毎年年末年始やGWに技術学習・Webサイト構築してきたのに、今年は何もしていない・・・
- 2017年始:opencv使った社内アイデアコンテスト9件作成
- 2017年GW:テクニカル指標学習・protra、omegachart改編
- 2018年始:車の破壊とパソコン窃盗処理
- 2018年GW:仕事の事で頭いっぱい
これではいかんので、過去6回挫折している人工知能に手を出しました。
- 2001年:人工知能専攻するも理解できず
- 2002年:遺伝的アルゴリズムのサンプル貰うも分からず
- 2014年:ディープラーニング学ぶも3日坊主
- 2015年:chainer知るもインストールで終わり
- 2017年:tensorflowで mnistサンプル実行で終わり
- 2017年:はじめてのディープラーニング買うも3日坊主
そもそも人工知能の学科卒業だし、画像認識専攻です。
主成分分析、非線形最小二乗法などを研究で利用していたのだが、なぜ世の中に遅れをとらにゃいかんのだ・・・
はい。技術力が無いからです・・・。
なら、アプローチは
簡単なレベルから成功体験を少しずつ築く
です。
最近はディープラーニングに関するブログも増え、GUIやWebブラウザから学習できる簡単なサービスも増えました。
が、株のバックテスト環境検討のときと同じで、最低限のプログラム学習は兼ねたいです。
施策は二つのアプローチで進めます、少しずつ少しずつ・・。
【基礎から学ぶ】
- パーセプトロン(単純、多層)
- ニューラルネットワーク(活性化関数)
- ニューラルネットワークの学習(損失関数、勾配法)
- 誤差逆伝搬法
- 畳み込みニューラルネットワーク(畳み込み層、プーリング層、CNN)
- ディープラーニング
【簡単フレームワークから学ぶ】
- Keras(ケラス)によるモデル構成
- PyTorchによるモデル構成
- Tensorflowによるモデル構成
【目標】
ディープラーニングを理解すること
※ ここでいう「理解した」状態とは?
- 数式による基礎概念を理解し、ゼロから実装できること
- 主要フレームワークの特徴を理解し、自分で学習させたいモデル形成できること
ディープラーニングを学習するには、この本がオススメです。
なぜプログラム言語は pythonか?
matlabは特に行列計算が容易に書けますが、ライセンスが有料なので気軽には使えませんでした。
そこでpythonに、matlabのような使い勝手の良い数値計算ライブラリ(numpyとかmatplotlibとか)が開発されました。
この頃から機械学習を利用する上で便利な言語としてpythonが大人気になりました。
なぜ keras からか?
最も初心者に優しいのはKerasだからです。

層をただただ積み重ねていくだけという実装でディープラーニングが試せます。
Kerasの登場により、ディープラーニング入門は誰にでもできるという状況が訪れました。
これにより、「どのような層を配置して、どれくらいの数どのように学習をするか」という概念の理解からスタートできます。
ただし、Sequentialと既存の目的関数で事足りる場合は良いのですが、それを外れる面倒なので早めにPyTorchにシフトする方がよいとのことです。
なぜ 株価予測を題材にするのか?
個人的興味もあるけれど、連続的でディープラーニングを理解するのに適しているからです。
過去の株価データはネット上に公開されており、誰でも容易に入手できる。しかも、1980年代くらいまでの高々数千件程度しかないため、学習もすぐ終わるので、パラメーターをいろいろ変えてその影響を見るということが、容易にできる。
このように、株価予測というテーマは、誰にでも簡単にできて、ニューラルネットワーク構築上のノウハウ取得にも有益なテーマと言える。
【引用】Kerasを用いたディープラーニング(LSTM)による株価予測
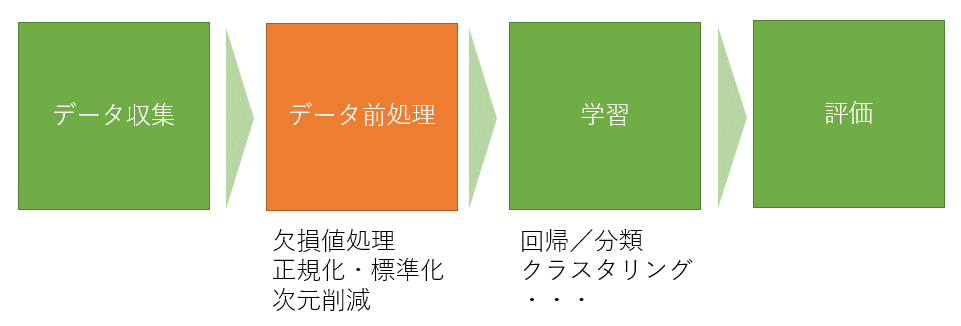
Kerasのおかげて、「データの前処理(加工)」の労力が7~8割となります。
このデータ前処理は、今までのテクニカルトレードの経験で私にも多少の優位性があります。
ちなみに、入力データを何にするかは大事で、単に株価を渡しても予測の正解率は一般的に「50%~55%」程度となります。
でも、そこは今回の本質ではありません。
「ブラックショールズ方程式」でも、株価はランダムに変動するというモデルによって理論化されていると言っています。
しばらくは基礎概念理解を優先することにします。
kerasでのネットワークを組み方
kerasでのネットワークを組み方の例です。
【引用】KerasでDeep Learning:LSTMで日経平均株価を予測してみる
|
1 2 3 4 5 6 7 8 9 10 11 |
from keras.models import Sequential from keras.layers.core import Dense, Activation from keras.layers.recurrent import LSTM in_out_neurons = 1 hidden_neurons = 100 model = Sequential() model.add(LSTM(hidden_neurons, batch_input_shape=(None, length_of_sequences, in_out_neurons), return_sequences=False)) model.add(Dense(in_out_neurons)) model.add(Activation("linear")) |
DenseというのはDensely-Connected なニューラルネットの層を指します。
学習は次のように行います。
|
1 2 |
model.compile(loss="mean_squared_error", optimizer="adam") history = model.fit(X_train, y_train, batch_size=600, epochs=50, validation_split=0.2) |
たったこれだけで、ディープラーニングが組めます。
が・・・まだ、何をしているのか、よく分からない・・。
仕方ないので、ネット上からサンプルコードを見つけてきて、実行することにします(コードは後述)。
でも、このサンプルコードはSequential()を呼び出してないなあ・・・うーん。
学習結果
予測データと、2017年の実株価をプロットしてみます。
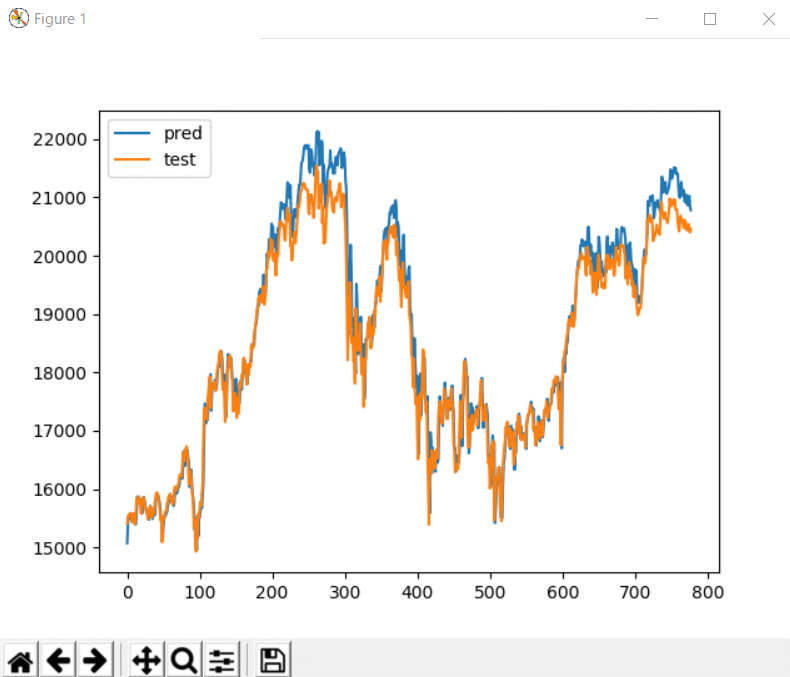
グラフで見ると、テストデータと予測が一致していて精度よく見えてますが・・。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
.... 3151/3151 [==============================] - 12s 4ms/step - loss: 51.3350 - price_loss: 50.6430 - updown_loss: 0.6920 - updown_acc: 0.5281 - val_loss: 22.4975 - val_price_loss: 21.8009 - val_updown_loss: 0.6966 - val_updown_acc: 0.4781 Epoch 100/100 ... 3150/3151 [============================>.] - ETA: 0s - loss: 56.6516 - price_loss: 55.9601 - updown_loss: 0.6914 - updown_acc: 0.5276 3151/3151 [==============================] - 11s 4ms/step - loss: 56.6340 - price_loss: 55.9426 - updown_loss: 0.6914 - updown_acc: 0.5275 - val_loss: 6.0334 - val_price_loss: 5.3441 - val_updown_loss: 0.6894 - val_updown_acc: 0.5540 |
ここで、出力結果の説明です。
loss: 56.6340
price_loss: 55.9426
updown_loss(学習用データでの収束度?): 0.6914
updown_acc (学習用データでの精度): 0.5275
val_loss: 6.0334
val_price_loss: 5.3441
val_updown_loss(検証用データでの収束度?): 0.6894
val_updown_acc(検証用データでの精度): 0.5540
updown_acc、val_updown_accのどちらも 50%~55% 程度となっています。
単純に考えると上がるか下がるかが当たる確率は 50% です。
つまり、50%~55% という予測精度は 2 値予測においては高い精度とは言えません。
ちなみに結果が出るまで17分かかりました。
バックテスト結果
まだ方法が分からず・・・。
ソースコード
sklearn 0.19以後ValueErrorがでたり、k-dbは閉鎖したので、いくつか修正しています。
また1330.csvの中身は、protraの取得したデータを使っています。
【元コード】ディープラーニングで株価予測するときの罠
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 |
import pickle from pathlib import Path import pandas as pd import numpy as np import matplotlib.pyplot as plt from keras.layers import Input, Dense, LSTM from keras.models import Model from keras.callbacks import CSVLogger from sklearn.preprocessing import StandardScaler CSV_FILE = "1330.csv" # 取得したデータを読み込んで終値だけを取り出す def read_data(): df = pd.read_csv(CSV_FILE) closes = df['finish'].values # sklearn 0.19以後ValueError # Reshape your data either using array.reshape(-1, 1) if your data has a single feature return closes.reshape(-1,1) # LSTM を Keras を使って組む def create_model(): inputs = Input(shape=(10, 1)) # 日経平均株価の値を直接予測するため活性化関数は linear # 中間層の数は 300(理由なし) x = LSTM(300, activation='relu')(inputs) price = Dense(1, activation='linear', name='price')(x) updown = Dense(1, activation='sigmoid', name='updown')(x) model = Model(inputs=inputs, outputs=[price, updown]) # 後で検証に使用するため 2 値予測も含んでいる model.compile(loss={ 'price': 'mape', 'updown': 'binary_crossentropy', }, optimizer='adam', metrics={'updown': 'accuracy'}) return model # 全データのうち、80% を学習用データ、20% を検証用データに割り当て def build_train_test_data(base_data): # 特徴量の尺度を揃える:特徴データを標準化して配列に入れる scaler = StandardScaler() # 特徴データを標準化(平均0、分散1になるように変換) data = scaler.fit_transform(base_data) x_data = [] y_data_price = [] y_data_updown = [] # 10 日分の日経平均株価を入力として、1 日後の日経平均株価を予測 for i in range(len(data) - 10): x_data.append(data[i:i + 10]) y_data_price.append(data[i + 10]) y_data_updown.append(int((base_data[i + 10 - 1] - base_data[i + 10]) > 0)) x_data = np.asarray(x_data).reshape((-1, 10, 1)) y_data_price = np.asarray(y_data_price) y_data_updown = np.asarray(y_data_updown) # 学習データサイズ train_size = int(len(data) * 0.8) # 学習データ x_train = x_data[:train_size] y_train_price = y_data_price[:train_size] y_train_updown = y_data_updown[:train_size] # テストデータ x_test = x_data[train_size:] y_test_price = y_data_price[train_size:] y_test_updown = y_data_updown[train_size:] return x_train, y_train_price, y_train_updown, x_test, y_test_price, y_test_updown, scaler def main(): model = create_model() data = read_data() x_train, y_train_price, y_train_updown, x_test, y_test_price, y_test_updown, scaler = \ build_train_test_data(data) # エポックは 100、バッチサイズは 10 model.fit(x_train, [y_train_price, y_train_updown], validation_data=(x_test, [y_test_price, y_test_updown]), epochs=100, batch_size=10, callbacks=[CSVLogger('train.log.csv')]) # モデルのsave/load model.save('model.h5') with open('scaler.pkl', 'wb') as f: pickle.dump(scaler, f, protocol=pickle.HIGHEST_PROTOCOL) pred = model.predict(x_test)[0][:, 0].reshape(-1) # 標準化を戻す pred = scaler.inverse_transform(pred) y_test_price = scaler.inverse_transform(y_test_price) # plot準備 result = pd.DataFrame({'pred': pred, 'test': y_test_price.reshape(-1,)}) result.plot() plt.show() if __name__ == '__main__': main() |