
日本人の多くは、日本人が150年前の文書が読めません。
家系図調査は「除籍謄本」や「聞き込み」調査が完了したら、次は各研究機関や施設を訪ねて、江戸時代の古文書を調査することになります。
古文書に書かれている字は一般的には「草書」と呼ばれる書体で、「くずし字」という言い方もします。

この「くずし字」を読むのが大変で、読むと言っても「字体の暗記」がメインとなります。
たとえば草津の広島かきに関する文献「小川家文書」の中で、「保」は次のように記載されています。


通常は、次のような辞書を片手に比較しながら「くずし字」とにらめっこになります。
正直、辞書買って片手に読んでみたが、パターン認識は人間のやることじゃない。
それならコンピュータの方が早くない?
最近はくずし字ブームなのか、多くの「くずし字検索サービス」「くずし字文字データベース」が無償公開されています。
大学共同利用機関法人情報・システム研究機構国立情報学研究所(NII)と、大学共同利用機関法人人間文化研究機構国文学研究資料館(国文研)は、江戸時代の古典籍に書かれた「くずし字」の「日本古典籍字形データセット」をオープンデータとして無償公開しました。
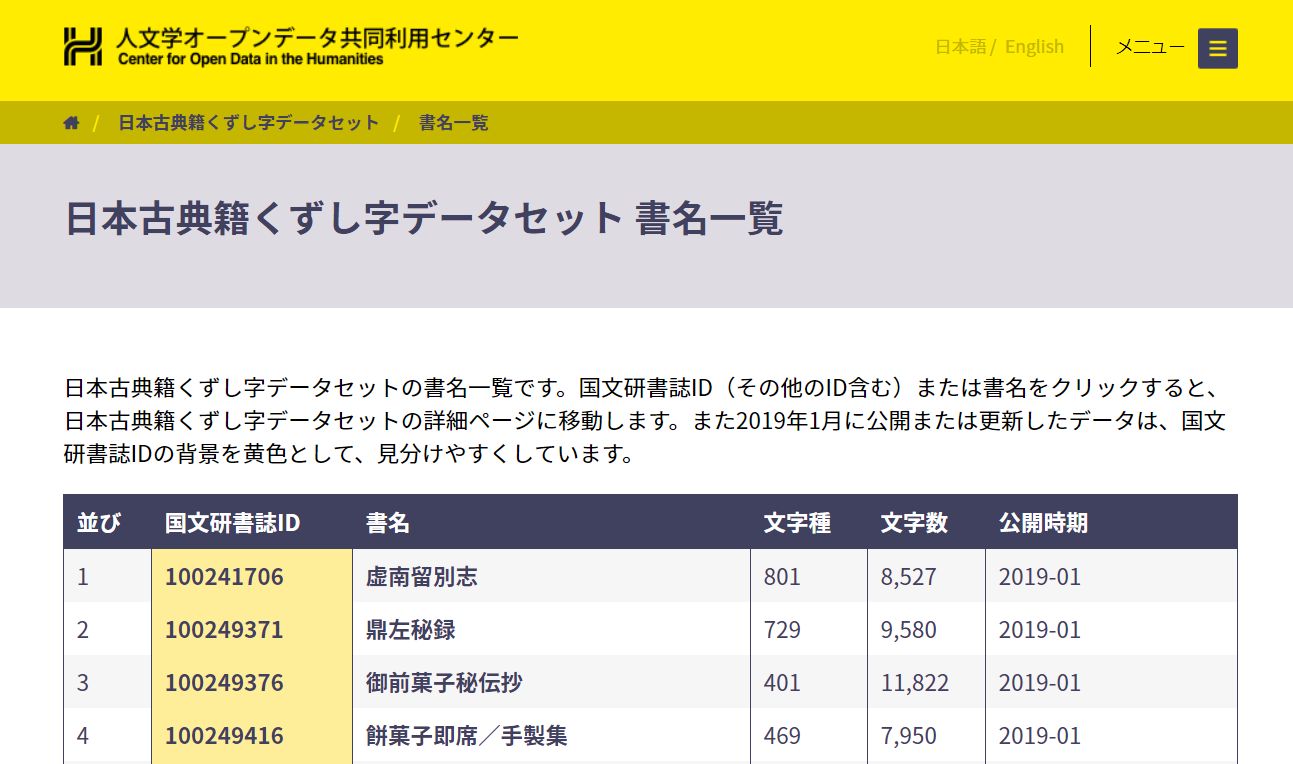
現在、絶賛データセット拡張中で、先月末で次のようなものが置いてあります。
- 日本古典籍データ(点数3,126、コマ数が609,631点)
- 日本古典籍くずし字(文字種4,645、文字数684,165文字)
- ディープラーニングを用いた文字認識のサンプルプログラム
これにより、多くの新サービスが出てきました。
凸版印刷、くずし字翻刻を手軽に公開 ビューワ「ふみのは」
凸版印刷が文字画像を位置情報とともに切り出した字形データベースを構築し、この字形データベースから類似字形検索により翻刻対象古典籍の文字の文字コードを特定するシステムを構築しました。
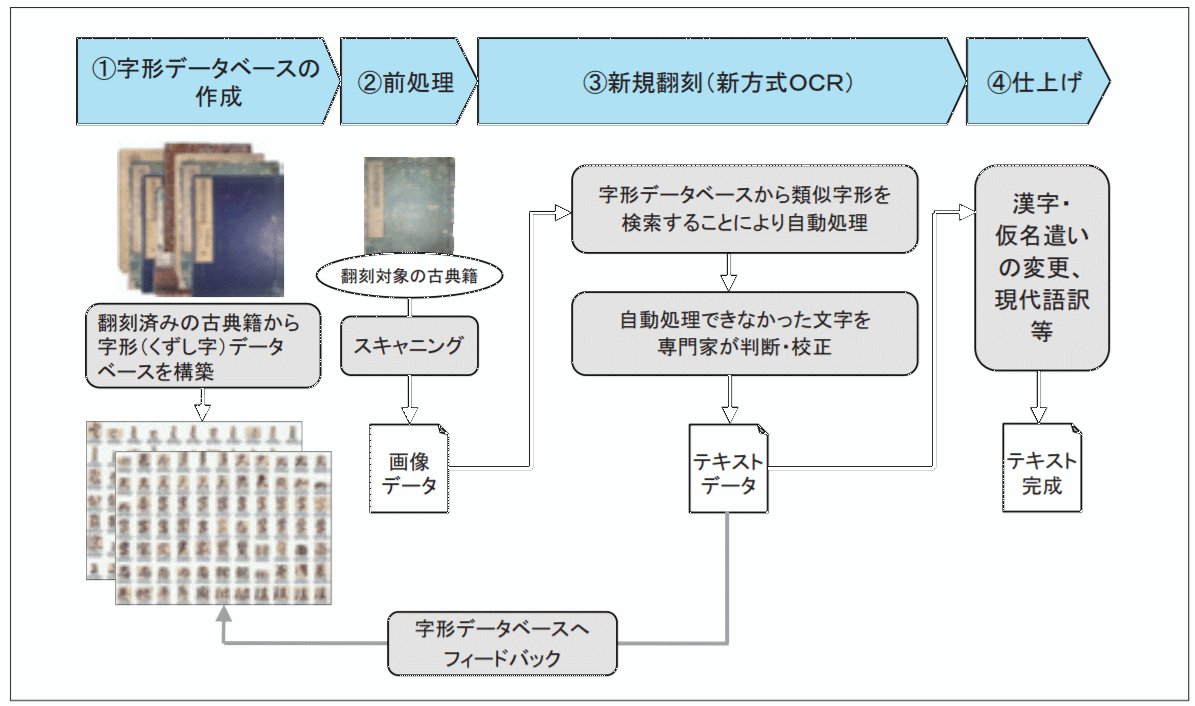
ただし、これは有償で個人が気楽に使えるものではないです。
古文書や木簡に書かれているくずし字をシステムで自動解析するウェブサービス「MOJIZO」
東京大学史料編纂所と奈良文化財研究所が、解析したい文字画像をアップロードすると、奈良文化財研究所の木簡画像と東京大学史料編纂所のくずし字画像から形状が近い字形を候補としてリストアップするサービス「MOJIZO」を無償公開してくれています。
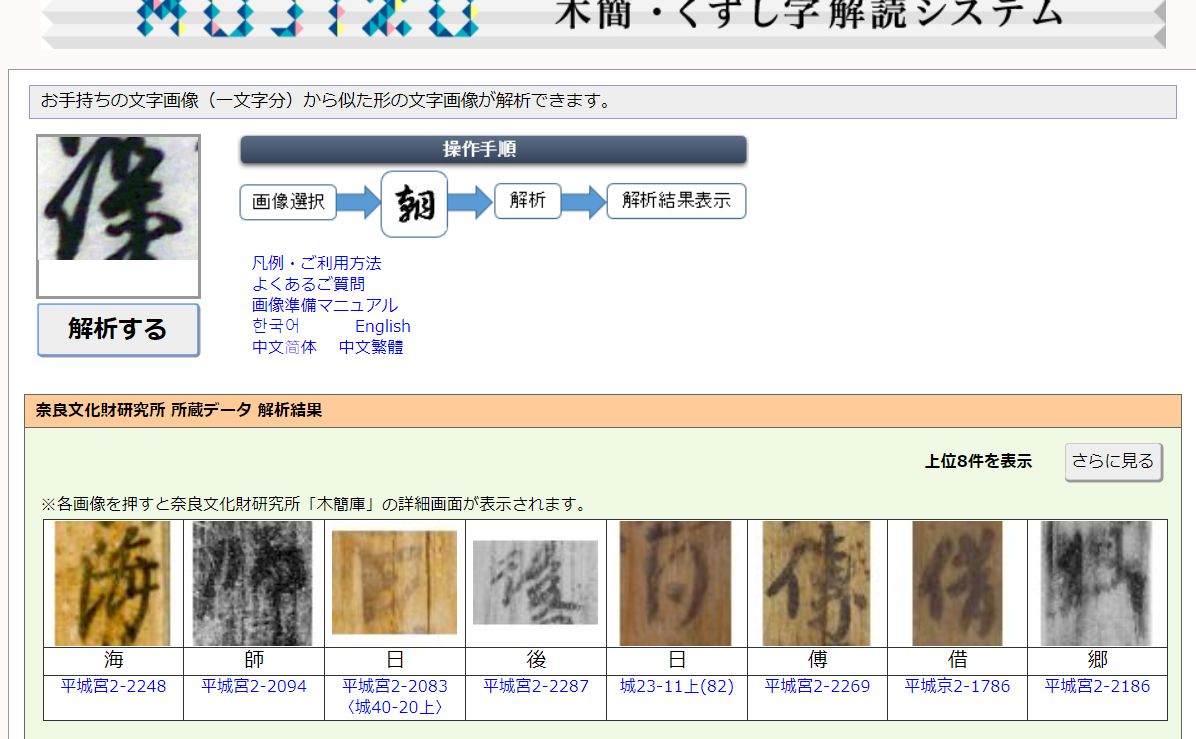
このサイトは一文字単位でしか検索できませんが、バッチ処理的なシステムを組めば「くずし字解読」が作成できそうです。
ちなみに「保」を切り出してみましたが、正解文字は出ませんでした・・・。
「切り出し方」や「解像度」によって大きく検索結果が変わるのかもしれません。
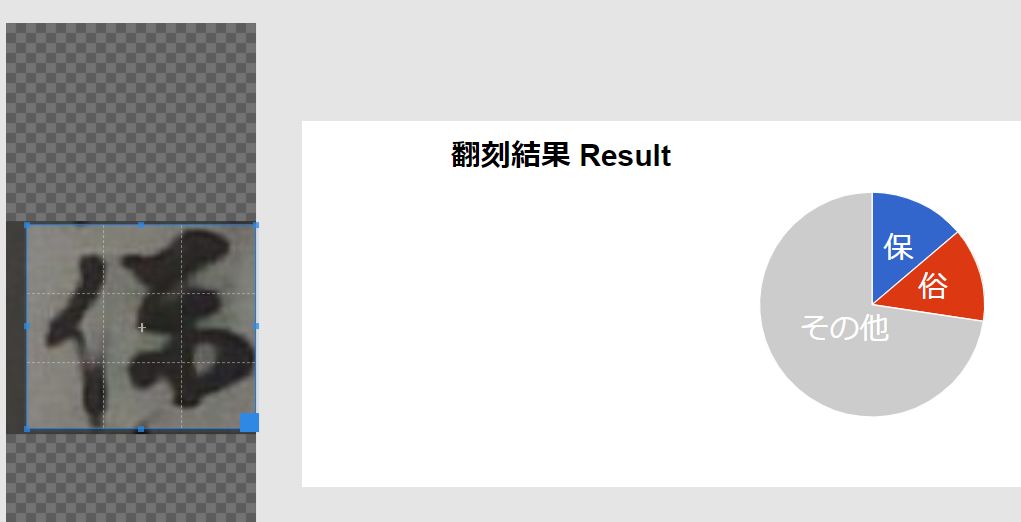
豊田高専くずし字翻刻WWWサービス
ディープラーニングを用いたくずし字の自動翻刻システムの構築を目的として、『日本古典籍字形データセット』をはじめとするオープンデータから40万字以上のくずし字画像を利用してモデルを学習させたそうです。

ちなみに「保」を切り出してみましたが、正解文字は出ませんでした・・・。
ただし、もう一つの文字は見事 正解!
第21回 PRMUアルゴリズムコンテスト「この文字読めますか?〜くずし字認識にチャレンジ!〜」
「第21回 PRMUアルゴリズムコンテスト」の課題になっており、学生さんがディープラーニング使って「くずし字」解読にチャレンジしています。

ちなみに、第21回では、東京農工大のベトナム人学生2人が最優秀賞でした。
Convolutional Neural Network (CNN: 畳込みニューラルネットワーク)、Bidirectional Long Short-term Neural Network (BLSTM: 双方向長・短期記憶ニューラルネットワーク)、そして,Connectionist Temporal Classification (CTC: コネクショニスト時系列識別法)を 3 層に組み合わせ、Deep Convolutional Recurrent Network (DCRN: 深層畳込み再帰ネットワーク)を構成したそうです。
まとめ
上記技術に関して、公開されているPDFは次のようなものがあります(一部)。
- 類似文字検索機能をそなえた電子くずし字辞典の開発(国際日本文化研究センター・研究部)
- CNNと文字のアスペクト比を用いたくずし文字認識(京都大学大学院情報学研究科)
- ディープラーニングによる変体仮名の翻刻およびWWWアプリケーション開発(豊田工業高等専門学校)
「第7回アルゴリズムコンテスト(’03)」の優秀賞保持者の私としては、ディープラーニング初心者だが、材料はそろっているので、少しずつ文字解析にチャレンジしていきたい。
が、先駆者達の精度を見ると、私が読みたい古文書の解析無理かな……

