
Kerasを使った学習モデルの書き方に関しては、ある程度調べました。
次は、そもそものKerasを使った全体構造を調べていきます。
わかってないのは、このあたり。
- 学習データの再利用
- バックテストの方法
- 収束グラフの生成
- 出力パラメータの理解
サンプルコードは、未だにはじめてのKerasを使った株価予測のものです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
def main(): model = create_model() data = read_data() x_train, y_train_price, y_train_updown, x_test, y_test_price, y_test_updown, scaler = \ build_train_test_data(data) # エポックは 100、バッチサイズは 10 model.fit(x_train, [y_train_price, y_train_updown], validation_data=(x_test, [y_test_price, y_test_updown]), epochs=100, batch_size=10, callbacks=[CSVLogger('train.log.csv')]) # モデルのsave/load model.save('model.h5') with open('scaler.pkl', 'wb') as f: pickle.dump(scaler, f, protocol=pickle.HIGHEST_PROTOCOL) pred = model.predict(x_test)[0][:, 0].reshape(-1) # 標準化を戻す pred = scaler.inverse_transform(pred) y_test_price = scaler.inverse_transform(y_test_price) # plot準備 result = pd.DataFrame({'pred': pred, 'test': y_test_price.reshape(-1,)}) result.plot() plt.show() |
コードを見るとデータの保存もしている雰囲気なので、保存した学習データを利用できるはずです。
また、結果のバックテストで具体的にどれだけの収益が出るのか・・なども確認しなければ・・・。
モデルのsave/load
実運用をするためには毎回学習はできません。なぜなら結果が出るまで17分かかります。
このため、まずは学習済みのモデルを利用できるようにしてみます。
Keras でモデルを保存するには model.save か keras.models.save_model を使います。
|
1 |
model.save("model.h5") |
ファイル形式は HDF5 で保存されます。
利用の方法は次のようになります。
|
1 2 3 4 |
from keras.models import load_model # Load the Keras model: model = load_model("model.h5") |
次に学習済みモデルの利用方法です。
|
1 2 3 |
# Load the pipeline first: with open('scaler.pkl', 'rb') as f: pickle_model = pickle.load(f) |
scaler.pklに保存したscalerのためのファイルを使って、データをtransform、その後に使用しています。
実行結果
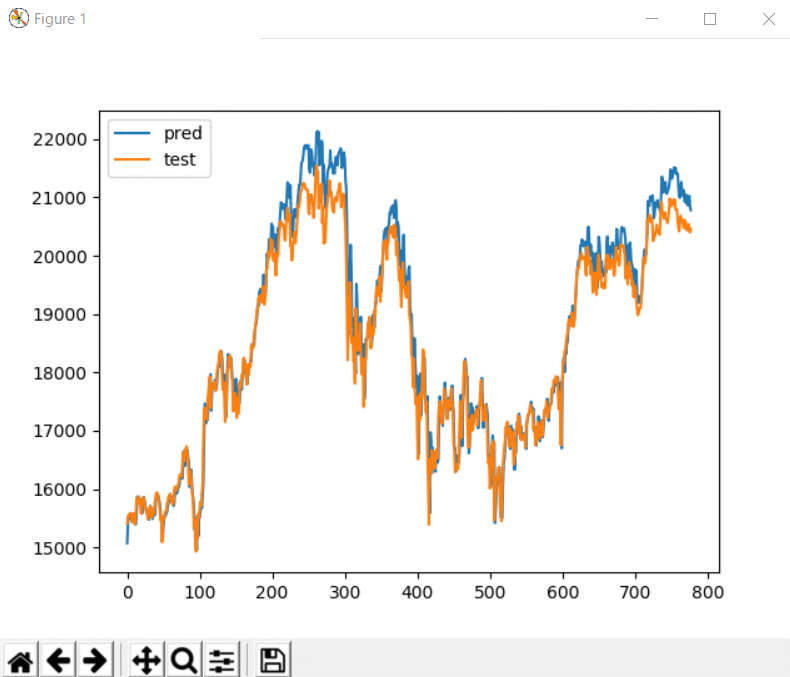
当然ですが、学習モデルを使っても同じグラフが生成されていることが確認できます。
[17分かけて学習させた結果]
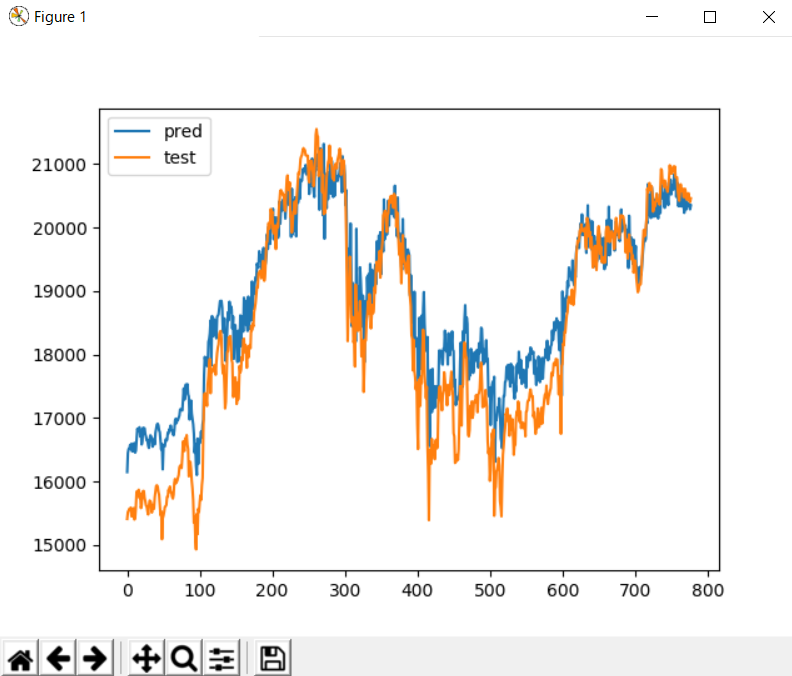
[学習モデルを使った結果]
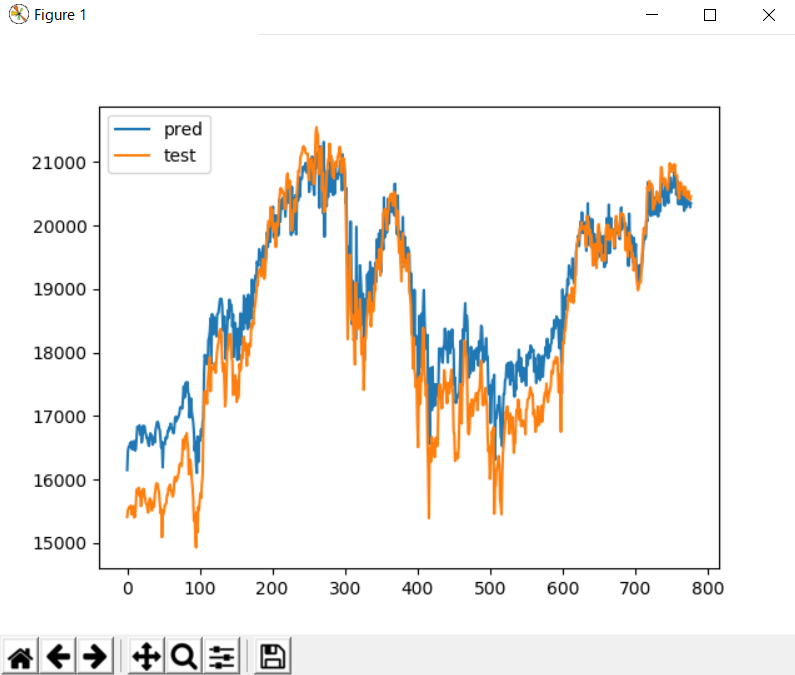
ただし、正解率や利益率が全く表示されてないです・・。
モデルを外部からロードして使用するコード
分からないなりに、いじってたら何となく結果が得られたのでコードを載せておきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
import pickle import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.preprocessing import StandardScaler from keras.models import load_model CSV_FILE = "1330.csv" # データの読み込み def read_data(): df = pd.read_csv(CSV_FILE) closes = df['finish'].values return closes.reshape(-1,1) # 全データのうち 20% を検証用データに割り当て def build_train_test_data(base_data): # 特徴量の尺度を揃える:特徴データを標準化して配列に入れる scaler = StandardScaler() # 特徴データを標準化(平均0、分散1になるように変換) data = scaler.fit_transform(base_data) x_data = [] y_data_price = [] for i in range(len(data) - 10): x_data.append(data[i:i + 10]) y_data_price.append(data[i + 10]) x_data = np.asarray(x_data).reshape((-1, 10, 1)) y_data_price = np.asarray(y_data_price) # 学習データ train_size = int(len(data) * 0.8) # テストデータ x_test = x_data[train_size:] y_test_price = y_data_price[train_size:] return y_test_price, x_test, scaler def main(): # Load the pipeline first: with open('scaler.pkl', 'rb') as f: pickle_model = pickle.load(f) # Then, load the Keras model: model = load_model("model.h5") data = read_data() y_test_price, x_test, scaler = build_train_test_data(data) pred = model.predict(x_test)[0][:, 0].reshape(-1) # 標準化を戻す pred = scaler.inverse_transform(pred) y_test_price = scaler.inverse_transform(y_test_price) # plot準備 result = pd.DataFrame({'pred': pred, 'test': y_test_price.reshape(-1,)}) result.plot() plt.show() if __name__ == '__main__': main() |
あってるのか間違っているのかは、もう少し詳しくなって考えます。
アドバイスは大歓迎です。

