
自然言語処理はAI(人工知能)分野で今最も注目の集まる分野です。
一方で、一昨年にBERTが発表され注目を浴びたものの、XLNetやRoBERTaも出てきており、技術進歩の早さについていくのに大変な領域です。
GPUが使えるか確認する
グラフィックボードは、ほとんどが以下の3つ「NVIDIA GeForce」「AMD Radeon」「Intel HD Graphics」の製品となります。
Windows10なら、デスクトップで右クリック → 「ディスプレイの設定」 → 「ディスプレイの詳細設定」 → 「アダプタのプロパティの表示」でグラフィックボードの情報が表示されます。
NVIDIA社・AMD Radeonのグラフィック機能
グラフィック専用のCPU(GPU)を利用しており、高性能なグラフィックボードも多くあります。
従来のディープラーニングのGPU環境(計算環境)にはNVIDIAのGPUとCUDA(NVIDIAが提供するライブラリ)の一択でした。
近年は、UbuntuならAMD環境としてRocm(Radeon Open Compute)とRocm用TensorFlowを使ったり、OpenCL、TensorFlowの代わりにPlaidMLとKetasを使う選択肢もあります。
Intel社のCPU内臓グラフィック機能
グラフィックは専用のCPU(GPU)が使用されますが「Intel HD Graphics」は、CPU内にグラフィック機能も内蔵されています。
こっちは駄目だぁ〜。私のノートパソコンはこっち。開発用じゃないし。
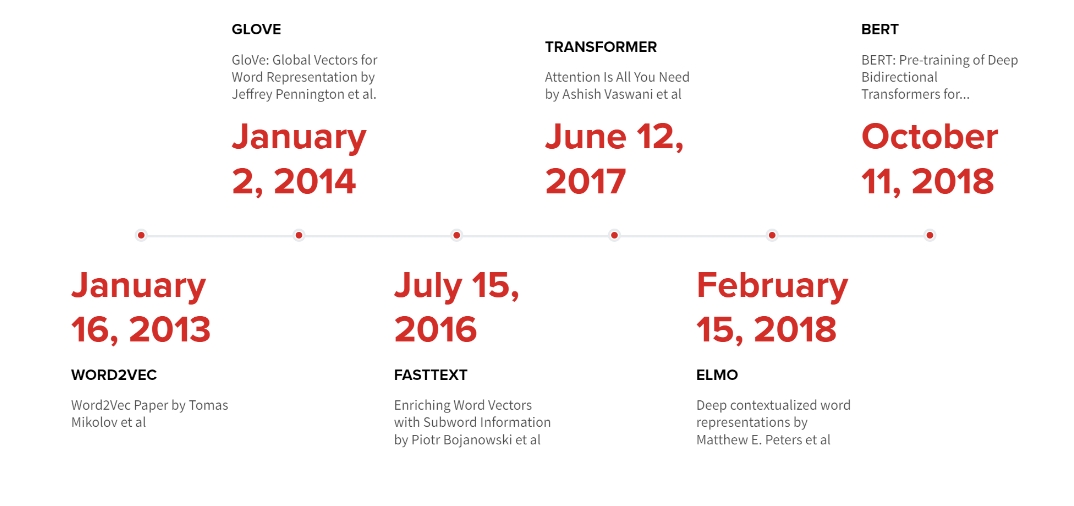
自然言語処理の代表的なモデル・アルゴリズムまとめ
代表的なモデル・アルゴリズム
| 名前 | 特徴 |
|---|---|
| Word2Vec | 実際にはCBOW(Continuous Bag-of-Words)モデルとSkip-gramモデルの二つ |
| GloVe | 単語ベクトルを獲得する手法。共起行列を用いたカウントベースの手法と、Word2Vecのような推論ベースの手法を合わせた手法 |
| fastText | Word2Vecとその類型のモデルでそれまで考慮されていなかったサブワード・活用形をまとめられるようなモデル |
| ELMo | 単語ベクトルを獲得する手法。Word2Vecと異なり、文脈を考慮した単語ベクトルを獲得できる |
| BERT | 近年の大きなブレイクスルー |
| MT-DNN | Multi-Task Deep Neural Network。ロジック自体はBERTも参考にしており、性能はBERTを上回る |
| XLNet | BERTの事前学習方法を改良したモデル。タスクの結果だけ見るとBERTの上位互換的な性能をしている |
| RoBERTa | BERTの事前学習方法(パラメータチューニング)を改良したモデル。XLNetより高い性能を出している |
| ALBERT | BERTの軽量版。論文によるとBERTと比較して軽量で高速で高精度 |
形態素解析器の比較
日本語で自然言語処理を行う場合、英語とは異なり区切りが明確でないため、分離するために利用します。
一昔はJUMAN をベースに解析速度と使い勝手の向上を目指した「ChaSen(茶筌)」が有名でした。
| 名前 | 特徴 |
|---|---|
| MeCab | 高速、システムと辞書は分離、mecab-python3の方が高速、辞書はIPA辞書推奨、Unidic辞書やNEologdも利用される |
| JUMAN | 京大黒橋研が開発した形態素解析器。Pythonから呼び出すにはPyKNPを使う |
| JUMAN++ | RNN言語モデルを使うことで非常に高精度な形態素解析を実現。解析速度がとても遅い |
| Sudachi | 徳島人工知能NLP研究所が開発した形態素解析器。MeCabと精度は同じ |
辞書
| 辞書名 | 特徴 |
|---|---|
| IPA辞書 | 学校文法に似た品詞体系なので分かりやすい |
| Unidic | 現代日本語書き言葉均衡コーパス。「短単位」を元に構築した辞書 |
| NEologd | Web上のあらゆる新語が追加された巨大な辞書 |
BERT
BERTは、Bidirectional Encoder Representations from Transformers(Transformerを活用した双方向的エンコード表現)の略です。
ただ一番性能の高いBERTは安GPUではFine Tuningはおろか推論すらOut of memoryで動きません。
目の前に自然言語処理の最先端があるのにそれを使えないのは悔しい限りです。
民生向けコンピューター(GPU非搭載)を使ってBERTを試すために「bert-as-service」を使ってみました。
以下のような機能を持っています。
- 事前トレーニング済みの12/24レイヤーのBERTモデルを利用して構築(独自の学習済みモデルでも運用可能
- 少量のコードでテキストを固定長のベクトルとして取得が可能。
- 低遅延、高速処理に最適化されている
サーバ側(bert-as-service)
|
1 2 3 4 5 |
pip install bert-serving-client pip install bert-serving-server wget https://storage.googleapis.com/bert_models/2018_10_18/cased_L-12_H-768_A-12.zip unzip cased_L-12_H-768_A-12.zip bert-serving-start -model_dir cased_L-12_H-768_A-12/ -num_worker=1 -max_seq_len=300 |
クライアント側(bert-as-service)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
from bert_serving.client import BertClient from contextlib import contextmanager import pandas as pd import time import numpy as np @contextmanager def timer(title): t0 = time.time() yield print("{} - done in {:.0f}s".format(title, time.time() - t0)) df_train = pd.read_csv("./train.csv", skiprows=0, skipfooter=24710, engine="python",) # それぞれのデータのサイズを確認 print("The size of df is : "+str(df_train.shape)) # 表の一部分表示 display(df_train.head().append(df_train.tail())) with timer("do vector"): with BertClient() as bc: vecs = bc.encode(list(df_train["Summary"])) np.savetxt("news_vec.csv", vecs, delimiter=",") |
結果、1つの要約を768次元のベクトルに変換するのに、13分かかりました・・・。
fastText
「fastText」というFacebook AI Researchが2016年に開発した自然言語処理向けアルゴリズムがあります。
fastTextの利用方法は二つあり、「単語表現学習(Word representation learning)」と「文章分類(Text classification)」です。
教師データを作る・モデルを作る
教師データは、先頭に__label__(数字)で、あとは分かち書きされたテキスト列になっています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
import sys import csv import time import numpy as np import pandas as pd import fasttext as ft from contextlib import contextmanager @contextmanager def timer(title): t0 = time.time() yield print("{} - done in {:.0f}s".format(title, time.time() - t0)) # ファイル作成 def create_data(df, file): f = open(file, 'w', encoding='UTF-8') for x in df.values.tolist(): f.write(str(x) + "\n") f.close() # 10分の8の確率でテスト用ファイルにデータを書き込む def create_train_test_data(df, train_file, test_file): df_train = df.sample(frac=0.80) create_data(df_train, train_file) df_test = df.drop(df_train.index) create_data(df_test, test_file) # fasttextを学習させ、学習したfasttextの精度確認 def create_fasttext_model(train_file, test_file, model_file): model = ft.train_supervised(input=train_file, epoch=1000, loss="hs") model.save_model(model_file) results = model.test(test_file) print(results) # 目的変数の作成 def convert_target(df): for x in ("Completed", "Duplicated", "Already Fix"): df = df.str.replace(x, "1") for x in ("Rejected", "Not To Fix", "Non-MTK Fix", "Not reproducible"): df = df.str.replace(x, "0") df = df.fillna("0") return df # 目的変数の作成 def convert_summary(df): df = df.str.replace(r'<.+>_', "") # 日本語は不要 df = df.str.replace(r'[ぁ-んァ-ン一-龥]', "") return df if __name__ == '__main__': df_train = pd.read_csv("./train.csv", skiprows=0, skipfooter=0, engine="python") df_train = df_train.dropna(subset=["Component/s"]) df_train["target"] = convert_target(df_train["MTK_Resolution"]) df_train["Summary"] = convert_summary(df_train["Summary"]) #display(df_train["Summary"]) df = "__label__" + df_train["target"] + " , " + df_train['Summary'] train_file = "train.txt" test_file = "test.txt" with timer("create train test data"): create_train_test_data(df, train_file, test_file) with timer("create fasttext model"): create_fasttext_model(train_file, test_file, "fasttext.model") |
結果は次のとおりです。
|
1 2 3 |
create train test data - done in 0s (2277, 0.7672375933245499, 0.7672375933245499) create fasttext model - done in 51s |
fastTextは、テキストの分類にCBOW(Continuous Bag-of-Words )、skip-gramの2種類のアルゴリズムを使い、あるコーパスを入力とし、単語の分散表現(単語をベクトル化したもの)を取得します。
日本語処理の場合は、単語の切れ目が明確でないため、MeCab(めかぶ)などのオープンソースの形態素解析エンジンを利用して「分かち書き処理」が必要です。
word2vec
当時Googleに在籍していたTomas Mikolov(fastText開発者の一人)によって2013年に発表されました。
単語を意味ベクトルに埋め込み、そのベクトル同士の類似度(コサイン類似度)を計算することで類似語を抽出したり、単語の意味の足し算・引き算ができる
Word2Vec では、Skip-gram や CBOW といったタスクを学習させたニューラルネットワークの隠れ層の重みを使って単語を特徴ベクトルにエンコードする。
Kaggleコンペ上位の手法
「Toxic Comment Classification Challenge」というAlphabet 傘下の Jigsaw が主催する、荒らしコメントを分類するコンペティションがありました。
Wikipedia の編集議論板で書き込まれた約15万のコメントを1つずつ
- 荒らし( toxic )
- ひどい荒らし ( severe toxic )
- 卑猥( obscene )
- 脅迫( threat )
- 侮辱( insult )
- 個人攻撃( identity_hate )
であるか分類します。
[Tips1] 同じ単語は同じベクトルとして表現
英単語を学習済みワードベクトル (FastText, Glove 等)でタグ付けするときに、(大・小文字関係なく)“同じ単語は同じベクトルとして表現した方が良い性能が出る”と判断したようです。
しかし、英語で大文字を羅列するということは、その「文を強調している」という重要な情報が含まれています。
このため、この情報を特徴量として入れようと考え、次のようなルールを定めて大文字・小文字の変換処理を行いました。
- 単語に2文字以上大文字が含まれている場合は、大文字に変換する(例: TOXICやToXiC → TOXIC)
- 大文字が2文字未満の場合は、小文字に変換する(例: Toxicやtoxic → toxic)
[Tips2] 英語コメントを別の言語に翻訳して、さらに英語に再翻訳
前項の翻訳手法を考えているうちに、“英語コメントを別の言語に翻訳して、さらに英語に再翻訳 すればデータの水増しができるのでは?”と考えました。
という感じになります。文章が破綻せずに、元の文章とは異なる文を生成できる ことを上手く利用しよう、という発想です。
この再翻訳によるデータの水増しはとても有効な手法だったようです。
翻訳のソースコードは、 Translation API の pythonクライアントライブラリ を利用して作成しました。
エラー
ValueError: 1 is not in range
split関数を利用した際にpandasのdataframe上にsplitするべきアイテムが存在しない場合に発生
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import pandas as pd # こっちでは正しく動く #s_org = pd.Series(['aaa@', 'bbb@yyy.com', 'ccc@zzz.com', 'ddd'], # index=['A', 'B', 'C', 'D']) # こっちではエラー s_org = pd.Series(['aaa', 'bbb', 'ccc', 'ddd'], index=['A', 'B', 'C', 'D']) #print(s_org) tmp = s_org.str.split('@', expand=True) print(tmp) s_org = s_org.where((tmp[1].isnull() | (tmp[1] == "")), tmp[1]) s_org = s_org.where(~(tmp[1].isnull() | (tmp[1] == "")), tmp[0]) print(s_org) |
まとめ
強力なGPUが無くてもメモリさえ十分に積んでいるマシンがあれば自然言語処理の最先端に至れます。
が、メモリも少なければ非力なライブラリを使うしかありません。

