株価データをスクレイピングするスクリプトを書いたら、いつもまにかPCのメモリがMAXになっていた。
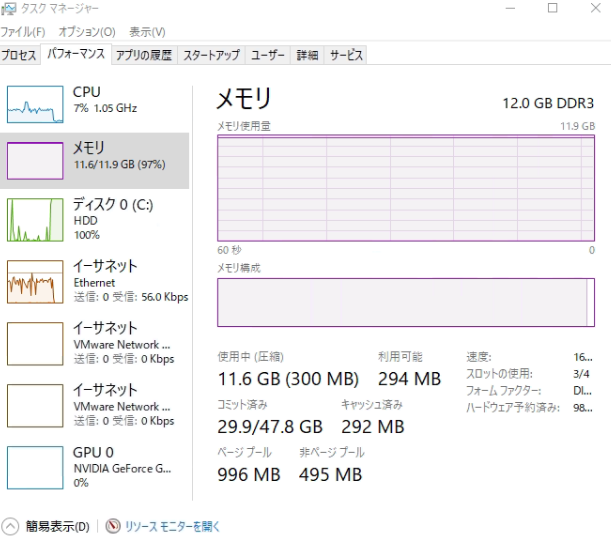
そして、Pythonのスクリプトが次のようなエラーを吐いた。
|
1 2 3 |
internal buffer error : Memory allocation failed : growing buffer I/O error : Memory allocation failed : growing input buffer Segmentation fault |
メモリリークしているなぁ・・・・。
Pythonは必要に応じて自動的にガベージコレクションを行う。
通常の用途では明示的にガベージコレクションを行う必要はない・・・はずだけど?
今回は駄文だ。いつも駄文?やかましい!
根本的に理解してない可能性があるので、賢い方々コメントをください。
そうそう、実は期間限定で日記のコメント欄を解放してるよ。
SPAMや荒らしが多い可能性もあるので、トライアルだ。
メモリリークを見えるようにする
問題解決のフローの最初は現状把握だって習ったよ。
gcモジュールでガベージコレクション
明示的にガベージコレクションを行うにはgcモジュールのcollect関数を呼び出す。
|
1 2 |
import gc gc.collect() |
これはPandasに限らず定番だが、使い終わったデータのメモリ領域を解放することが大事。
|
1 2 3 4 5 6 7 |
import gc # 何かしらの処理をしたdfがあるとする # 削除とガーベジコレクションをする del df gc.collect() |
C言語じゃないし、やってないな・・・。
そして、やってみても変わらないよ?
ガーベージコレクションの過程をデバッグ
ネット上で、メモリリーク(開放不可オブジェクト)を出力するサンプルを見つけた。
具体的には、gc.set_debugをコールして、リークの起きるオブジェクトをリサイクルせず、gc.garbageリストに保持させる。
その後、gc.collectでガーベージコレクションを強制実行した後で、開放不可オブジェクトを出力する。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# -*- coding: utf-8 -*- import gc import functools print = functools.partial(print, flush=True) def dump_garbage(): """ どんなゴミがあるか見せる """ # 強制収集 print('GARBAGE:') gc.collect() # 検出した到達不可オブジェクトの数を返します。 print('GARBAGE OBJECTS:') # 到達不能であることが検出されたが、解放する事ができないオブジェクトのリスト # (回収不能オブジェクト) for x in gc.garbage: s = str(x) if len(s) > 80: s = s[:77]+'...' print(type(x),'\n ',s) print('END GARBAGE OBJECTS:') if __name__=='__main__': gc.enable() # 自動ガベージコレクションを有効にします。 gc.set_debug(gc.DEBUG_LEAK) # メモリリークをデバッグするときに指定 # 循環参照を作成 l = [] l.append(l) # 循環参照オブジェクトを削除 del l dump_garbage() |
循環参照とは次のようにモジュールの参照がループしてしまうことを指す。
- モジュールAがモジュールBを参照
- モジュールBがモジュールAを参照
上記のスクリプトを動かした時の結果は次のとおり。
|
1 2 3 4 5 6 7 8 9 |
GARBAGE: GARBAGE OBJECTS: <class 'list'> [[...]] END GARBAGE OBJECTS: gc: collectable <list 0x00000238E16598C0> gc: collectable <dict 0x00000238E0F3B5C0> gc: collectable <module 0x00000238E0F3EE00> ...... |
そもそも、Python では、コードで使用されていたメモリーが OS に返されるという保証はない。
ガーベージコレクションで保証されるのは、オブジェクトで使用されていたメモリーが収集され、将来のいずれかの時点において別のオブジェクトで使用されるために解放されるということのみ。
試してみる
実際の作成したスクリプトはマルチスレッドを使ったり、CSVファイルを呼び出したり書き込んだりを何度も繰り返している。
どの部分を取り出してもリークしている可能性があるが、とりあえずpandas のread_htmlを呼び出した部分だけ確認してみる。
インストールに必要なライブラリは次のとおり。
|
1 2 3 |
$ /c/Python38/Scripts/pip install lxml $ /c/Python38/Scripts/pip install html5lib $ /c/Python38/Scripts/pip install bs4 |
lxmlはHTML以外にもXMLに唯一対応しており、標準ライブラリよりも高速で動作する。
html5libはBeautifulSoup4やHTML5などに対応しているが動作が遅い。
で、コードはこうなる。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# -*- coding: utf-8 -*- import gc import pandas as pd import functools print = functools.partial(print, flush=True) def dump_garbage(): """ どんなゴミがあるか見せる """ # 強制収集 print('GARBAGE:') gc.collect() # 検出した到達不可オブジェクトの数を返します。 print('GARBAGE OBJECTS:') # 到達不能であることが検出されたが、解放する事ができないオブジェクトのリスト # (回収不能オブジェクト) for x in gc.garbage: s = str(x) if len(s) > 80: s = s[:77]+'...' print(type(x),'\n ',s) print('END GARBAGE OBJECTS:') def get_stock_df(): gc.enable() # 自動ガベージコレクションを有効にします。 gc.set_debug(gc.DEBUG_LEAK) # メモリリークをデバッグするときに指定 # pandasでwebページの表をスクレイピング url = "https://info.finance.yahoo.co.jp/history/margin/?code=6758&sy=2021&sm=01&sd=1&ey=2021&em=01&ed=19&tm=d" list_df = pd.read_html(url, header=0) # オブジェクトを削除 del list_df dump_garbage() if __name__=='__main__': get_stock_df() |
Pandasを使うとwebページの表をスクレイピングするのが簡単過ぎ。
でも私が使うとメモリリークしてるけどね。
さあ、いよいよ実行。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
GARBAGE: GARBAGE OBJECTS: <class 'function'> <function TreeBuilder.__init__ at 0x000001DEF38DE280> <class 'function'> <function TreeBuilder.close at 0x000001DEF38DE310> <class 'function'> .. <class 'type'> <class 'xml.etree.ElementTree.TreeBuilder'> <class 'cell'> <cell at 0x000001DEF3A7EAC0: PythonParser object at 0x000001DEF3A7E5B0> END GARBAGE OBJECTS: |
・・・・これ、Pandaのライブラリを使った先でメモリリークしているじゃん。
ありえない気もするけど、メモリ増加は事実だ。
メモリリーク対策
問題、課題、施策。技術がないと施策が分からない。
教えて、ぐーぐる先生!私を助けて!
dtypeの設定で32bitにする
Pandasにおいては、これが結構効くらしい。
Pandasは自動で型が推定されるが、その際に必ず大きめの型が指定される。
例えば、float型の場合、float32で足りる場合でも、float64にする。
float32とfloat64だと、2倍のメモリ使用量の違いだ。
|
1 2 |
import numpy as np some_data = np.array(some_data, dtype=np.float32) |
ただし、32bitで必要な精度が得られるか事前に確認を。
型の自動指定
Kaggleで次のような便利な関数を見かけた。
各列の値をみて、メモリ使用量が最小になるように型を自動で設定してくれる関数だそうだ。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
def reduce_mem_usage(df, verbose=True): numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64'] start_mem = df.memory_usage().sum() / 1024**2 for col in df.columns: col_type = df[col].dtypes if col_type in numerics: c_min = df[col].min() c_max = df[col].max() if str(col_type)[:3] == 'int': if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max: df[col] = df[col].astype(np.int8) elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max: df[col] = df[col].astype(np.int16) elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max: df[col] = df[col].astype(np.int32) elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max: df[col] = df[col].astype(np.int64) else: if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max: df[col] = df[col].astype(np.float16) elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max: df[col] = df[col].astype(np.float32) else: df[col] = df[col].astype(np.float64) end_mem = df.memory_usage().sum() / 1024**2 if verbose: print('Mem. usage decreased to {:5.2f} Mb ({:.1f}% reduction)'.format(end_mem, 100 * (start_mem - end_mem) / start_mem)) return df |
この関数にDataFrameを入れてあげることで、メモリ使用量を削減できる。
関数が処理を実行する時間のオーバーヘッドはあるものの、メモリ利用率に関しては効果が大きい。
read_htmlを使わない
自分でパースする関数を作ってしまう方法だ。
ここに工数を使いたくないので、これは最後の手段。
スクリプトを一度修正させる
Pythonでfor文回すのをやめる。
Pythonで1周動かすのが問題ないなら、ループ処理をバッチファイルで制御する。
例えば、次のようにする。
exec.bat
|
1 2 3 4 |
cd /d %~dp0 for /l %%n in (0,1,29) do ( python main.py %%n ) |
main.py
|
1 2 3 4 5 |
import sys args = sys.argv i = int(args[1]) if __name__ == '__main__': mykeras(i) |
この方法をネットで見つけて笑ってしまった。
が、工数を考えると実はこれで十分かもしれない。
で、どうしたか?
バッチファイルで凌ぐことにした。
根本原因は解決してないが、日曜大工だと割り切って次の作業に取り掛かろう。
うーん、気持ち悪いけど、ここに時間を割いてる余裕はない。
さすがにデータ取得に時間をかけてる場合じゃない。