
統計学や人工知能(AI)を駆使してデータを分析し、課題の発見や解決に導く「データサイエンス」教育に力を入れる大学が増えてきたそうです。
データサイエンス教育拡大 AI駆使しデータ分析、人材育成へ大学注力
東北大の滝沢博胤副学長(教育・学生支援担当)は「これからの世の中はあらゆる場で膨大なデータから必要な情報を取り出して最適な答えを見つける能力が求められる。デジタル社会に必要な素養を養い、社会で活躍する人材を輩出したい」と話している。
2019.12.16 12:40 SankeiBiz(サンケイビズ)
違う部署に行っても生きていけるように学習を続けよう。
ディープラーニングが注目されていますが万能であるとは言えません。
用意したデータの数が少ない場合や、解決したい問題によっては、ディープラーニング以外の機械学習アルゴリズムのほうが適している場合があります。
Scikit-learnにはこれらの機械学習アルゴリズムが多く実装されているため、様々なアルゴリズムを使用したAI(人工知能)を作成できます。
- 【3回目】Kaggle の Titanic Prediction Competition で機械学習を習得(Keras Functional API編)
- 【2回目】Kaggle の Titanic Prediction Competition で機械学習を習得(Jupyter Notebook編)
- 【1回目】Kaggle の Titanic Prediction Competition で機械学習を習得(Keras導入編)
scikit-learnって何?何ができるの?
scikit-learnは、Pythonの機械学習ライブラリです。「サイキット・ラーン」と読みます。
scikit-learnを用いて機械学習を行う際、自分が行いたい分析(分類/回帰/クラスタリングなど)について、適切なモデルを選択します。
「scikit-learn アルゴリズム・チートシート」を見れば、大まかにできる事を把握できます。
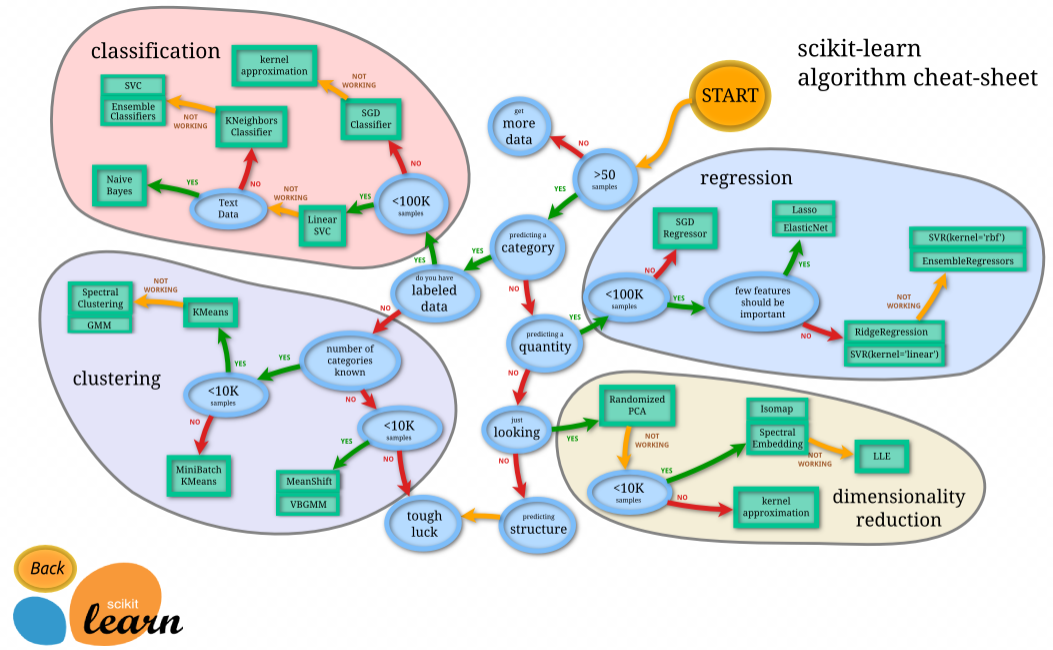
- クラス分類 (Classification) – 教師あり学習。人が正解ラベル(クラス)をつけたデータを学習し、新しい入力データに対してのクラスを予測する
- 回帰 (Regression) – 教師あり学習。人が正解ラベル(実数値)をつけたデータを学習して、新しい入力データに対しての実数値を予測する
- クラスタリング (Clustering) – 教師なし学習。入力データを任意の数のクラスター(グループ)にまとめて、近しいデータを発見する
- 次元削減 (Dimensionality reduction) – データの次元を削減して、要因分析をしたり、機械学習のための前処理を行なう
scikit-learnで利用可能な分類目的の機械学習モデル一覧
どれもSupervised Machine Learning(教師あり学習)となります。
| モデル名 | 説明 |
|---|---|
| LogisticRegression(ロジスティック回帰) | 2群で分けられた目的変数(従属変数)に対する,1つ以上の説明変数(独立変数)の影響を調べる統計解析手法。損失関数がパーセプトロンとは異なり、正しい値でも一部を損失に含める |
| LinearSVC(線形SVM) | カーネル関数に線形関数を使うクラス分け用のSVM |
| NuSVC | 使うサポートベクターの数を制限したSVC |
| Perceptron(パーセプトロン) | 損失関数は、正の値の際には変更しない。 基本は単独では使わない。線形識別の場合、ロジスティック回帰が基本使われる |
| SVC(SVM:サポートベクターマシン) | 損失関数はパーセプトロンに類似しているが、正の値でも少しだけ損失を加える。識別境界に近いものは損失を加える。線形非線形があり、非線形がよく使われる。線形の場合、LinearSVCを使う(RBFカーネル) |
| GaussianNB | Gaussian型Naive Bayes。ベイズの定理をもとにした学習アルゴリズム |
| AdaBoostClassifier(アダブースト) | 前の弱学習器で誤って識別されたサンプルに対する重みを大きく、正しく識別されたサンプルに対する重みを小さくすることで、誤って識別されやすいサンプルを集中的に学習する |
| ExtraTreesClassifier | 特徴量の重要度を特に評価したい場合 |
| GradientBoostingClassifier(勾配ブースティング決定木) | アンサンブル学習の一つ。損失関数の勾配を用いたブースティングで弱学習器に決定木を用いる |
| RandomForestClassifier(ランダムフォレスト) | 学習データから木の構造を学習し、その構造を元にし、テストデータを予測するアルゴリズム。精度の高い分類モデルを作りたい場合 |
| BaggingClassifier | バギング分類。ランダムに生成された訓練セットの分類を組み合わせることによって分類を改善する |
| PassiveAggressiveClassifier | データを正しく分類できたら重みを更新せず(Passive)、データを誤分類したら、そのデータを正しく分類できる最小限の量だけ重みを更新します(Aggressive)。Gmailの優先トレイで使っている |
| RidgeClassifier | リッジ分類 |
| SGDClassifier(SGD:確率的勾配降下法) | Stochastic Gradient Descent。続最適化問題に対する勾配法の乱択アルゴリズム。目的関数が、微分可能な和の形である事が必要 |
| GaussianProcessClassifier (ナイーブベイズのガウス分布) | 正規分布を利用した回帰分析手法 |
| KNeighborsClassifier(K近傍法) | 最も近いものを探索し、最も数が多いクラスをその予測データのクラスとする |
| RadiusNeighborsClassifier | ある半径の中に入っているもののサンプルで多数決を取る |
| DecisionTreeClassifier(決定木) | データに対して、次々と条件を定義していき、その一つ一つの条件に沿って分類していく方法 |
| ExtraTreeClassifier(エクストラツリー分類器) | |
| MLPClassifier(MLP:多層パーセプトロン) | Multilayer perceptron。少なくとも3つのノードの層からなる 入力ノードを除けば、個々のノードは非線形活性化関数を使用するニューロン |
まとめてみましたが、よく分かりません。
ソースコード
Scikit-learnを使った機械学習は簡単です。
データクレンジングが完了した学習用データに対して次のような2行を呼ぶだけです(ランダムフォレストでオプションが無い場合)。
|
1 2 |
forest = RandomForestClassifier() forest.fit(x_train, y_train) |
学習モデルを一気に試すのであれば次のような実装になります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 |
import time import numpy as np import pandas as pd from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LinearRegression,Perceptron,LogisticRegression,PassiveAggressiveClassifier,RidgeClassifier,SGDClassifier from sklearn.svm import LinearSVC,NuSVC,SVC from sklearn.ensemble import AdaBoostClassifier,ExtraTreesClassifier,GradientBoostingClassifier,RandomForestClassifier, BaggingClassifier from sklearn.gaussian_process import GaussianProcessClassifier from sklearn.neighbors import KNeighborsClassifier,RadiusNeighborsClassifier from sklearn.tree import DecisionTreeClassifier,ExtraTreeClassifier from sklearn.neural_network import MLPClassifier from sklearn.naive_bayes import GaussianNB # Data Cleansing def normalize_data(data): data = data.drop(["PassengerId", "Name", "Ticket", "Cabin"], axis=1) # Changing the name of Column (PClass) to (TicketClass) for easy understanding data = data.rename(columns = {"Pclass":"TicketClass"}) # Complement the missing values of "Age" column with average of "Age" data["Age"] = data["Age"].fillna(data["Age"].mean()) # 全てのAgeを平均 0 標準偏差 1になるように標準化 scaler = StandardScaler() data["Age"] = scaler.fit_transform(data["Age"].values.reshape(-1, 1)) # Complement the missing values of "Fare" column with average of "Fare" data["Fare"] = data["Fare"].fillna(data["Fare"].mean()) # Convert "Sex" to be a dummy variable (female = 0, Male = 1) data["Sex"] = data["Sex"].replace(["male", "female"], [0, 1]) # Convert "Embarked" to be a dummy variable (S = 0,C = 1, Q = 2) data["Embarked"] = data["Embarked"].fillna("S") data["Embarked"] = data["Embarked"].replace(["C", "S", "Q"], [0, 1, 2]) return data # 学習用データ x_data、検証用結果 y_data の割り当て def build_train_test_data(data, rate=0.8): # 答えの削除 y_data = data["Survived"] x_data = data.drop(["Survived"], axis=1) # 全データのうち、80% を学習用データ、20% を検証用データに割り当て train_size = int(len(x_data) * 0.8) # 80% を学習用データ x_train = x_data[:train_size] # Inputs y_train = y_data[:train_size] # Output (Survived) # 20% // 2 小数点以下は切り捨て valid_test_size = (len(x_data) - train_size) // 2 # 10% を検証用テストデータ x_test = x_data[valid_test_size + train_size:] y_test = y_data[valid_test_size + train_size:] # 作成した行列出力 print("x_train:{}".format(x_train.shape)) print("y_train:{}".format(y_train.shape)) print("x_test:{}".format(x_test.shape)) print("y_test:{}".format(y_test.shape)) return x_train, y_train, x_test, y_test clf_names = [#"LinearRegression", # LinearRegression(線形回帰) "LogisticRegression", # LogisticRegression(ロジスティック回帰) "LinearSVC", # カーネル関数に線形関数を使うクラス分け用のSVM "NuSVC", # Nu-Support Vector Classification "Perceptron", # Perceptron(パーセプトロン) "SVC", # Support Vector Machine Classification(RBFカーネル) "GaussianNB", # Gaussian型Naive Bayes "AdaBoostClassifier", # AdaBoost(アダブースト) "ExtraTreesClassifier", # エクストラツリー分類器 "GradientBoostingClassifier", # Gradient Boosting Classifier(勾配ブースティング決定木) "RandomForestClassifier", # Random Forest(ランダムフォレスト) "BaggingClassifier", # バギング分類 "PassiveAggressiveClassifier", # Passive-Aggressive (PA)分類 "RidgeClassifier", # リッジ分類 "SGDClassifier", # Stochastic Gradient Descent(SGD:確率的勾配降下法) "GaussianProcessClassifier", # Gaussian Naive Bayes (ナイーブベイズのガウス分布版) "KNeighborsClassifier", # kNN (K近傍法) # "RadiusNeighborsClassifier", # ある半径の中に入っているもののサンプルで多数決を取る "DecisionTreeClassifier", # Decision Tree(決定木) "ExtraTreeClassifier", # エクストラツリー分類器 "MLPClassifier", # Multilayer perceptron(MLP:多層パーセプトロン) ] def sklearn_model(x_train, y_train): start = time.time() models = list() model = None # もっと精度が高いモデル total = 0.0 name = "" for clf_name in clf_names: clf = eval("%s()" % clf_name) clf.fit(x_train, y_train) score = clf.score(x_train, y_train) print('%s Accuracy:' % clf_name, score) models.append(clf) if total <= score: total = score model = clf name = clf_name print(str(time.time() - start)) print('%s was selected' % name) return models, model from sklearn.metrics import confusion_matrix def output(model, x_test, y_test): for i in range(len(model)): cm = confusion_matrix(y_test.ravel(), model[i].predict(x_test)) #extracting TN, FP, FN, TP TN, FP, FN, TP = confusion_matrix(y_test, model[i].predict(x_test)).ravel() print(cm) print('Model[{}] Testing Accuracy = "{} !"'.format(i, (TP + TN) / (TP + TN + FN + FP))) print()# Print a new line def main(): # CSVを読み込む df_train = pd.read_csv("train.csv") normalized_data = normalize_data(df_train) x_train, y_train, x_test, y_test = build_train_test_data(normalized_data, 0.8) models, model = sklearn_model(x_train, y_train) output(models, x_test, y_test) # テスト値を読み込み df_out = pd.read_csv("test.csv") predictions = model.predict(normalize_data(df_out)) df_out["Survived"] = np.round(predictions).astype(np.int) # CSVに出力する df_out[["PassengerId","Survived"]].to_csv("submission.csv",index = False) main() |
計算結果と正解率
出力結果です。
精度確認
出力される精度は毎回異なります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
x_train:(712, 7) y_train:(712,) x_test:(90, 7) y_test:(90,) LinearRegression Accuracy: 0.3811283794061753 LogisticRegression Accuracy: 0.7935393258426966 LinearSVC Accuracy: 0.7668539325842697 NuSVC Accuracy: 0.8792134831460674 Perceptron Accuracy: 0.7275280898876404 SVC Accuracy: 0.851123595505618 GaussianNB Accuracy: 0.7879213483146067 AdaBoostClassifier Accuracy: 0.8314606741573034 ExtraTreesClassifier Accuracy: 0.9817415730337079 GradientBoostingClassifier Accuracy: 0.901685393258427 RandomForestClassifier Accuracy: 0.9662921348314607 BaggingClassifier Accuracy: 0.9676966292134831 PassiveAggressiveClassifier Accuracy: 0.7050561797752809 RidgeClassifier Accuracy: 0.7907303370786517 SGDClassifier Accuracy: 0.6643258426966292 GaussianProcessClassifier Accuracy: 0.9101123595505618 KNeighborsClassifier Accuracy: 0.8370786516853933 RadiusNeighborsClassifier Accuracy: 0.9073033707865169 DecisionTreeClassifier Accuracy: 0.9817415730337079 ExtraTreeClassifier Accuracy: 0.9817415730337079 MLPClassifier Accuracy: 0.797752808988764 1.5192022323608398 ExtraTreeClassifier was selected |
決定木やランダムフォレストの正解率が高いようです。
Kerasでは、精度は「78%~85%」程度だったので、より高い精度となりました。
正解率確認
機械学習を用いたクラス分類の精度を評価するには、混同行列 (Confusion matrix) を作成して、正しく識別できた件数、誤って識別した件数を比較することが一般的です。
scikit-learn には、混同行列を作成するメソッドとして、sklearn.metrics.confusion_matrix があります。
二値分類(2クラス分類)においては実際のクラスと予測したクラスの組み合わせによって、結果を以下の4種類に分けることができます。
- 真陽性(TP: True Positive): 実際のクラスが陽性で予測も陽性(正解)
- 真陰性(TN: True Negative): 実際のクラスが陰性で予測も陰性(正解)
- 偽陽性(FP: False Positive): 実際のクラスは陰性で予測が陽性(不正解)
- 偽陰性(FN: False Negative): 実際のクラスは陽性で予測が陰性(不正解)
|
1 2 3 4 5 6 7 8 |
from sklearn.metrics import confusion_matrix for i in range(len(model)): cm = confusion_matrix(Y_test.ravel(), model[i].predict(X_test)) #extracting TN, FP, FN, TP TN, FP, FN, TP = confusion_matrix(Y_test, model[i].predict(X_test)).ravel() print(cm) print('Model[{}] Testing Accuracy = "{} !"'.format(i, (TP + TN) / (TP + TN + FN + FP))) print()# Print a new line |
結果が次のように出力されました。
|
1 2 3 |
[[50 6] [ 6 28]] Model[9] Testing Accuracy = "0.8666666666666667 !" |
これは次のような意味になります。
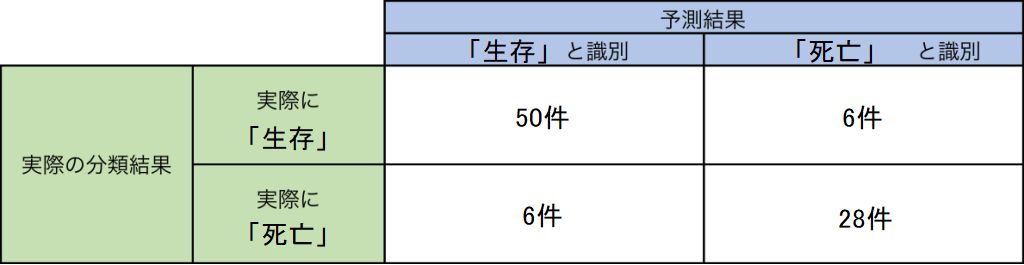
実際に出力されると次のような結果となります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
[[51 5] [10 24]] Model[0] Testing Accuracy = "0.8333333333333334 !" [[48 8] [11 23]] Model[1] Testing Accuracy = "0.7888888888888889 !" [[47 9] [ 9 25]] Model[2] Testing Accuracy = "0.8 !" [[44 12] [ 4 30]] Model[3] Testing Accuracy = "0.8222222222222222 !" [[48 8] [ 9 25]] Model[4] Testing Accuracy = "0.8111111111111111 !" [[50 6] [ 9 25]] Model[5] Testing Accuracy = "0.8333333333333334 !" [[49 7] [ 6 28]] Model[6] Testing Accuracy = "0.8555555555555555 !" [[47 9] [ 8 26]] Model[7] Testing Accuracy = "0.8111111111111111 !" [[51 5] [ 8 26]] Model[8] Testing Accuracy = "0.8555555555555555 !" [[50 6] [ 6 28]] Model[9] Testing Accuracy = "0.8666666666666667 !" [[49 7] [ 8 26]] Model[10] Testing Accuracy = "0.8333333333333334 !" [[ 3 53] [ 0 34]] Model[11] Testing Accuracy = "0.4111111111111111 !" [[49 7] [12 22]] Model[12] Testing Accuracy = "0.7888888888888889 !" [[37 19] [ 4 30]] Model[13] Testing Accuracy = "0.7444444444444445 !" [[49 7] [10 24]] Model[14] Testing Accuracy = "0.8111111111111111 !" [[47 9] [10 24]] Model[15] Testing Accuracy = "0.7888888888888889 !" |
正解率は、ランダムフォレスト、勾配ブースティング決定木、アダブーストなどが高いです。
まとめ
ディープラーニングを勉強するためにKerasしか利用したことがありませんでしたが、Scikit-learnの能力は凄まじいです。
ツールを使う感覚で技術やデータの中身がブラックボックスの状態でも機械学習が利用できました。
数十種類の学習モデルを呼び出しても計算時間は短く、ディープラーニングより精度が高いものもありました。
各学習モデルの具体的な中身は今後調べていきます。大学で学んだ気はしますが・・・。
データの前処理が非常に重要ですが、その部分は、まだよく分かってません。

