Kerasには2通りのModelの書き方があります。

Sequencial Model と Functional API Model です。
【Sequential Model】
|
1 2 3 |
model = Sequential() model.add(Dense(32, input_dim=784)) model.add(Activation('relu')) |
Sequential モデルは単純に、今の層のそれぞれのノードに、前の層の全ノードから矢印を引っ張ってくるイメージです。
|
1 2 3 4 5 |
inputs = Input(shape=(784,)) x = Dense(64, activation='relu')(inputs) x = Dense(64, activation='relu')(x) predictions = Dense(10, activation='softmax')(x) model = Model(input=inputs, output=predictions) |
こちらの方法では、2 つのニューラルネットワークの出力を入れてみたり、レイヤーを共有してみたりと、複雑なことができるようになります。
前回、よく分からなかったコードは、Functional API Modelで書かれていました。
なるほど・・そもそも論が分かってなかったです。
Sequential Modelでは自由度が低いそうなので、Functional API Modelに最初から慣れた方がよいそうです。
また、慣れてくるとFunctional API Modelの方が直感的に思えてくるそうです。
まだ何も理解してないので、それならFunctional API Modelから始めることにします。
ディープラーニングを学習するには、この本がオススメです。
Functional API Model
書き方は次のようになります。
- Input関数で入力として受け付けるデータの次元を指定
- 加えたいレイヤー関数の入力それ以前のレイヤー情報を指定して、変数に入れていく
- Model関数で入力と出力を指定
理解したいコードは次の部分です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# LSTM を Keras を使って組む def create_model(): inputs = Input(shape=(10, 1)) # 日経平均株価の値を直接予測するため活性化関数は linear # 中間層の数は 300(理由なし) x = LSTM(300, activation='relu')(inputs) price = Dense(1, activation='linear', name='price')(x) updown = Dense(1, activation='sigmoid', name='updown')(x) model = Model(inputs=inputs, outputs=[price, updown]) # 後で検証に使用するため 2 値予測も含んでいる model.compile(loss={ 'price': 'mape', 'updown': 'binary_crossentropy', }, optimizer='adam', metrics={'updown': 'accuracy'}) return model |
うむ・・、分からないので、モデルを図示化してみましょう・・・。
Kerasのgraphvizモジュールで学習モデルを可視化
kerasのモジュールを使って、モデルの可視化ができるそうです。
ネットワークの構造を目で確認できるというのはかなり大きいと思います。
graphvizとpydotをインストールします(例:Windowsの場合)。
|
1 2 |
$ /c/anaconda3/Scripts/conda install graphviz $ /c/Python36/Scripts/pip install pydot |
使い方は、plot_modelモデルを関数に入れるだけです。
|
1 2 |
model = create_model() plot_model(model, to_file='model.png') |
【出力結果】
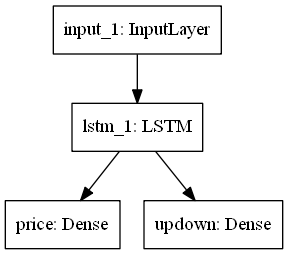
入力層
まず、Input関数で入力として受け付けるデータの次元を指定します。
|
1 |
inputs = Input(shape=(10, 1)) |
shape は入力の次元を表しています。
(10, 1) という表記は、10 という要素だけもつ Tuple(配列みたいなもの)という意味です。
隠れ層(中間層:intermediate layer)
リカレントニューラルネットワークの一種であるLSTM (Long short-term memory) を中間層に利用しています。
|
1 |
x = LSTM(300, activation='relu')(inputs) |
ノード数が300で、入力が inputs であるような層です。
Activation(活性化関数)は「relu」を利用しています。
出力層
|
1 2 |
price = Dense(1, activation='linear', name='price')(x) updown = Dense(1, activation='sigmoid', name='updown')(x) |
ノード数が1で、入力が x であるような層です。
予測株価を活性化関数「linear」、株価の増減を活性化関数「sigmoid」を利用しています。
dense は「密な」という意味で、前の層のすべてのノードから、この層のすべてのノードに対して矢印が引っ張られるから、こういう名前・・らしいです。
モデルを定義して入力と出力を接続
|
1 |
model = Model(inputs=inputs, outputs=[price, updown]) |
1つの入力と2つの出力を持ったモデルを定義します.
これは、図示化したモデルと同じです。
モデルをコンパイル
|
1 2 3 4 |
model.compile(loss={ 'price': 'mape', 'updown': 'binary_crossentropy', }, optimizer='adam', metrics={'updown': 'accuracy'}) |
compileメソッドは3つの引数を取ります
最適化アルゴリズム(optimizer)は「adam」を利用しています。
損失関数(loss)は予測株価に「mape」、株価の増減に「binary_crossentropy」を利用しています。
評価関数のリスト(metrics)は分類問題の精度としてmetrics=[‘accuracy’]を指定しています。
ようするに?
なんとなく、よく見る学習モデルを構築している事はわかりました。
ただし利用するアルゴリズムが色々ありすぎて、なぜそれを使うのか?が分かりません。
また、シグモイド関数(sigmoid)とか、人工知能の本を読むとキーワードは出てくるので、聞いた&習ったことはあるけれど分かってないです。
とりあえず、詳細は次回にしよう・・・。