
Microsoft SharePointとは、マイクロソフト社が提供する、コラボレーションやドキュメント管理等を行うためのソフトウェアツール。
現在はWebDAVなどを使ってアクセスが可能のため、自動処理も何とか可能だ。
ただし、Microsoft 365 サービスによる Internet Explorer 11 のサポート終了に伴い、「エクスプローラーで開く」機能の廃止や、WebDAV 機能が正常に動作しなくなる可能性があると言われている。
SharePoint REST API への接続に使用できる SPHttpClient を提供しているそうだが、社内セキュリティが厳しい場合には使うことができない。
WebDAVですらファイル・フォルダ数が1000件とか増えてくると処理が重くて不安定になってしまう。
自動化泣かせのツール
……だと思ってる。
そんなSharepointをSeleniumで処理できるかどうか試してみる。
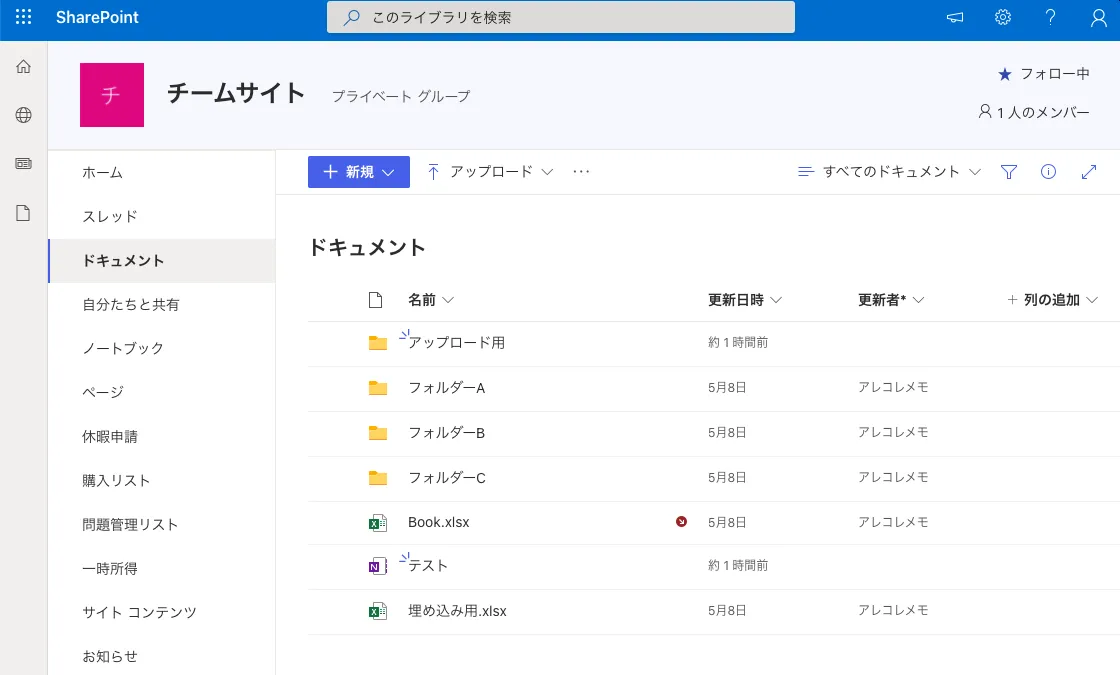
ドキュメント内のフォルダをクリックする
ドキュメント内のフォルダはButtonというタグとして存在していた。
<button data-automationid=”FieldRenderer-name” data-selection-invoke=”true” title=”フォルダ名” role=”link” type=”button” class=”ms-Link root_XXXXX nameField_XXXXX clickable_XXXXX overflow_XXXXX pre_XXXXX” tabindex=”-1″>フォルダ名</button>
しかし、buttonタグは他のUXの多くに使われているため、
<div role=”presentation” class=”ms-DetailsList-contentWrapper”>
のタグ中にあるbuttonだけ抽出する。
|
1 2 3 4 5 6 7 8 9 10 |
# タイトルが表示されるまで待機 buttons = WebDriverWait(driver, 10).until( EC.presence_of_all_elements_located((By.CSS_SELECTOR, '.ms-DetailsList-contentWrapper button[data-automationid="FieldRenderer-name"]')) ) # ページ内の全てのbutton要素をクリック for button in buttons: title = button.get_attribute("title") print(f"{title}") # サブフォルダに移動 sub_buttons[i].click() |
スクロール可能な要素内でスクロールダウン
これがAjaxサイトの自動化で嫌いなところ。
Sharepoint上のフォルダ一覧を抽出すると、たとえフォルダ・ファイル数が多くても60件しか取得できなかった。
ブラウザ上でスクロールダウンされるとajaxで追加のフォルダ・ファイルが読み込まれて表示しているようだ。
通常のスクロールダウンはこれで良い。
|
1 2 3 4 5 |
# スクロール可能な要素を取得 scrollable_element = driver.find_element_by_class_name("od-scrollable-content") # スクロールダウン scrollable_element.send_keys(Keys.ARROW_DOWN) |
でも今回は次のタグの中(スクロール可能な要素内)でスクロールダウンする必要がある。
<div class=”od-scrollable-content od-scrollablePane-content-ItemsScopeList od-ItemsScopeList-content-sticky” data-is-scrollable=”true”>
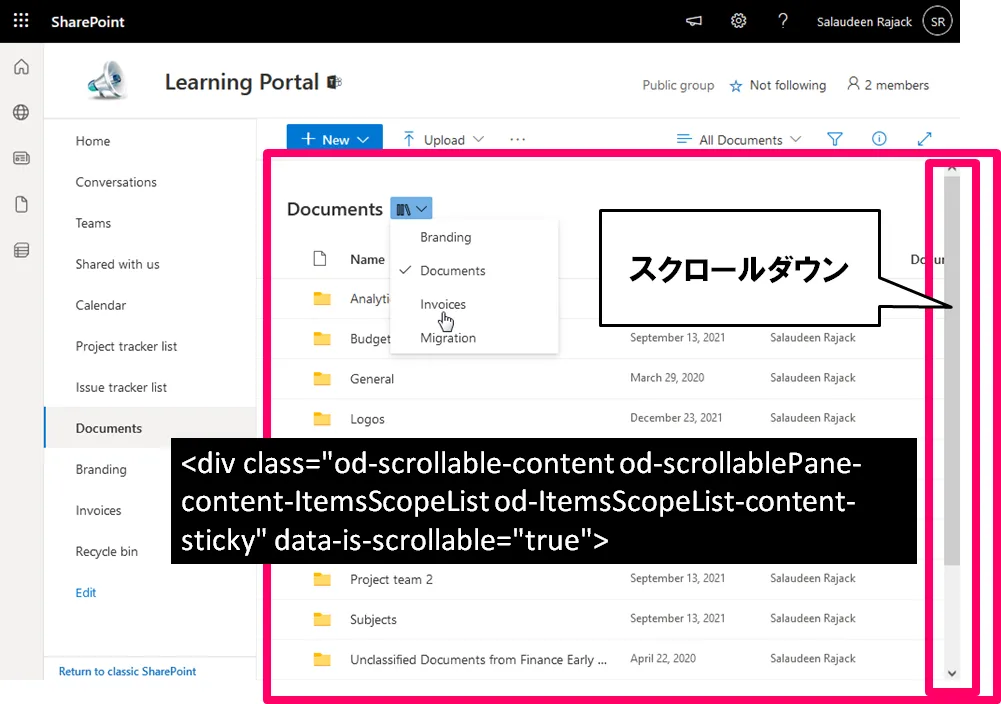
ChatGPTに教えてもらったが、スクロール可能な要素内でスクロールダウンを実行するには、JavaScriptを使用してその要素をスクロールさせるそうだ。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
from selenium import webdriver # Selenium WebDriverの初期化 driver = webdriver.Chrome() # もしくはFirefox、Edgeなどの他のWebDriverを使用します # ウェブページを開く driver.get("ウェブページのURL") # スクロール可能な要素を取得 scrollable_element = driver.find_element_by_class_name("od-scrollable-content") # JavaScriptを実行してスクロール可能な要素内でスクロールダウンを実現 driver.execute_script("arguments[0].scrollBy(0, 100);", scrollable_element) # ブラウザを閉じる driver.quit() |
このコードでは、execute_script()メソッドを使用してJavaScriptを実行し、scrollBy()関数を使って指定された要素内でスクロールを行う。
scrollBy()関数の第1引数は水平方向のスクロール量、第2引数は垂直方向のスクロール量を指定する。
もしくは、scrollIntoView() メソッドを使用して特定の要素が表示されるまでスクロールする……でも良いかもしれない(未確認)。
|
1 2 3 |
# スクロールダウンして特定の要素が表示されるまでループする target_element = WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.XPATH, "ファイルやフォルダ情報など"))) driver.execute_script("arguments[0].scrollIntoView();", target_element) |
要素が表示されるまで待機するために、WebDriverWait を使用し、visibility_of_element_located の条件を指定。
ドキュメントホームへ戻る処理
ブラウザの「戻る」で問題なかった。
|
1 2 |
# 前のページに戻る driver.back() |
最初「ドキュメント」ボタンを押そうとしてAttributeが変わって苦労したけど不要だった。
おわりに
ライブラリとして幾つかの処理を用意できれば、やれなくはない。
内部のHTMLが変わったり、意図しないファイルが置かれていたり……という場合には何度も異常終了してしまうだろう。
動的ページではなく簡易版の静的ページを用意する等……自動化フレンドリーなページを作ってくれても良い気がする。
因みにChatGPTはさすが!
最近はChatGPTからのアドバイスを
ChatGPT様より御神託を賜わった
と呼ぶようにしてる。

© 泡沫に神は微睡む/安田 のら/KADOKAWA
ソースコード
参考になるかはしらないけどソースコードは公開しておく。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 |
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC import logging import time import sys import os import functools print = functools.partial(print, flush=True) # ログのフォーマット設定 if (os.path.isfile("dl_sharepoint.py.log")): os.remove("dl_sharepoint.py.log") _format = "%(asctime)s %(levelname)s %(name)s :%(message)s" logging.basicConfig(filename="dl_sharepoint.py.log", level=logging.DEBUG, format=_format) # グローバルなドライバー変数を初期化 driver = None def login(): """日付ソートされたURLにアクセスする""" driver.get("https://xxx.sharepoint.com/sites/xxx/Shared%20Documents/Forms/AllItems.aspx?sortField=Modified&isAscending=false") time.sleep(10) def get_files_list(driver): """フォルダのファイルリストを返す(重複あり)""" for i in range(0, 10): # タイトルが表示されるまで待機 buttons = WebDriverWait(driver, 10).until( EC.presence_of_all_elements_located((By.CSS_SELECTOR, '.ms-DetailsList-contentWrapper button[data-automationid="FieldRenderer-name"]')) ) # print(f"total : {len(buttons)}") # ページ内の全てのbutton要素をクリック for button in buttons: title = button.get_attribute("title") print(f"{title}") # スクロール可能な要素を取得 scrollable_element = driver.find_element(By.CLASS_NAME, "od-scrollable-content") # JavaScriptを実行してスクロール可能な要素内でスクロールダウンを実現 scroll_amount = 60 * 40 # 調整が必要 driver.execute_script(f"arguments[0].scrollBy(0, {scroll_amount});", scrollable_element) # タイトルが表示されるまで待機 time.sleep(1) def click_reloads(driver): """フォルダをクリックする""" # タイトルが表示されるまで待機 buttons = WebDriverWait(driver, 10).until( EC.presence_of_all_elements_located((By.CSS_SELECTOR, '.ms-DetailsList-contentWrapper button[data-automationid="FieldRenderer-name"]')) ) print(f"total : {len(buttons)}") # ページ内の全てのbutton要素をクリック for i in range(len(buttons)): # ループの中でページ内のDOM情報を再度取得する sub_buttons = WebDriverWait(driver, 10).until( EC.presence_of_all_elements_located((By.CSS_SELECTOR, '.ms-DetailsList-contentWrapper button[data-automationid="FieldRenderer-name"]')) ) title = sub_buttons[i].get_attribute("title") print(f"{i} : {title}") # サブフォルダに移動 sub_buttons[i].click() time.sleep(1) # やりたい処理を書く # .. # .. # .. # 前のページに戻る driver.back() time.sleep(1) # スクロール可能な要素を取得 scrollable_element = driver.find_element(By.CLASS_NAME, "od-scrollable-content") # JavaScriptを実行してスクロール可能な要素内でスクロールダウンを実現 scroll_amount = i * 45 # 調整が必要 driver.execute_script(f"arguments[0].scrollBy(0, {scroll_amount});", scrollable_element) time.sleep(1) if __name__ == '__main__': try: # Chromeドライバーを初期化 driver = webdriver.Chrome() # ログイン login() # フォルダリストを抽出してみる get_files_list(driver) # ログイン login() # 更新ボタンをクリック click_reloads(driver) # 処理が完了したことをログに記録 logging.info("DONE") except Exception as e: # エラーが発生した場合はログにエラーを記録 logging.error(e) finally: # ドライバーを終了 if driver: driver.quit() |

