
Excelってピボットテーブル使った分析でお世話になっているけど、その前にデータクレンジングが必要。
そして、手抜きしてExcelの関数でやろうとすると非常に面倒くさい。
B2にある「文字」と「数字」が混じった文字列(空の場合あり)から「数字」だけを抽出したい
例)「文字123文字」→「123」
ネットで調べると検索には沢山ひっかかる。

で上から順に見ていくと
- どうでも良いSEO対策向けの長々とした文章
- 最後まで見ても意図とは異なる文章
「Excel関数」って言ってるだろ!糞検索エンジン!

で、何度か検索ワードを変えて、ようやく期待するサイトに辿り着きExcel関数が出来上がり。
|
1 |
=CONCAT(IFERROR(VALUE(MID(IF(B2="",0,B2),SEQUENCE(LEN(IF(B2="",0,B2))),1)),"")) |
でも、期待結果と異なる文字列もあった。
見てみると「16.6kcal」から「16.6」のように小数点は残してもらいたいけど「166」となってしまった。
そのような場合は、再度検索を継続するんだけど、残念ながら欲しい結果は全く見つからず……
このように2000年頃から20年間は検索に多くの時間を費やした。
2000年前はExcel書籍で調査するぐらいしか方法無かったけどね。
2023年からはGPTによる検索の時代よ。
Bing GPT先生!お願いします!
Excel関数で「小数点と数字」だけを取り出すには、以下のような関数を使うことができます。
=LEFT(RIGHT(D5,LEN(D5)-FIND(“.”,D5)),FIND(” “,RIGHT(D5,LEN(D5)-FIND(“.”,D5))))
この楽さ!
夢描いていた自動コード生成の世界より2つぐらい前進しちゃった感じがする。
でも、Bing BPT先生、上手く動作しませんぜ?
申し訳ありません。先ほどの関数に誤りがありました。正しい関数は以下の通りです。
=IFERROR(LEFT(D5,FIND(” “,D5)-1)+0,””)

いや違うだろ糞ww
そもそもExcel関数でやろうと思ったのが間違いだった。
そもそもやりたいこと
成人男性の栄養成分摂取量に対し、普段食べている栄養成分を「引く」ことで、不足している栄養素を把握したい。
例)摂るべきタンパク質 = 65g – (2.1g + 8.7g + 6.6g + 3.9g) = 43.7g
「kcal」「g以上」「μg」「小数点」「値無し」など色々とあって計算が簡単にはできない。
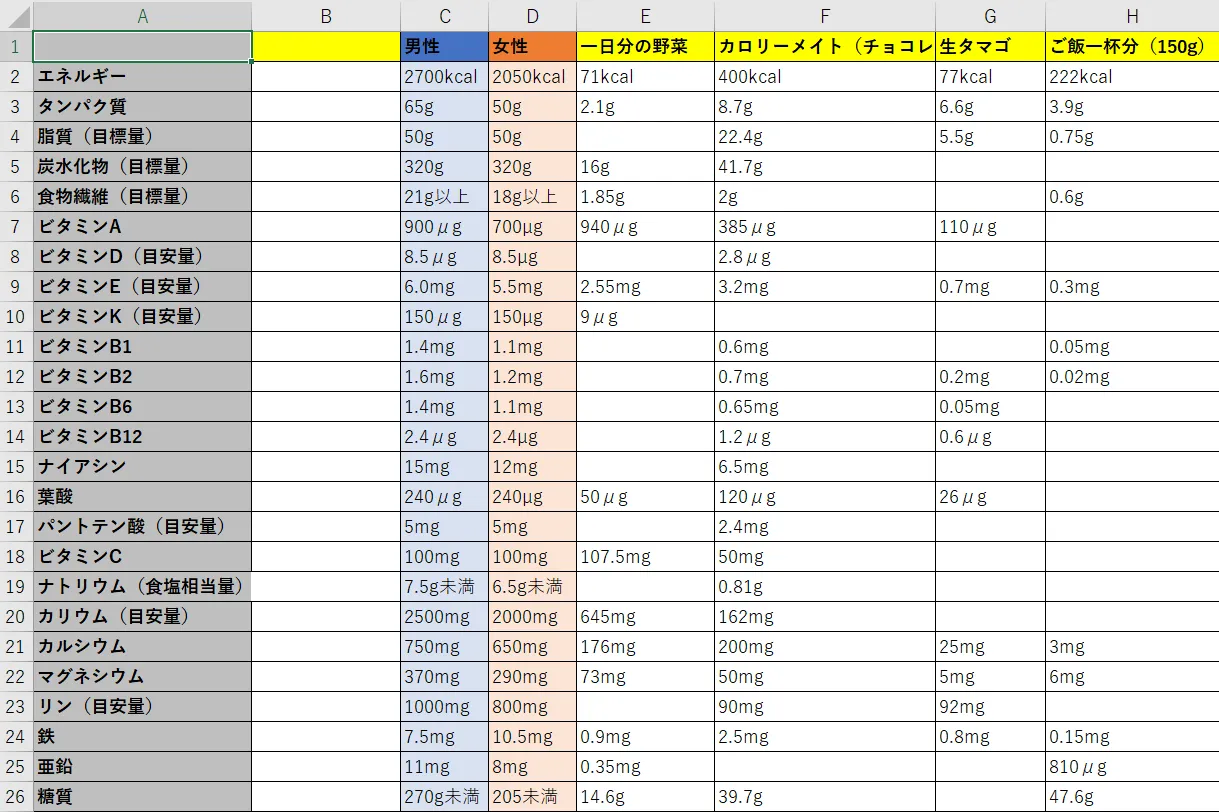
Excel関数で簡単に対応できるかな……と思ったけど、Pythonでやる方が早そうだ。
Pythonを使ってExcel上で文字列から整数・小数を抜き出す
エクセルファイルを読み込むには、外部ライブラリのOpenPyXL を利用する。
|
1 2 3 4 |
import openpyxl wb = openpyxl.load_workbook("栄養.xlsx") ws = wb["栄養"] |
そして文字列から小数点や数字を抜き出すには、不要な文字の対象に「 . 」は含まれないと仮定して次のような書き方ができる。
|
1 |
result = res = re.sub(r"[^\d.]", "", s) |
そしてPythonは「条件式(三項演算子)」「ラムダ式」などが使えるので便利。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 条件式(三項演算子)の基本パターン x = 101 s = 'odd' if x % 2 else 'even' print(s) # odd # 条件式のネスト s = 'positive' if x > 0 else 'negative' if x < 0 else 'zero' print(s) # positive # 内包表記と条件式 l1 = [3, 4, 6, 0, 1] l2 = ['odd' if x % 2 else 'even' for x in l1] print(l2) # ['odd', 'even', 'even', 'even', 'odd'] # ラムダ式と条件式 l1 = [3, 4, 6, 0, 1] it = map(lambda x: 'odd' if x % 2 else 'even', l1) l2 = list(it) print(l2) # ['odd', 'even', 'even', 'even', 'odd'] |
で、計算させてできたExcelは次のとおり。

Pythonを使うほうが早かったね。
おわりに
ソースコードと使ってExcel関数は、SEO対策しまくったサイトに簡単なのが少し載っている程度なので、GPTの学習データが足りないのか提案が良くない……のかな?
PythonだとExcelファイルが変わっても再利用が容易だし、今後はPythonでのExcel利用を覚えていこう。
【ソースコード】
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
# -*- coding: utf-8 -*- import re import sys import openpyxl import functools from openpyxl.styles import Font print = functools.partial(print, flush=True) # /c/Python311/Scripts/pip install openpyxl # /c/Python311/python excel_auto.py 栄養.xlsx 栄養 g_row_list = [ '一日分の野菜', 'ライトミールブロック', '生タマゴ', 'カップヌードルPRO', '納豆極小粒ミニ3', 'ご飯一杯分(150g)', # 朝食 'ご飯一杯分(150g)', # 昼食 ] # 該当するセルに文字列があれば指定列に記載 def _calc_delta(ws, RowNames): global g_row_list # 1行目は無視 for row in ws.iter_rows(min_row=2, max_row=ws.max_row): # 文字列から小数点&数字を抜き出す total = 0.0 for list in g_row_list: # 条件式(三項演算子)と := (ウォルラス演算子)を利用 total += float(re.sub(r"[^\d.]", "", ('0' if (tmp:=row[RowNames[list]].value) is None else tmp))) value = float(re.sub(r"[^\d.]", "", ('0' if (tmp:=row[RowNames['男性']].value) is None else tmp))) result = value - total suffix = re.sub(r"[^\D]", "", row[RowNames['男性']].value) row[RowNames['不足栄養素']].value = str(round(result,2)) + suffix def main(filename, bookname): wb = openpyxl.load_workbook(filename) ws = wb[bookname] # 挿入したい行作成 ws['B1'].value = '不足栄養素' # 行の高さを変更 ws.row_dimensions[1].height = 20 # 1行目の文字列を太字にする font = Font(bold=True) for row in ws.iter_rows(): for cell in row: if cell.row == 1: ws[cell.coordinate].font = font ## Create a dictionary of column names RowNames = {} Current = 0 for COL in ws.iter_cols(1, ws.max_column): RowNames[COL[0].value] = Current Current += 1 _calc_delta(ws, RowNames) # 別名保存 wb.save("Sample.xlsx") if __name__ == '__main__': args = sys.argv main(args[1], args[2]) |

