
11回目ではファンダメンタルズ指標を追加することで「AUC=0.70」を超えました。
13回目では過学習(オーバーフィッティング)を抑え学習モデルを可視化しました。
- 【13回目】機械学習を使った株価予測(LightGBMをOptunaでパラメータチューニング)
- 【12回目】機械学習を使った株価予測(pandas-profiling、create_tree_digraphで可視化する)
- 【11回目】機械学習を使った株価予測(ファンダメンタルズ指標導入でAUC=0.70超え)
- 【10回目】機械学習を使った株価予測(関連論文・サイトを調査してみる)
- 【9回目】機械学習で株価予測(年利・勝率向上の分析)
- 【8回目】機械学習で株価予測(交差検証+ROC 曲線とAUCで脱過学習)
- 【7回目】機械学習で株価予測(騰落レシオ+株価分割対応で複数銘柄)
これは、果敢にも人類の夢「株の自動売買で億り人」に挑戦し、詰みかけている一人の中年男の物語です。
前回までで銘柄毎の分類器を作ることは、過学習に陥る可能性が高い事が分かりました。
今回は、交差検証で作成された学習モデルを保存し、日経225採用銘柄に適用してみます。
一般的なシステムトレードに近い形です。
交差検証の学習モデルの保存・ロード方法
一般的な交差検証のサンプルル実装は次のようになっています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
import pandas as pd import numpy as np from sklearn.metrics import roc_auc_score from sklearn.model_selection import KFold from lightgbm import LGBMClassifier import gc data = pd.DataFrame({'date' : ['1/1','1/2','1/3','1/4','1/5','1/6','1/7','1/8','1/9','1/10','1/11','1/12'], 'close' : [300,100,400,500,600,700,400,500,600,100,400,500], 'volume' : [10, 13, 16, 30, 33, 66,10, 13, 16,10, 13, 16], 'TARGET' : [1, 0, 1,0, 1, 0, 1, 0, 1,0, 1, 0] }, ) test = pd.DataFrame({'date' : ['1/1','1/2','1/3','1/4','1/5','1/6','1/7','1/8','1/9','1/10','1/11','1/12'], 'close' : [300,100,400,500,600,700,400,500,600,100,400,500], 'volume' : [10, 13, 16, 30, 33, 66,10, 13, 16,10, 13, 16] } ) y = data['TARGET'] del data['TARGET'] excluded_feats = ['date'] features = [f_ for f_ in data.columns if f_ not in excluded_feats] # Modeling folds = KFold(n_splits=5, shuffle=True, random_state=123) oof_preds = np.zeros(data.shape[0]) sub_preds = np.zeros(test.shape[0]) for n_fold, (trn_idx, val_idx) in enumerate(folds.split(data)): trn_x, trn_y = data[features].iloc[trn_idx], y.iloc[trn_idx] val_x, val_y = data[features].iloc[val_idx], y.iloc[val_idx] clf = LGBMClassifier() clf.fit(trn_x, trn_y, eval_set= [(trn_x, trn_y), (val_x, val_y)], eval_metric='auc', verbose=250, early_stopping_rounds=150) oof_preds[val_idx] = clf.predict_proba(val_x, num_iteration=clf.best_iteration_)[:, 1] sub_preds += clf.predict_proba(test[features], num_iteration=clf.best_iteration_)[:, 1] / folds.n_splits print('Fold %2d AUC : %.6f' % (n_fold + 1, roc_auc_score(val_y, oof_preds[val_idx]))) del clf, trn_x, trn_y, val_x, val_y gc.collect() print('Full AUC score %.6f' % roc_auc_score(y, oof_preds)) test['TARGET'] = sub_preds test[['date', 'TARGET']].to_csv('submission.csv', index=False, float_format='%.8f') |
学習モデル構築中にテストデータも検証しています。
そして分割数で割っています・・・これは何だろう?
|
1 |
sub_preds += clf.predict_proba(test[features], num_iteration=clf.best_iteration_)[:, 1] / folds.n_splits |
今回の例では、交差検証のために「学習データ」と「検証データ」に5回分割を試みました。
それぞれの学習により構築された「学習モデル」を使って「テストデータ」を予測し「分割数」で割ることで平均値を取っているようです。
これが正しいのであれば各学習モデルを保存し、「テストデータ」に適用して「分割数」で割ってあげるだけです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
import pandas as pd import numpy as np from sklearn.metrics import roc_auc_score from sklearn.model_selection import KFold from lightgbm import LGBMClassifier import gc data = pd.DataFrame({'date' : ['1/1','1/2','1/3','1/4','1/5','1/6','1/7','1/8','1/9','1/10','1/11','1/12'], 'close' : [300,100,400,500,600,700,400,500,600,100,400,500], 'volume' : [10, 13, 16, 30, 33, 66,10, 13, 16,10, 13, 16], 'TARGET' : [1, 0, 1,0, 1, 0, 1, 0, 1,0, 1, 0] }, ) test = pd.DataFrame({'date' : ['1/1','1/2','1/3','1/4','1/5','1/6','1/7','1/8','1/9','1/10','1/11','1/12'], 'close' : [300,100,400,500,600,700,400,500,600,100,400,500], 'volume' : [10, 13, 16, 30, 33, 66,10, 13, 16,10, 13, 16] } ) def load_model(num): clf = None file = "test" + str(num) + ".pickle" if os.path.exists(file): with open(file, mode='rb') as fp: clf = pickle.load(fp) return clf def save_model(num, clf): with open("test" + str(num) + ".pickle", mode='wb') as fp: pickle.dump(clf, fp, protocol=2) y = data['TARGET'] del data['TARGET'] excluded_feats = ['date'] features = [f_ for f_ in data.columns if f_ not in excluded_feats] # Modeling folds = KFold(n_splits=5, shuffle=True, random_state=123) oof_preds = np.zeros(data.shape[0]) for n_fold, (trn_idx, val_idx) in enumerate(folds.split(data)): trn_x, trn_y = data[features].iloc[trn_idx], y.iloc[trn_idx] val_x, val_y = data[features].iloc[val_idx], y.iloc[val_idx] clf = LGBMClassifier() clf.fit(trn_x, trn_y, eval_set= [(trn_x, trn_y), (val_x, val_y)], eval_metric='auc', verbose=250, early_stopping_rounds=150) oof_preds[val_idx] = clf.predict_proba(val_x, num_iteration=clf.best_iteration_)[:, 1] save_model(n_fold, clf) print('Fold %2d AUC : %.6f' % (n_fold + 1, roc_auc_score(val_y, oof_preds[val_idx]))) del clf, trn_x, trn_y, val_x, val_y gc.collect() print('Full AUC score %.6f' % roc_auc_score(y, oof_preds)) sub_preds = np.zeros(test.shape[0]) for num in range(5): clf = load_model(num) sub_preds += clf.predict_proba(test[features], num_iteration=clf.best_iteration_)[:, 1] / folds.n_splits test['TARGET'] = sub_preds test[['date', 'TARGET']].to_csv('submission.csv', index=False, float_format='%.8f') |
結果を見る限り同じ結果が得られたので正しいと仮定して、日経平均255採用銘柄を使って確認してみます。
バックテスト結果
日経255採用銘柄に対してmax_depth=4で正解率60%を抽出してバックテストした検証結果は次のとおりです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
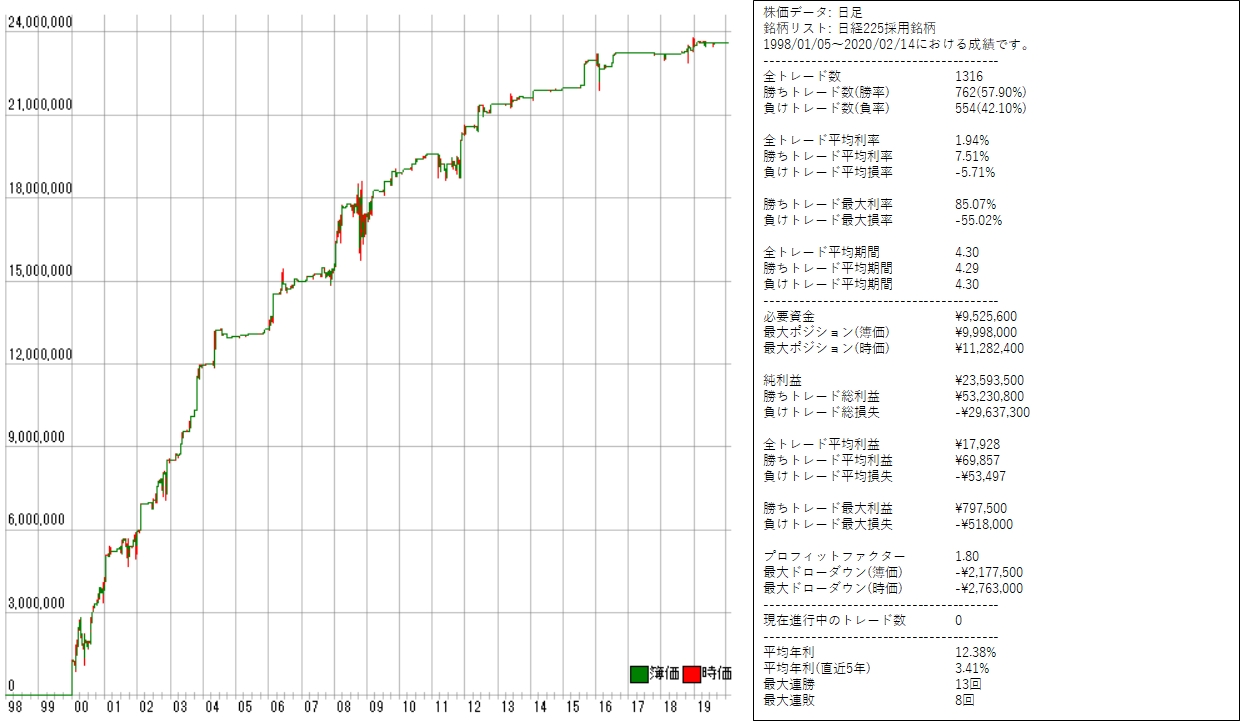
株価データ: 日足 銘柄リスト: 日経225採用銘柄 1998/01/05~2020/02/14における成績です。 ---------------------------------------- 全トレード数 193 勝ちトレード数(勝率) 99(51.30%) 負けトレード数(負率) 94(48.70%) 全トレード平均利率 1.32% 勝ちトレード平均利率 10.49% 負けトレード平均損率 -8.34% 勝ちトレード最大利率 85.07% 負けトレード最大損率 -29.73% 全トレード平均期間 4.37 勝ちトレード平均期間 4.61 負けトレード平均期間 4.13 ---------------------------------------- 必要資金 ¥9,762,600 最大ポジション(簿価) ¥9,846,100 最大ポジション(時価) ¥10,872,000 純利益 ¥2,621,100 勝ちトレード総利益 ¥9,793,100 負けトレード総損失 -¥7,172,000 全トレード平均利益 ¥13,581 勝ちトレード平均利益 ¥98,920 負けトレード平均損失 -¥76,298 勝ちトレード最大利益 ¥797,500 負けトレード最大損失 -¥281,700 プロフィットファクター 1.37 最大ドローダウン(簿価) -¥2,653,800 最大ドローダウン(時価) -¥3,472,800 ---------------------------------------- 現在進行中のトレード数 0 ---------------------------------------- 平均年利 2.24% 平均年利(直近5年) 0.56% 最大連勝 8回 最大連敗 11回 ---------------------------------------- [年度別レポート] 年度 取引回数 運用損益 年利 勝率 PF 最大DD 2018年 1回 ¥13,500円 0.14% 100.00% ∞倍 0.00% 2016年 1回 ¥52,800円 0.54% 100.00% ∞倍 0.00% 2011年 8回 -¥383,900円 -3.93% 12.50% 0.48倍 -29.53% 2009年 2回 ¥319,000円 3.27% 100.00% ∞倍 0.00% 2008年 83回 ¥270,100円 2.77% 54.22% 1.06倍 -29.73% 2007年 52回 -¥80,600円 -0.83% 50.00% 0.93倍 -9.72% 2006年 2回 ¥57,500円 0.59% 100.00% ∞倍 0.00% 2004年 2回 ¥225,500円 2.31% 100.00% ∞倍 0.00% 2003年 1回 ¥235,200円 2.41% 100.00% ∞倍 0.00% 2002年 2回 -¥9,000円 -0.09% 0.00% 0.00倍 -0.85% 2001年 4回 ¥716,400円 7.34% 75.00% 60.70倍 -1.10% 2000年 35回 ¥1,204,600円 12.34% 51.43% 2.45倍 -28.01% |
利益曲線は次のとおりです。

糞じゃねーか!!!
max_depth=2で色々と実験してみる
このままでは引き下がれないので、max_depth=2にして入力データを変えながら実験してみます。
もはや機械学習でも何でもなく、
- 株価予測には重要な指標とパラメーターは何なのか?
- そのストラテジーの構築方法は?
を確認しているに過ぎません。
1998/01/05~2015/12/14 を学習データに使った場合
日経255採用銘柄に対してmax_depth=2で正解率60%を抽出してバックテストした検証結果 (skiprows=0, skipfooter=1000)は次のとおりです。
|
1 |
Full AUC score 0.708943 |
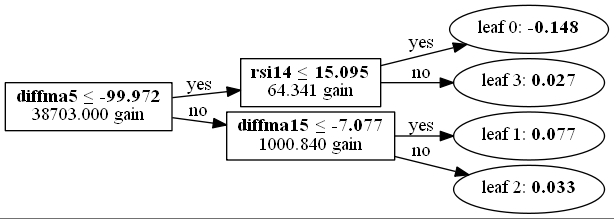
学習モデル(5つの交差検証の一つ)は次のとおりです。
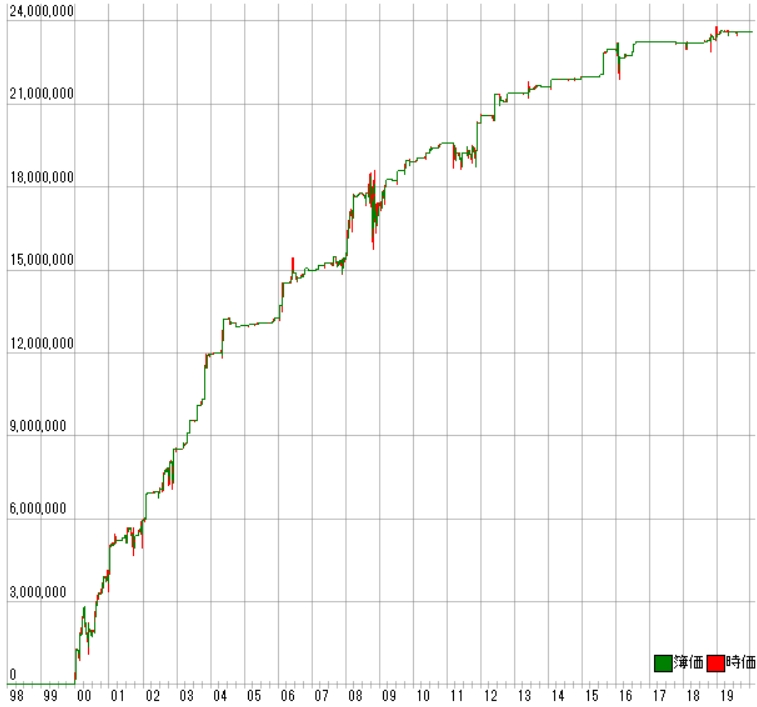
利益曲線は次のとおりです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
[年度別レポート] 年度 取引回数 運用損益 年利 勝率 PF 最大DD 2019年 39回 ¥180,700円 1.90% 48.72% 1.32倍 -5.61% 2018年 39回 ¥205,000円 2.15% 64.10% 1.35倍 -10.96% 2017年 1回 -¥39,600円 -0.42% 0.00% 0.00倍 -4.10% 2016年 48回 ¥280,600円 2.95% 47.92% 1.23倍 -13.13% 2015年 17回 ¥995,500円 10.45% 82.35% 33.01倍 -1.92% 2014年 18回 ¥343,400円 3.61% 83.33% 4.37倍 -5.69% 2013年 29回 ¥240,600円 2.53% 51.72% 1.70倍 -4.59% 2012年 47回 ¥1,062,200円 11.15% 59.57% 2.04倍 -10.90% 2011年 81回 ¥726,900円 7.63% 46.91% 1.22倍 -55.02% 2010年 24回 ¥677,000円 7.11% 91.67% 7.34倍 -8.96% 2009年 77回 ¥1,507,100円 15.82% 59.74% 2.04倍 -21.95% 2008年 253回 ¥2,029,400円 21.30% 53.36% 1.24倍 -28.91% 2007年 86回 ¥380,100円 3.99% 53.49% 1.22倍 -13.61% 2006年 54回 ¥1,751,200円 18.38% 70.37% 4.03倍 -11.03% 2005年 7回 ¥263,200円 2.76% 71.43% 31.60倍 -0.68% 2004年 32回 ¥1,017,800円 10.68% 75.00% 2.71倍 -14.14% 2003年 52回 ¥3,437,600円 36.09% 76.92% 10.24倍 -8.65% 2002年 95回 ¥2,593,000円 27.22% 64.21% 2.40倍 -23.08% 2001年 151回 ¥1,884,100円 19.78% 60.93% 1.56倍 -30.05% 2000年 166回 ¥4,057,700円 42.60% 60.24% 2.00倍 -28.01% |
2006/02/20~2019/10/24 を学習データに使った場合
日経255採用銘柄に対してmax_depth=2で正解率60%を抽出してバックテストした検証結果 (skiprows=2000, skipfooter=60)は次のとおりです。
|
1 |
Full AUC score 0.619744 |
学習モデル(5つの交差検証の一つ)は次のとおりです。
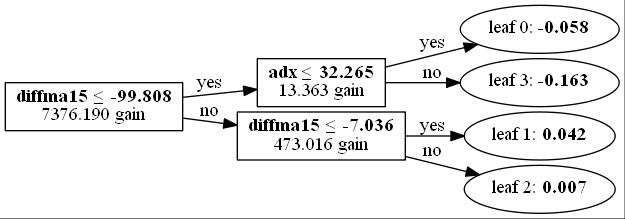
利益曲線は次のとおりです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
[年度別レポート] 年度 取引回数 運用損益 年利 勝率 PF 最大DD 2019年 16回 -¥18,000円 -0.18% 37.50% 0.94倍 -6.59% 2018年 31回 ¥998,800円 10.23% 74.19% 3.58倍 -11.08% 2017年 1回 -¥39,600円 -0.41% 0.00% 0.00倍 -4.10% 2016年 55回 -¥361,800円 -3.71% 43.64% 0.75倍 -17.82% 2015年 26回 ¥1,119,600円 11.47% 80.77% 26.22倍 -1.62% 2014年 5回 ¥80,800円 0.83% 100.00% ∞倍 0.00% 2013年 17回 ¥732,000円 7.50% 88.24% 23.88倍 -3.17% 2012年 41回 ¥782,400円 8.01% 56.10% 1.97倍 -14.26% 2011年 59回 ¥1,603,900円 16.43% 61.02% 1.94倍 -40.44% 2010年 18回 ¥369,600円 3.79% 77.78% 3.32倍 -6.65% 2009年 164回 ¥1,638,700円 16.79% 61.59% 1.46倍 -26.30% 2008年 357回 -¥1,569,700円 -16.08% 44.82% 0.86倍 -28.91% 2007年 127回 ¥72,300円 0.74% 55.91% 1.03倍 -14.04% 2006年 102回 ¥1,728,600円 17.71% 66.67% 2.68倍 -11.58% 2005年 1回 ¥132,000円 1.35% 100.00% ∞倍 0.00% 2004年 36回 ¥776,000円 7.95% 61.11% 2.01倍 -10.30% 2003年 30回 ¥1,222,300円 12.52% 63.33% 2.70倍 -17.05% 2002年 68回 ¥2,381,000円 24.39% 66.18% 2.72倍 -22.22% 2001年 147回 ¥2,289,900円 23.46% 59.18% 1.62倍 -25.44% 2000年 296回 ¥2,459,200円 25.19% 50.68% 1.27倍 -28.01% |
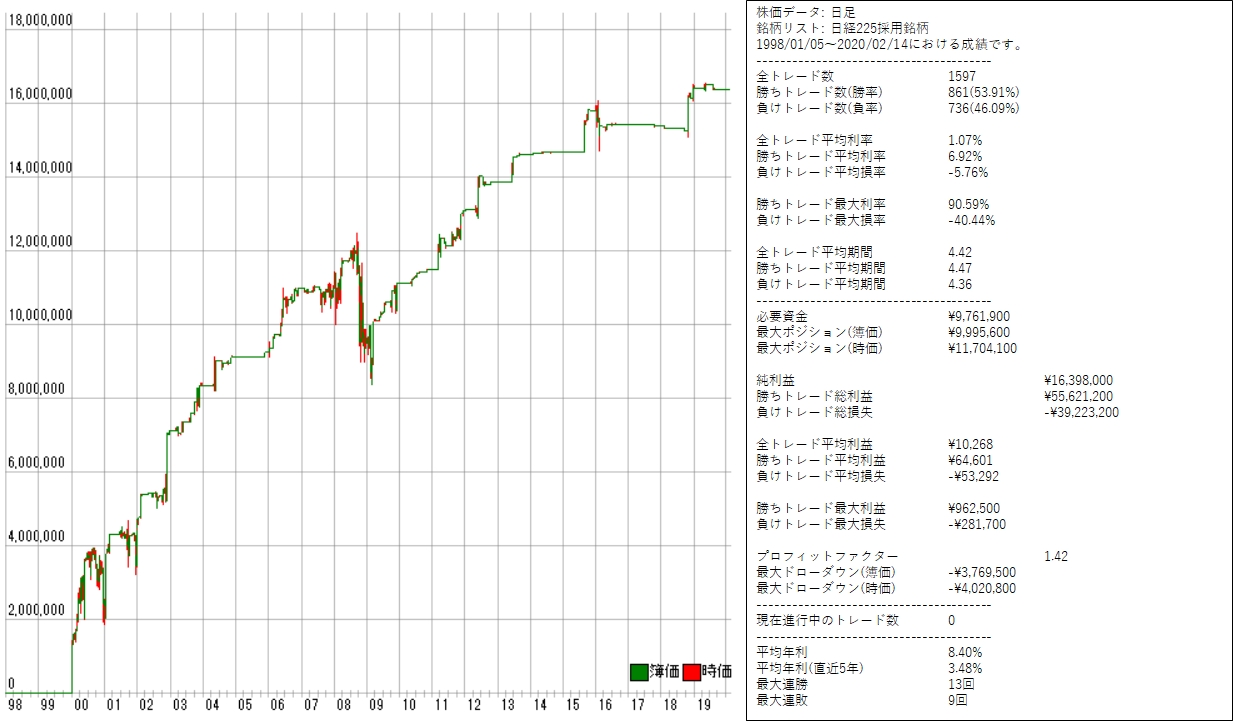
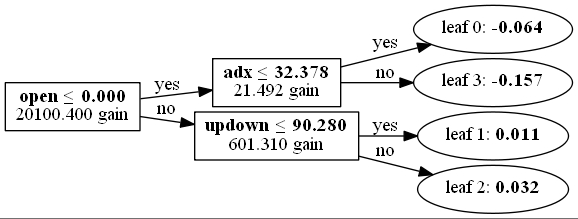
2002/01/25~2019/10/24 を学習データに使った場合
日経255採用銘柄に対してmax_depth=2で正解率60%を抽出してバックテストした検証結果 (skiprows=1000, skipfooter=60)は次のとおりです。
|
1 |
Full AUC score 0.662221 |
学習モデル(5つの交差検証の一つ)は次のとおりです。
利益曲線は次のとおりです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
[年度別レポート] 年度 取引回数 運用損益 年利 勝率 PF 最大DD 2020年 1回 -¥27,000円 -0.33% 0.00% 0.00倍 -2.61% 2019年 79回 -¥128,100円 -1.55% 45.57% 0.89倍 -11.61% 2018年 98回 -¥694,500円 -8.39% 39.80% 0.65倍 -10.76% 2017年 32回 ¥151,400円 1.83% 59.38% 1.50倍 -7.77% 2016年 144回 ¥1,736,800円 20.97% 54.86% 1.80倍 -18.47% 2015年 83回 ¥1,380,300円 16.67% 65.06% 2.72倍 -9.94% 2014年 26回 ¥709,200円 8.56% 76.92% 5.74倍 -6.70% 2013年 6回 ¥150,900円 1.82% 66.67% 5.19倍 -2.72% 2012年 29回 ¥91,300円 1.10% 37.93% 1.11倍 -9.98% 2011年 52回 -¥607,700円 -7.34% 46.15% 0.78倍 -55.02% 2010年 16回 ¥212,400円 2.56% 75.00% 2.38倍 -8.96% 2009年 36回 ¥543,100円 6.56% 63.89% 1.98倍 -9.98% 2008年 117回 -¥234,400円 -2.83% 52.99% 0.95倍 -29.73% 2007年 30回 ¥275,100円 3.32% 56.67% 1.53倍 -14.04% 2006年 8回 -¥99,500円 -1.20% 25.00% 0.51倍 -7.46% 2005年 16回 ¥369,900円 4.47% 68.75% 4.04倍 -3.92% 2004年 76回 ¥4,600円 0.06% 56.58% 1.00倍 -22.58% 2003年 121回 ¥3,144,200円 37.97% 65.29% 2.51倍 -22.94% 2002年 87回 ¥1,755,900円 21.20% 66.67% 2.09倍 -16.84% 2001年 118回 ¥1,620,000円 19.56% 63.56% 1.74倍 -30.05% 2000年 96回 ¥751,100円 9.07% 46.88% 1.20倍 -40.04% |
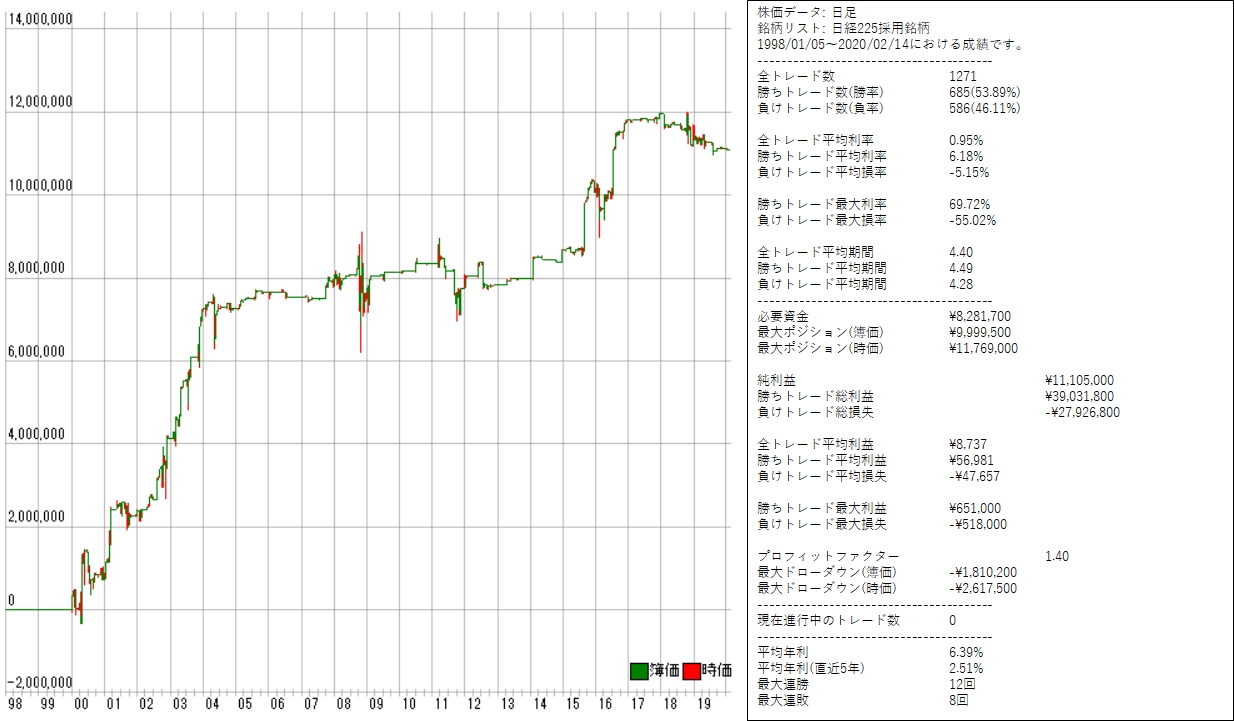
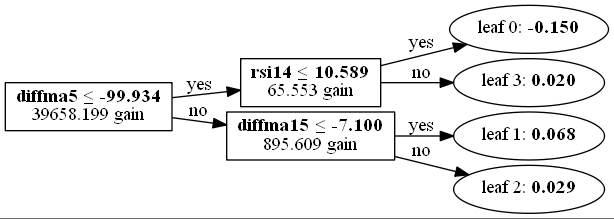
1998/01/05~2020/01/24 を学習データに使った場合
日経255採用銘柄に対してmax_depth=2で正解率60%を抽出してバックテストした検証結果 (skiprows=0, skipfooter=0)は次のとおりです。
|
1 |
Full AUC score 0.693274 |
学習モデル(5つの交差検証の一つ)は次のとおりです。
利益曲線は次のとおりです。
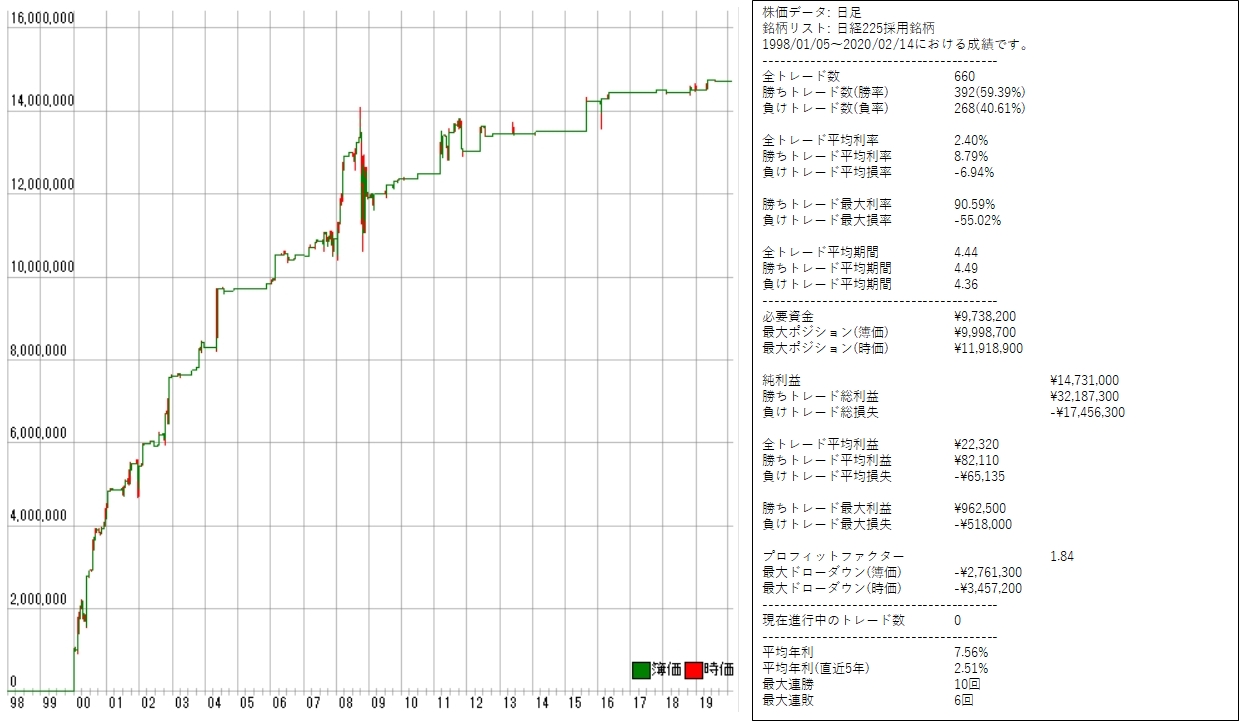
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
[年度別レポート] 年度 取引回数 運用損益 年利 勝率 PF 最大DD 2019年 9回 ¥217,100円 2.23% 66.67% 3.65倍 -4.23% 2018年 6回 ¥7,800円 0.08% 66.67% 1.06倍 -6.59% 2017年 1回 ¥54,000円 0.55% 100.00% ∞倍 0.00% 2016年 14回 ¥207,900円 2.13% 42.86% 1.66倍 -6.98% 2015年 11回 ¥734,700円 7.54% 90.91% 132.20倍 -0.57% 2014年 3回 ¥51,700円 0.53% 100.00% ∞倍 0.00% 2013年 8回 ¥1,600円 0.02% 50.00% 1.01倍 -4.59% 2012年 13回 ¥423,400円 4.35% 53.85% 2.42倍 -10.12% 2011年 35回 ¥542,600円 5.57% 60.00% 1.25倍 -55.02% 2010年 3回 ¥122,500円 1.26% 100.00% ∞倍 0.00% 2009年 20回 ¥450,300円 4.62% 55.00% 1.84倍 -21.95% 2008年 217回 ¥1,009,100円 10.36% 55.76% 1.13倍 -28.91% 2007年 87回 ¥385,700円 3.96% 52.87% 1.20倍 -14.06% 2006年 12回 ¥682,000円 7.00% 75.00% 5.50倍 -11.03% 2005年 1回 ¥132,000円 1.36% 100.00% ∞倍 0.00% 2004年 25回 ¥1,409,200円 14.47% 76.00% 5.12倍 -10.20% 2003年 15回 ¥688,300円 7.07% 66.67% 3.88倍 -13.31% 2002年 37回 ¥2,182,900円 22.42% 75.68% 4.57倍 -18.42% 2001年 61回 ¥1,001,900円 10.29% 59.02% 1.61倍 -38.18% 2000年 82回 ¥4,426,300円 45.45% 67.07% 4.17倍 -28.01% |
考察
ここまでの実験が正しいのであれば、導ける結果は次のとおりです。
- 5日間移動平均との乖離率は重要な指標
- 15日間移動平均との乖離率は重要な指標
- (日経255採用銘柄のみの考察だが)逆張りは有効
と、機械学習は教えてくれました。
そして、これは「斉藤正章氏の逆張り手法」とほぼ同じストラテジーです。
まとめ
一ヶ月かけて機械学習で作成できたストラテジーは斉藤正章氏の手法でした・・・。

そして、今回の取り組みで作成したストラテジーは、次のような魅力の無いものです。
- 勝率60%未満
- プロフィットファクター2.0未満
- 年利5%未満
また、案の定Log関数のような利益曲線となりました。
手動のストラテジーのパラメータ調整やどの指標を使うべきか?の支援ツールとしては意味がありそうです・・・どこかの会社が作りそうですね。
要するに、作ったストラテジーに、あとは何の指標を追加すれば勝率が上がるか?最適なパラメーターは何?を自動的に出力はできそうです。

