
2010年12月12日(日) Yahoo!ニュースのコメント欄の一覧化
Pythonを内部で使って新しいWebサービスを作りました。
Yahoo!ニュースにコメントしたユーザの「私もそう思う」や「私はそう思わない」ボタンの点数をランキングにしています。
来週には広く公開しないとね。。
完全に自動化されて日々データベースが膨大になっています。
Yahoo!に作られたら一瞬で終了だね。。
2010年12月1日(水) スレッドで高速化 by Python
PythonでHTMLパースを行うと、3000件のURLの読み込みに50分程度かかりました・・・
最終的には、3万件ぐらいのHTMLパースをcronで行う予定なので、ありえない処理時間になりそうです・・・
まずは、他のライブラリを使って高速化を検討
- urllib
- urllib2
- httplib
- 一からsock通信を実装
測定してみたが、情報をまとめるほどの時間差は発生せず・・・
同期に質問した結果「スレッド」を利用する結論になりました。まぁそうだろうね。
下記がWebで見つけたサンプルです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import threading, urllib2 import Queue urls_to_load = [ 'http://stackoverflow.com/', 'http://slashdot.org/', 'http://www.archive.org/', 'http://www.yahoo.co.jp/', ] def read_url(url, queue): data = urllib2.urlopen(url).read() print('Fetched %s from %s' % (len(data), url)) queue.put(data) def fetch_parallel(): result = Queue.Queue() threads = [threading.Thread(target=read_url, args = (url,result)) for url in urls_to_load] for t in threads: t.start() for t in threads: t.join() return result def fetch_sequencial(): result = Queue.Queue() for url in urls_to_load: read_url(url,result) return result |
サンプルの紹介サイトでは、スレッド利用なしが「2秒」、スレッド利用で「0.9秒」と書かれています。
自サーバでは、スレッド数の最適数はいくつか・・・と思って計測してみた。
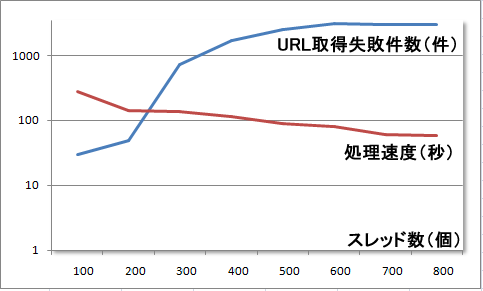
約「4000」件のHTMLサイトを取得した、処理時間とURL取得失敗数の関係図(Python 2.6を利用)
なぜか、スレッド数を増やすとURLのopen/readの失敗率が上がります。
HTTP ERRORの「404 Not Found」なんだよね、、サーバ側が弾いているのかな・・・?
2010年11月27日(土) PHPの関数って豊富なのね・・・今更
PHPでCSVファイルを読み込み、ある列でソートしようとしたい。
ファイルを読み込み「,」で分離して・・・・さてどうしようか。。
と思ったら、「fgetcsv」関数と「usort」関数や「array_multisort」関数がありました。
これらの関数を全く知らなかった。PHP4の時代からあるし・・・(泣)

