
株式投資で利益を得るために必要な事
- 知識ではなく(正しい手順による)練習(本人の努力)あるのみ
- 選んだ銘柄が当たろうが外れようが、つねに勝てる状況を作り出す
そのためには、市場がもつ不確実性をかぎりなく排除する必要があります。
そして、株式投資は予測するものではなくルールに沿って選ぶものです。
機械学習で購入銘柄を選択するという魅惑の物語(4度目の正直)です。
- 【6回目】機械学習で株価予測(機械学習で株予測(3点チャージ法の有効性検証)
- 【5回目】機械学習で株価予測(Protraを使ったバックテスト解決編)
- 【4回目】機械学習で株価予測(Backtraderでバックテスト調査)
- 【3回目】機械学習で株価予測(Pythonのバックテストライブラリ調査)
- 【2回目】機械学習で株価予測(TA-LibとLightGBMを使った学習モデル構築)
- 【1回目】機械学習で株価予測(Two SigmaのKaggleコンペを確認)
一気に世の中のバックテストツールを超えます!!
オーバーフィッティングが発生する理由
「オーバーフィッティング(カーブフィッティング)」とはシステムを過去の相場にぴったり合うように過剰に最適化してしまうことです。
次のような理由で発生します。
- 1 バックテスト用過去データの対象期間が短すぎる場合
- 2 採用しているテクニカル指標が多過ぎる場合
- 3 採用しているテクニカル指標が複雑過ぎる場合
- 4 機械的に検出したパラメータセットをそのまま採用してしまう場合
機械学習なので「3」「4」は避けられません。
今回は「1」「2」を考えます。
重要でない説明変数を削除し、重要そうな騰落レシオを追加、加えて学習させる銘柄数を増やしてみます。
まずは株価の分割調整対策
銘柄の中には過去20年間で株価調整を行ったものもあります。
しかし残念ながら、Protraの出力するCSVファイルは株価調整がされていません。
株価調整を考慮しないと、株式分割が行われた日を境に株価が大きく変動したように見え、株価の過去データ分析ができません。
このため、SMAなどの値にも大きな影響を与えます。
ただし、Protraのソースコードを確認すると分割調整のデータを保有している事がわかりました。
分割調整したCSVを出力するには「Protra.Lib/Data/PriceData.cs」を次のように修正します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
/// /// 株価データをCSV形式に変換する。 /// /// 開始する銘柄コードを指定する。 /// 終了する銘柄コードを指定する。 /// public static bool ConvertToCSV(string start, string end) { var overwriteAll = false; foreach (var file in CollectFiles("")) { var code = Path.GetFileName(file); if (string.Compare(code, start, StringComparison.Ordinal) < 0 || string.Compare(code, end, StringComparison.Ordinal) > 0) continue; - var prices = GetPrices(code, TimeFrame.Daily, applySplit: false); + var prices = GetPrices(code, TimeFrame.Daily, applySplit: true); if (prices == null) continue; |
これでCSVは手に入りました。
騰落レシオを説明変数に追加する
騰落レシオは、移動平均線、MACD、RSI、RCI等のミクロ的なテクニカル指標とは異なり、マクロ的なテクニカル指標です。
具体的には、相場の買われすぎ感(過熱感)、売られすぎ感(割安感)を教えてくれます。
そのため、市場の体温計とか、相場の体温計と言われています。
RSIなどのテクニカル指標的には下がる理由が見つからなくても、市場全体が下がっているから下落した。
というパターン分析などに有効な指標だと考えています。
計算方法
騰落レシオ=(25)日間の値上がり銘柄数合計 ÷ (25)日間の下がり銘柄数合計 × 100
となります。
なお、実装するには東証一部のリストを手に入れる必要があります。
DataFrameをインデックスで横方向に結合する
複数の銘柄の結合が必要です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
left = pd.DataFrame({'close' : ['300', '100', '400'], 'volume' : [10, 13, 16] }, index=['1998/01/05','1998/01/10','1998/02/04']) right_1 = pd.DataFrame({'close' : ['100', '200', '300'], 'volume' : [ 0, 3, 6] }, index=['1998/01/05','1998/01/20','1998/02/04']) right_2 = pd.DataFrame({'close' : ['700', '200', '500'], 'volume' : [ 0, 3, 6] }, index=['1998/01/05','1998/01/06','1998/02/03']) right_3 = pd.DataFrame({'close' : ['400', '100', '600'], 'volume' : [ 0, 3, 6] }, index=['1998/01/04','1998/01/20','1998/02/06']) result = pd.concat([left, right_1, right_2, right_3], axis=1, ignore_index=True, sort=True) result |
列名が重複すると concat、merge、join で動作がそれぞれ異なります。今回の用途では concatが適切です。
ignore_index=True を指定すると、列名が 0、1・・・と振りなおされます。
マルチプロセスでpandas.concatで結合する
東証一部2161銘柄のCSVファイルを読み込み計算させる必要があります。
ファイルの読み込みには並列処理を使います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import time import glob import numpy as np import pandas as pd import os from multiprocessing import Pool #map_multiprocessing(pd.concat) def readcsv_map_multi(fileslist): p = Pool(os.cpu_count()) df = pd.concat(p.map(pdreadcsv, fileslist)) p.close() return df #csv1個読み込み(map関数用) def pdreadcsv(csv_path): return pd.read_csv(csv_path) if __name__ == "__main__": allfiles = sorted(glob.glob('*/*.csv', recursive=True)) start = time.time() df = readcsv_map_multi(allfiles) process_time = time.time() - start print('csv読み込み時間:{:.3f}s'.format(process_time)) |
結果は次のようになりました。
|
1 |
MemoryError: Unable to allocate array with shape (1, 17170082) and data type float64 |
困った・・、メモリが足りません。
PandasやNumPyの並列処理だったり、メモリに乗り切らないデータを扱う際などにはDaskライブラリが便利です。
ただスピードが落ちるし、毎回計算するのは嫌なので困りました・・・・。
Protraで予め騰落レシオを出力させる
最後の手段はProtraで「騰落レシオ」を計算させてCSV保存し、利用します。
この方法は使いたくなかった・・・
|
1 2 3 4 5 6 7 8 |
# 騰落レシオ結合 def add_updown_ratio(df_train): df = pd.read_csv("updown.csv", names=["date", "updown"]) tmp = df["date"].str.split('/', expand=True) df["date"] = tmp[0].str.zfill(4) + "/" + tmp[1].str.zfill(2) + "/" + tmp[2].str.zfill(2) df_train = pd.merge(df_train, df, on="date", how="outer") del tmp, df return df_train["updown"] |
出力した騰落レシオCSVと株価は日付のインデックスで結合します。
日付フォーマットが異なるのでゼロパディングしています。
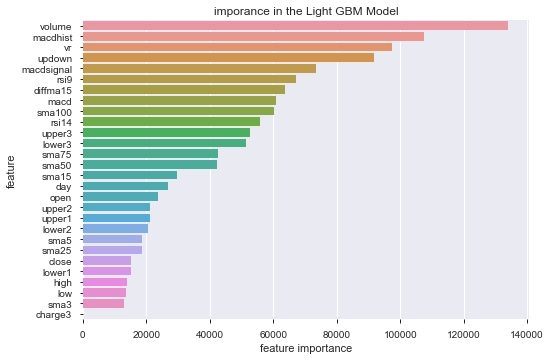
実際にLightGBMに解かせてfeature_importances_を確認すると、機械学習が「騰落レシオ」の指標を重要視していることが伺えます。
複数銘柄で学習データ作って分析する
学習データのほとんどが日経平均や、1つの企業の株価データのみです。
そこで、ある1社(もしくは日経平均)だけでなく、9社の株価を学習させてみます。
銘柄は時価総額の高い順に1000~9000台から一つずつ選びました。
業種に対する偏りを排除するためです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
stock_names = [ "1925", # 大和ハウス工業 "2914", # JT "3407", # 旭化成 "4502", # 武田薬品工業 "5108", # ブリヂストン "6758", # ソニー "7203", # トヨタ "8306", # 三菱UFJフィナンシャル・グループ "9432", # 日本電信電話 ] for stock_id in stock_names: df_train = pd.read_csv("tosho/" + stock_id + ".csv", names=("date", "open", "high", "low", "close", "volume")) |
なお予測データから「3%上がる」と判断したものだけ抽出し、バックテストにかけています。
結合して一つの分類器を作る場合
結果は次のようになりました。
|
1 2 3 4 5 6 7 8 9 10 11 |
X_train:(38551, 20) y_train:(38551,) X_valid:(9638, 20) y_valid:(9638,) LGBMClassifier Accuracy: 0.024409224144639568 Time = 422.0995936393738 Total Time = 422.0995936393738 LGBMClassifier was selected [[2153 2379] [2368 2738]] Model[LGBMClassifier] Testing Accuracy = "0.5074704295496991 !" |
訓練データの精度(Accuracy)は2%で、未学習・・つまり全く学習できていません。
バックテスト結果は次のようになりました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
株価データ: 日足 銘柄リスト: 9銘柄 1998/01/05~2020/01/24における成績です。 ---------------------------------------- 全トレード数 1594 勝ちトレード数(勝率) 797(50.00%) 負けトレード数(負率) 797(50.00%) 全トレード平均利率 0.02% 勝ちトレード平均利率 2.30% 負けトレード平均損率 -2.26% 勝ちトレード最大利率 16.96% 負けトレード最大損率 -16.58% 全トレード平均期間 4.46 勝ちトレード平均期間 4.51 負けトレード平均期間 4.41 ---------------------------------------- 必要資金 ¥3,535,500 最大ポジション(簿価) ¥3,738,300 最大ポジション(時価) ¥3,837,600 純利益 ¥472,900 勝ちトレード総利益 ¥14,658,400 負けトレード総損失 -¥14,185,500 全トレード平均利益 ¥297 勝ちトレード平均利益 ¥18,392 負けトレード平均損失 -¥17,799 勝ちトレード最大利益 ¥163,400 負けトレード最大損失 -¥128,000 プロフィットファクター 1.03 最大ドローダウン(簿価) -¥976,000 最大ドローダウン(時価) -¥1,027,300 ---------------------------------------- 現在進行中のトレード数 2 ---------------------------------------- 平均年利 0.64% 平均年利(直近5年) 0.62% 最大連勝 10回 最大連敗 13回 ---------------------------------------- [年度別レポート] 年度 取引回数 運用損益 年利 勝率 PF 最大DD 2020年 5回 ¥36,200円 1.02% 80.00% 4.29倍 -1.37% 2019年 136回 ¥286,600円 8.11% 58.09% 1.38倍 -11.60% 2018年 116回 -¥330,100円 -9.34% 46.55% 0.71倍 -9.33% 2017年 102回 ¥135,500円 3.83% 55.88% 1.23倍 -6.66% 2016年 129回 -¥18,500円 -0.52% 51.16% 0.99倍 -10.35% 2015年 107回 -¥426,300円 -12.06% 44.86% 0.60倍 -10.56% 2014年 67回 ¥203,000円 5.74% 56.72% 1.60倍 -4.96% 2013年 103回 ¥463,200円 13.10% 57.28% 1.66倍 -9.42% 2012年 21回 ¥58,900円 1.67% 52.38% 1.46倍 -3.12% 2011年 34回 ¥124,400円 3.52% 70.59% 1.39倍 -7.92% 2010年 35回 -¥81,600円 -2.31% 57.14% 0.76倍 -8.65% 2009年 41回 -¥214,400円 -6.06% 43.90% 0.75倍 -14.84% 2008年 75回 -¥51,400円 -1.45% 48.00% 0.94倍 -8.73% 2007年 134回 -¥188,000円 -5.32% 46.27% 0.81倍 -6.80% 2006年 110回 ¥264,000円 7.47% 60.91% 1.48倍 -8.01% 2005年 111回 ¥171,800円 4.86% 53.15% 1.22倍 -5.96% 2004年 73回 ¥59,900円 1.69% 53.42% 1.09倍 -6.49% 2003年 71回 ¥135,200円 3.82% 46.48% 1.14倍 -16.58% 2002年 30回 ¥154,800円 4.38% 53.33% 1.46倍 -9.05% 2001年 65回 -¥376,300円 -10.64% 41.54% 0.63倍 -12.00% 2000年 29回 ¥66,000円 1.87% 48.28% 1.19倍 -6.88% |
利益曲線は次のとおりです。
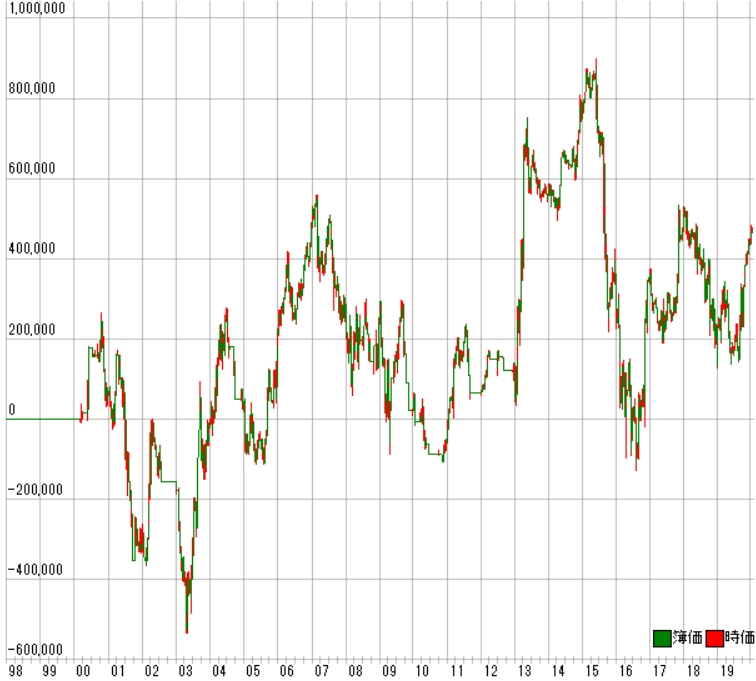
全然駄目じゃん。
勝率は気にしないとして、プロフィットファクターが低すぎる。
銘柄毎に分類器を作る場合
結果は次のようになりました。
|
1 2 3 4 5 6 7 8 9 10 11 |
X_train:(4327, 28) y_train:(4327,) X_valid:(1082, 28) y_valid:(1082,) LGBMClassifier Accuracy: 0.021492951236422465 Time = 95.99822759628296 Total Time = 95.99822759628296 LGBMClassifier was selected [[504 27] [523 28]] Model[LGBMClassifier] Testing Accuracy = "0.49168207024029575 !" |
こちらも訓練データの精度(Accuracy)は2%で、未学習・・つまり全く学習できていません。
バックテスト結果は次のようになりました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
株価データ: 日足 銘柄リスト: 9銘柄 1998/01/05~2020/01/24における成績です。 ---------------------------------------- 全トレード数 2306 勝ちトレード数(勝率) 1185(51.39%) 負けトレード数(負率) 1121(48.61%) 全トレード平均利率 0.31% 勝ちトレード平均利率 3.02% 負けトレード平均損率 -2.56% 勝ちトレード最大利率 21.19% 負けトレード最大損率 -100.00% 全トレード平均期間 4.45 勝ちトレード平均期間 4.46 負けトレード平均期間 4.44 ---------------------------------------- 必要資金 ¥5,162,700 最大ポジション(簿価) ¥5,770,200 最大ポジション(時価) ¥6,086,800 純利益 ¥6,391,500 勝ちトレード総利益 ¥31,968,900 負けトレード総損失 -¥25,577,400 全トレード平均利益 ¥2,772 勝ちトレード平均利益 ¥26,978 負けトレード平均損失 -¥22,817 勝ちトレード最大利益 ¥210,000 負けトレード最大損失 -¥909,000 プロフィットファクター 1.25 最大ドローダウン(簿価) -¥1,044,900 最大ドローダウン(時価) -¥736,000 ---------------------------------------- 現在進行中のトレード数 1 ---------------------------------------- 平均年利 5.90% 平均年利(直近5年) 1.88% 最大連勝 12回 最大連敗 9回 ---------------------------------------- [年度別レポート] 年度 取引回数 運用損益 年利 勝率 PF 最大DD 2020年 8回 -¥32,500円 -0.63% 37.50% 0.40倍 -2.52% 2019年 99回 ¥366,100円 7.09% 61.62% 1.63倍 -5.69% 2018年 132回 -¥326,800円 -6.33% 43.94% 0.72倍 -7.14% 2017年 120回 ¥193,700円 3.75% 56.67% 1.25倍 -8.01% 2016年 153回 ¥284,200円 5.50% 56.86% 1.15倍 -10.35% 2015年 147回 ¥393,200円 7.62% 53.06% 1.25倍 -15.05% 2014年 116回 ¥199,900円 3.87% 50.86% 1.22倍 -10.91% 2013年 137回 ¥1,315,200円 25.48% 54.74% 2.33倍 -9.71% 2012年 102回 ¥720,300円 13.95% 57.84% 1.87倍 -6.84% 2011年 85回 ¥29,200円 0.57% 48.24% 1.03倍 -7.35% 2010年 97回 ¥158,300円 3.07% 54.64% 1.23倍 -6.52% 2009年 102回 ¥364,600円 7.06% 53.92% 1.19倍 -8.81% 2008年 136回 ¥423,000円 8.19% 50.74% 1.16倍 -25.21% 2007年 132回 -¥679,100円 -13.15% 48.48% 0.70倍 -100.00% 2006年 125回 ¥449,500円 8.71% 60.00% 1.41倍 -8.98% 2005年 85回 ¥196,200円 3.80% 52.94% 1.30倍 -7.82% 2004年 89回 ¥743,300円 14.40% 56.18% 2.14倍 -4.27% 2003年 94回 ¥738,900円 14.31% 58.51% 1.75倍 -10.18% 2002年 121回 ¥134,000円 2.60% 51.24% 1.09倍 -9.28% 2001年 122回 ¥427,000円 8.27% 48.36% 1.24倍 -25.82% 2000年 104回 ¥293,300円 5.68% 50.96% 1.17倍 -11.10% |
利益曲線は次のとおりです。
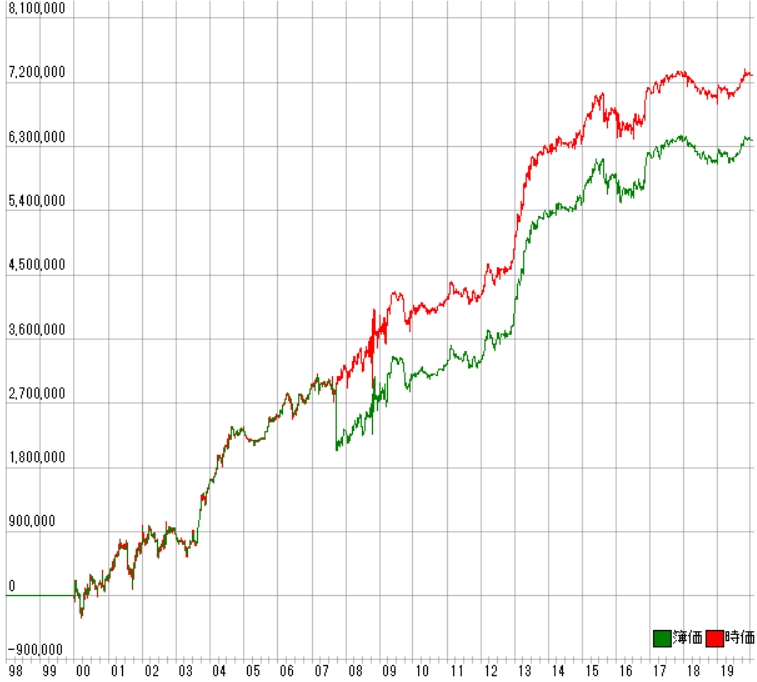
グラフを見ると、まだこっちの方が良さそうです。
ですが、勝率51%、プロフィットファクター1.25で魅力を感じません。
まとめ
複数銘柄を一つの学習モデルで解くことが無理があったのかな・・・
でも、一般的なシステムトレードの手法なんだけどなぁ。
データ分析って仮説を検証する作業だと思ってますが、株価予測に関しては全く思ったようにいきません。
本職の人も多く、それでも上手く行って無いので、一生無理かも・・時間の無駄かな。
とりあえず、分析が足りないので今後も両方の手法でバックテストを確認してみます。
ここからがスタートなんだろうなぁ・・。
前回、勝率8割、プロフィットファクター7の過学習結果を見ただけに、ショボく見えます。
ソースコード
あまり曲線がキレイでなく、前回のコードに前述のソースコードを加えるだけなので省略します。

