
社内文化祭の為に、あるものを作りました。
その中の一つの技術要素として、OpenCVで背景差分を使いました。
少し前の状態の背景画像と、新たに何かが入ってきた状態の2つの画像の差を取ることで物体検出する手法を背景差分法といいます。
事前に、下記のインストールが必要です。
|
1 2 |
pip uninstall opencv-python pip install opencv-contrib-python |
サンプルコード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import cv2 import subprocess cap = cv2.VideoCapture(0) bgs = cv2.bgsegm.createBackgroundSubtractorLSBP() while(cap.isOpened()): ret, frame = cap.read() mask = bgs.apply(frame) bg = bgs.getBackgroundImage() cv2.imshow('mask', mask) cv2.imshow('bg', bg) if cv2.waitKey(1) != -1: break cap.release() cv2.destroyAllWindows() |
で、各背景差分の手法で「手を撮影して5秒動かなかった場合の背景差分」の結果を載せておきます。
cv2.bgsegm.createBackgroundSubtractorCNT()
低スペックな計算機でもほかのアルゴリズムより高速に処理ができる。CNTという名前は「CouNT」の省略。

cv2.bgsegm.createBackgroundSubtractorGSOC()
LSBP特徴を使ってる。ノイズ除去とか穴埋めといった後処理をしている。

cv2.bgsegm.createBackgroundSubtractorLSBP()
Local SVG Binary Pattern。局所的なノイズや隣接画素が類似しているような場合にもロバストにするようにSVD(特異値分解)を使った特徴量で背景差分を行っている。
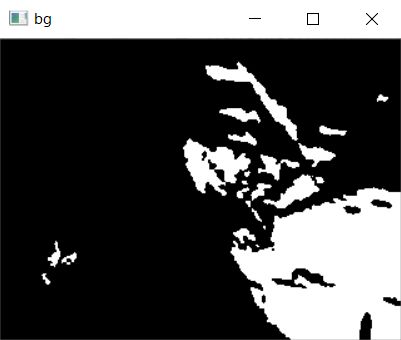
cv2.createBackgroundSubtractorKNN()
K近傍方に基づく背景差分。前景の画素数が少ない場合は効率が良い。

cv2.bgsegm.createBackgroundSubtractorMOG()
混合正規分布(Gaussian Mixture)を基にした前景・背景の領域分割アルゴリズム。可能性の高い背景色は長く留まり、より静的になる。
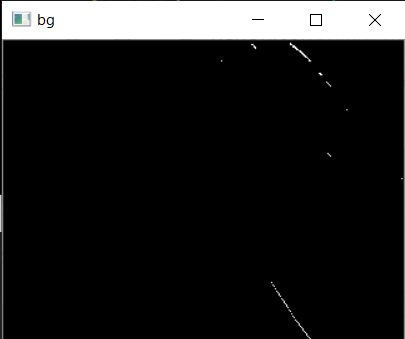
cv2.createBackgroundSubtractorMOG2()
混合正規分布を基にした前景・背景の領域分割アルゴリズム。照明の変化などの動的なシーンに対する適応力が優れている。
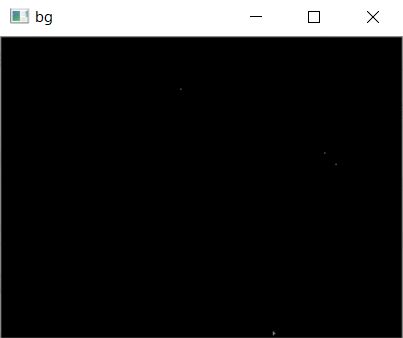
cv2.bgsegm.createBackgroundSubtractorGMG()
統計的な背景の推定法と画素単位でのベイス推定に基づく領域分割を組み合わせたアルゴリズム。
こんなの、背景差分じゃないから!!
フレーム間差分じゃん・・・・・。
システムトレードの実装ばかりしていて、文化祭向けの基礎技術調査が少なすぎました。
カメラでなくセンサ使うとか、色々と他の方法あったよね・・・。
この状態で次に何をするか?というと、
- cv2.findContours(cv2.RETR_EXTERNAL)メソッドで、外郭を抽出する
- cv2.contourArea()メソッドで、輪郭エリアを得る
- cv2.boundingRect()メソッドで、外接矩形(x座標とy座標、幅、高さ)を得る
サンプルソースコードを載せます。
処理を軽くするために、何フレームかをスキップしています。
また、背景差分の元データも一定期間後に更新させています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 |
import cv2 import sys import numpy as np import subprocess # 背景差分版 def capture(cap): ret,frame = cap.read() return cv2.resize(frame, (320, 240)) def mark(mask, frame): ref = 0 # 動いているエリアの面積を計算してちょうどいい検出結果を抽出する thresh = cv2.threshold(mask, 3, 255, cv2.THRESH_BINARY)[1] contours, hierarchy = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) max_area = 0 areaf = 0 if (contours): target = contours[0] for cnt in contours: #輪郭の面積を求めてくれるcontourArea area = cv2.contourArea(cnt) if max_area < area and area < 10000 and area > 800: max_area = area; target = cnt # 動いているエリアのうちそこそこの大きさのものがあればそれを矩形で表示する if (max_area <= 800): areaf = frame else: # 諸般の事情で矩形検出とした。 x,y,w,h = cv2.boundingRect(target) areaf = cv2.rectangle(frame,(x,y),(x+w,y+h),(0,255,0),2) ref = 1 return ref, areaf def main(): i = 0 # カウント変数 # カメラのキャプチャ cap = cv2.VideoCapture(1) if cap.isOpened() is False: print("can not open camera") sys.exit() cap.set(cv2.CAP_PROP_FPS, 10) # 最初のフレームを背景画像に設定 bg = capture(cap) fgbg = cv2.bgsegm.createBackgroundSubtractorCNT() # グレースケール変換 bg = cv2.cvtColor(bg, cv2.COLOR_BGR2GRAY) ref = 0 skip_count = 0 while(cap.isOpened()): # フレームの取得 frame = capture(cap) # グレースケール変換 gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) mask = fgbg.apply(gray) cv2.imshow("mask", mask) if( skip_count == 0 ): ref, areaframe = mark(mask, frame) # フレームとマスク画像を表示 cv2.imshow("areaframe", areaframe) skip_count = (skip_count + 1) % 30 i += 1 # カウントを1増やす if (ref): i = 0 ref = 0 # 背景画像の更新(一定間隔) if(i > 1000): bg = capture(cap) bg = cv2.cvtColor(bg, cv2.COLOR_BGR2GRAY) i = 0 # カウント変数の初期化 # qキーが押されたら途中終了 if cv2.waitKey(1) & 0xFF == ord('q'): break cap.release() cv2.destroyAllWindows() if __name__ == '__main__': main() |
おまけ
上のソースコードは、どこかのサイトのフレーム間差分のソースコードを修正しました。
フレーム間差分の方が矩形の追従率は高いです。
ただし、物体が動かなくなる場合には使えません。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
import cv2 import subprocess cap = cv2.VideoCapture(0) before = None while True: # OpenCVでWebカメラの画像を取り込む ret, frame = cap.read() # スクリーンショットを撮りたい関係で1/4サイズに縮小 frame = cv2.resize(frame, (int(frame.shape[1]/4), int(frame.shape[0]/4))) # 加工なし画像を表示する cv2.imshow('Raw Frame', frame) # 取り込んだフレームに対して差分をとって動いているところが明るい画像を作る gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) if before is None: before = gray.copy().astype('float') continue # 現フレームと前フレームの加重平均を使うと良いらしい cv2.accumulateWeighted(gray, before, 0.5) mdframe = cv2.absdiff(gray, cv2.convertScaleAbs(before)) # 動いているところが明るい画像を表示する cv2.imshow('MotionDetected Frame', mdframe) # 動いているエリアの面積を計算してちょうどいい検出結果を抽出する thresh = cv2.threshold(mdframe, 3, 255, cv2.THRESH_BINARY)[1] # 輪郭データに変換しくれるfindContours contours, hierarchy = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) max_area = 0 if (contours): target = contours[0] for cnt in contours: #輪郭の面積を求めてくれるcontourArea area = cv2.contourArea(cnt) if max_area < area and area < 10000 and area > 1000: max_area = area; target = cnt # 動いているエリアのうちそこそこの大きさのものがあればそれを矩形で表示する if max_area <= 1000: areaframe = frame cv2.putText(areaframe, 'not detected', (0,50), cv2.FONT_HERSHEY_PLAIN, 3, (0, 255,0), 3, cv2.LINE_AA) else: # 諸般の事情で矩形検出とした。 x,y,w,h = cv2.boundingRect(target) areaframe = cv2.rectangle(frame,(x,y),(x+w,y+h),(0,255,0),2) cv2.imshow('MotionDetected Area Frame', areaframe) # キー入力を1ms待って、k が27(ESC)だったらBreakする k = cv2.waitKey(1) if k == 27: break # キャプチャをリリースして、ウィンドウをすべて閉じる cap.release() cv2.destroyAllWindows() |

