いことになっています。
過学習すると未知データに対して、全く対応ができなくなるので、フォワードテストでの結果が出ません。
が、決定木の図を見ると各説明指標に対して閾値を設けて分岐しているだけなんですね。
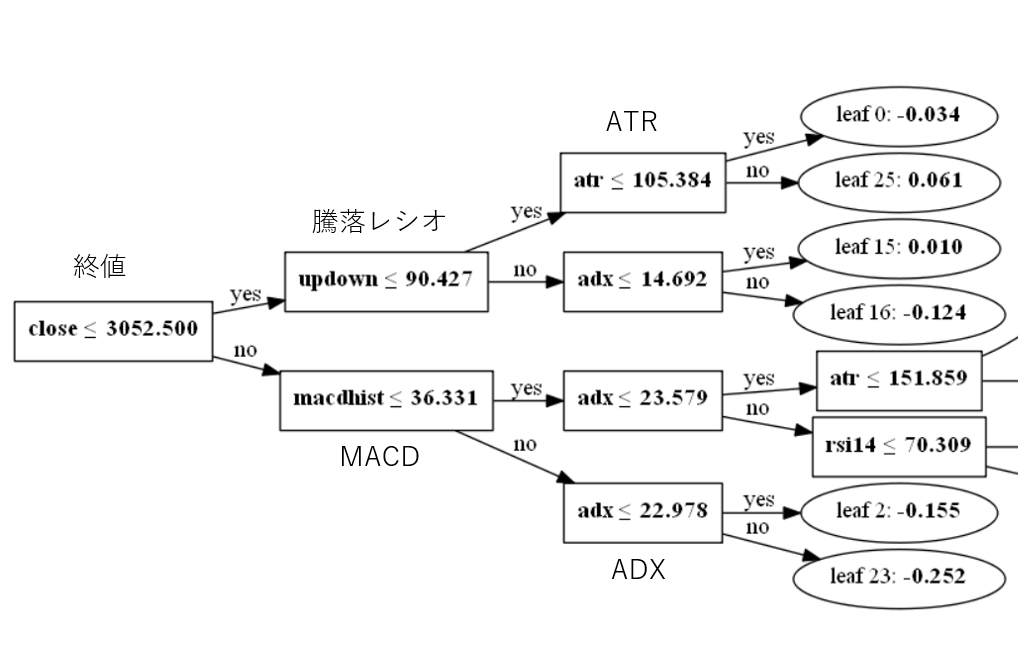
コードで書くとこんな感じかな・・・。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
if close <= 3052.500: if updown <= 90.427: if atr <= 105.384: target = -0.034 else: target = 0.061 else: if adx <= 14.692: target = 0.010 else: target = -0.124 else: if macdhist <= 36.331: if adx <= 23.579: ....(省略) else ....(省略) |
システムトレードの世界では、このような複雑な分岐は過学習(オーバーフィッティング)そのものです。
そして、フォワードテストは分岐のどこかに落ちるので、過去に存在しない相場だと厳しいだろうね・・・。
まとめ
可視化して分かったことは厳しい現実です。
勾配ブースティングを用いた機械学習による株価予測は、昔のシステムトレードの手法より乱暴な気がします。
こんな手法で全パラメータを分析して本当に勝てるのかなぁ・・・。
・・・で終わったら「魅せる化」しただけになってしまいます。
次にやるべきこと(アクション)は、
- max_depth等を指定して決定木が深くならないよう調整する
- システムトレードで導入してきた(有効だと思われる)組み合わせテクニカル指標を追加する
が最初だと分かりました。

