PytorchはLSTMが難しいらしいし、TensorFlowも難しいので未挑戦です。
Kerasは、TensorFlowのラッパークラスだけどAIライブラリの中で一番簡単です。
ということでディープラーニングを学ぶために、Kerasを使って少しずつ学習を進めています。
- はじめてのKerasを使った株価予測(ディープラーニング)
- KerasのFunctional API Modelの構造を理解する
- Kerasを使って活性関数・目的関数・最適化手法をまとめる
- Kerasのモデル保存・利用(ディープラーニング)
今回はディープラーニングではなくMatplotlibについて記載します。
Matplotlibの日本語化
Defaultでは日本語を利用すると豆腐(□)が表示されてしまいます。Windows上でも同じです。
日本語フォントをインストールして文字化け解消してみます。
- matplotlibの設定ファイルの場所を確認
- 日本語に対応したフォントのダウンロード
- matplotlibの設定ファイルをコピー&修正
- フォントのキャッシュの削除
matplotlibの設定ファイルの場所を確認
matplotlibrcは、Matplotlibのデフォルトのグラフのスタイル(線やグリッドの種類・太さ・色など)を設定するファイルです。
日本語を利用するには、このファイルを修正する必要があるので、まずはファイル場所を確認します。
|
1 2 |
import matplotlib print(matplotlib.matplotlib_fname()) |
【結果】
|
1 |
C:\Python36\lib\site-packages\matplotlib\mpl-data\matplotlibrc |
日本語に対応したフォントのダウンロード
日本語フォントにはIPAフォントやTakaoフォントなどが使えますが、IPAフォントを紹介しているサイトが多いので、こちらを使います。
【ダウンロード先】
ダウンロードして解凍すると、ipaexg.ttfというファイルがあります。
Windows上であればインストールしてしまうか、下記にコピーします。
|
1 |
C:\Python36\Lib\site-packages\matplotlib\mpl-data\fonts\ttf |
matplotlibの設定ファイルをコピー&修正
最初に発見したmatplotlibrc次のファイルを、ユーザー設定のディレクトリにコピーします。
|
1 |
C:\Python36\lib\site-packages\matplotlib\mpl-data\matplotlibrc |
【格納先】
- C:\Users\[user_name]\.matplotlib\
- ファイルの実行フォルダなど
「matplotlibの設定ファイルの場所を確認」して、ファイルパスが変わっていれば成功です。
次に、コピーした「matplotlibrc」に次の記述を追加します。
|
1 |
font.family : IPAexGothic |
フォントのキャッシュの削除
上記だけの修正だと、次のようなエラーが出ることがあります。
|
1 2 |
C:\Python36\lib\site-packages\matplotlib\font_manager.py:1328: UserWarning: findfont: Font family ['IPAexGothic'] not found. Falling back to DejaVu Sans (prop.get_family(), self.defaultFamily[fontext])) |
フォルトファイルが見つからないのが原因で、通常はフォントのキャッシュファイルが削除されていないためです。
実際に、警告の出ている箇所にprint文を入れると、IPAexGothicが存在していないことが分かります。
|
1 2 3 4 5 |
for font in fontlist: + print(font.name) if (directory is not None and os.path.commonprefix([os.path.normcase(font.fname), directory]) != directory): |
デフォルト設定ファイルの存在するフォルダ、そしてユーザ設定ファイルの存在するフォルダにある次のファイルを削除します。
- fontList.cache
- fontList.py3k.cache
- fontList.json
他の銘柄でバックテストをやってみる
「軸名がない」「目盛りの単位がない」グラフは、グラフとして意味がないと大学研究室で学びました。
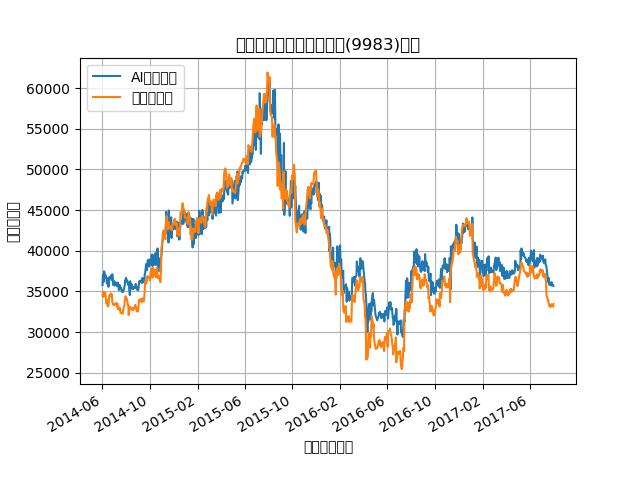
前回までのグラフのy軸は、単なる数字が並んでいるだけで個人的には意味があるとはいえません。
次のように書き換えてみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# plot準備 result = pd.DataFrame({'pred': pred, 'test': y_test_price.reshape(-1,), 'datetime': pd.to_datetime(datetime[test_size:]) }) result = result.set_index('datetime') result.plot(grid=True) plt.title('ファーストリテイリング(9983)株価') plt.ylabel('株価(円)') plt.xlabel('日付(年月)') plt.legend(['AIの予測値', '実際の株価'], loc='upper left') plt.savefig('./test.png') plt.show() |
これでグラフを表示してみると、なかなか良いグラフが描けるようになりました。
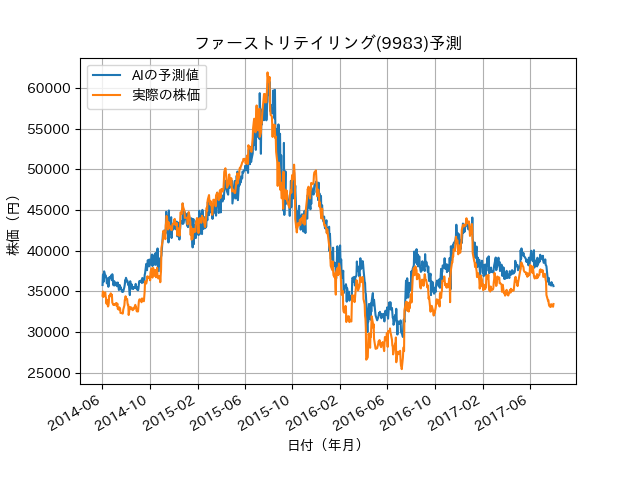
今回は、ファーストリテイリング(9983)に対して、前回学習させたデータを適用しています。
これで、他の銘柄であっても学習モデルを適用できることも分かりました。
今回使ったコード
学習済データを利用してグラフを作成しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
import pickle import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.preprocessing import StandardScaler from keras.models import load_model CSV_FILE = "9983.csv" THRESHOLD = 10 # データの読み込み def read_data(): df = pd.read_csv(CSV_FILE) closes = df['finish'].values datetime = df['datetime'].values return closes.reshape(-1,1), datetime # 全データのうち 20% を検証用データに割り当て def build_train_test_data(base_data): # 特徴量の尺度を揃える:特徴データを標準化して配列に入れる scaler = StandardScaler() # 特徴データを標準化(平均0、分散1になるように変換) data = scaler.fit_transform(base_data) x_data = [] y_data_price = [] for i in range(len(data) - THRESHOLD): x_data.append(data[i:i + THRESHOLD]) y_data_price.append(data[i + THRESHOLD]) x_data = np.asarray(x_data).reshape((-1, THRESHOLD, 1)) y_data_price = np.asarray(y_data_price) # 学習データ train_size = int(len(data) * 0.8) # テストデータ x_test = x_data[train_size:] y_test_price = y_data_price[train_size:] return y_test_price, x_test, scaler, train_size + THRESHOLD def main(): # Load the pipeline first: with open('scaler.pkl', 'rb') as f: pickle_model = pickle.load(f) # Then, load the Keras model: model = load_model("model.h5") data, datetime = read_data() y_test_price, x_test, scaler, test_size = build_train_test_data(data) pred = model.predict(x_test)[0][:, 0].reshape(-1) # 標準化を戻す pred = scaler.inverse_transform(pred) y_test_price = scaler.inverse_transform(y_test_price) # plot準備 result = pd.DataFrame({'pred': pred, 'test': y_test_price.reshape(-1,), 'datetime': pd.to_datetime(datetime[test_size:]) }) result = result.set_index('datetime') result.plot() plt.title('ファーストリテイリング(9983)株価') plt.ylabel('株価(円)') plt.xlabel('日時(年月)') plt.legend(['AIの予測値', '株価の実値'], loc='upper left') plt.savefig('./test.png') plt.show() if __name__ == '__main__': main() |