
僕は基本的に自分から何もしない。

考えてみれば、僕の人生はいつも「他人からのトリガー」で回ってきた。
だから定年退職後は、まじで糞して寝るだけのヒトデになると思ってる。
岩に張り付き、波に揺られるだけ。腕を伸ばす気力もなく、ただ海の音を聞く……そんな人生だと自覚してる。
いつも、こんなトリガーで行動が発生する。
RAGを使うとしてもOpenAIに金を払ったり、ハイスペックなマシンがいる……。
でも、待てよ?
「RAG(Retrieval-Augmented Generation(検索拡張生成))」とは、LLM(大規模言語モデル)が回答を生成する際に、外部のデータベースから関連情報を検索・取得してそれを元に回答を生成する技術。
実験にはGPUが必要だが無料で使う手段として「GoogleColab」がある。
CPU 2コア、RAM 12.7GB、GPU なし(たまにTesla T4)が無料。
約90分の無操作でセッションは切断されるし最大でも12時間の制限があるが十分だ。
日本語対応の無料モデル
どうせなら日本語LLMを使いたいよね。AIに聞いたら次のモデルを紹介された。
| モデル名 | サマリー | パラメータ数/サイズ | ライセンス (OSS) |
|---|---|---|---|
| japanese-gpt-neox-3.6b japanese-gpt-1b |
rinna社が開発した日本語特化のGPT-NeoXベースの事前学習言語モデル。テキスト生成や質問回答に適する | 3.6B (約7.2GB, FP16) 1B (約2GB, FP16) |
Apache 2.0 (OSS) MIT (OSS) |
| japanese-large-lm-3.6b japanese-large-lm-1.3b |
LINE Corporationが開発した日本語特化のGPT-NeoXベース。ウェブコーパスで訓練、テキスト生成向け | 3.6B (約7.2GB, FP16) 1.3B (約2.6GB, FP16) |
Apache 2.0 (OSS) Apache 2.0 (OSS) |
| open-calm-7b open-calm-3b open-calm-small |
CyberAgentが開発した日本語特化のデコーダオンリーモデル。日本語コーパスで事前訓練、テキスト生成や会話に適する | 7B (約14GB, FP16) 3B (約6GB, FP16) ~1B (約2GB, FP16) |
CC BY-SA 4.0 (OSS) CC BY-SA 4.0 (OSS) CC BY-SA 4.0 (OSS) |
| weblab-10b | 東京大学WebLabが開発した日本語特化のデコーダオンリーモデル。日本語ウェブデータで訓練 | 10B (約20GB, FP16) | Apache 2.0 (OSS) |
ただし、Google Colabでは rinnaのモデルがアクセス制限されて使えなかった。
If this is a private repository, make sure to pass a token having permission to this repo either by logging in with
hf auth login or by passing token=であれば、CyberAgentのモデルで実験してみるかー。
CyberAgentのモデルでローカルLLMを試してみる
RAGを実験するのが最終ゴールだが、結論からいうと想像以上に「LLMとしての精度」が低かった。だから、まずローカルLLMの実力を確認する。
手順は次の通り。
- Step 1. Google Colabを開く
- Step 2. pip installを実行
- Step 3. Google Driveをマウント
- Step 4. PDFファイルをアップロード(手動 or コード)
- Step 5. 実装コード(RAGクラス)をコピペ
- Step 6. 実力実験:簡単な質問をしてみる
- Step 7. RAG実験:フォルダを指定して実行
CyberAgentのモデルの実力実験
それぞれ「Google Colabで動作するか?」と「日本語応答できるか?」「どの程度時間がかかるか?」を検証してみる。
- open-calm-7b
- open-calm-3b
- open-calm-small
Step 1. Google Colabを開く
次にアクセス。

Step 2. pip installを実行
|
1 2 3 |
!pip install transformers accelerate sentencepiece !pip install sentence-transformers !pip install faiss-cpu |
Step 3. Google Driveをマウント
マウント済みも考慮してforce_remountで再同期する。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import os import shutil from google.colab import drive # /content/drive をクリア(Colabローカルに影響なし) if os.path.exists('/content/drive'): shutil.rmtree('/content/drive') print("クリア完了") # 強制マウント drive.mount('/content/drive', force_remount=True) # マウント確認 if os.path.exists('/content/drive/MyDrive'): print("Driveマウント成功!") else: print("マウント失敗。エラーを確認してください。") |
そして作業フォルダを作成。
|
1 2 |
import os os.makedirs('/content/drive/MyDrive/rag_documents', exist_ok=True) |
Step 4. PDFファイルをアップロード(手動 or コード)
Google Driveのマイドライブ以下に「rag_documents」というフォルダができている。
そのフォルダにPDFファイルをドラッグ&ドロップする。
Step 5. RAGクラスをコピペ
PDF読み込み用の追加インストールを行う。
|
1 |
!pip install pdfplumber # 高機能(表も読める) |
その上で次のコードをGoogle Colabに記載する。
最終的にはRAGを利用したいのでRAGクラスとして用意している。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 |
import torch from transformers import AutoTokenizer, AutoModelForCausalLM from sentence_transformers import SentenceTransformer import faiss import numpy as np import pdfplumber from pathlib import Path class SimpleRAG: def __init__(self): print("モデル読み込み中...") self.embedder = SentenceTransformer('intfloat/multilingual-e5-base') # 3GBモデル model_name = "cyberagent/open-calm-3b" self.tokenizer = AutoTokenizer.from_pretrained(model_name) self.model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype=torch.float16 # メモリ節約 ) if self.tokenizer.pad_token is None: self.tokenizer.pad_token = self.tokenizer.eos_token self.documents = [] self.index = None print("準備完了!") def load_pdfs_from_folder(self, folder_path): """PDFフォルダを読み込んで自動的にインデックス化""" folder = Path(folder_path) pdf_files = list(folder.glob('*.pdf')) if not pdf_files: print("PDFが見つかりません") return all_texts = [] for pdf_file in pdf_files: print(f"読み込み中: {pdf_file.name}") with pdfplumber.open(pdf_file) as pdf: for page in pdf.pages: text = page.extract_text() if text: # 500文字ごとに分割 chunks = [text[i:i+500] for i in range(0, len(text), 400)] all_texts.extend(chunks) # ベクトル化してインデックス作成 print(f"インデックス作成中... {len(all_texts)}チャンク") embeddings = self.embedder.encode(all_texts, show_progress_bar=True) self.documents = all_texts self.index = faiss.IndexFlatL2(embeddings.shape[1]) self.index.add(embeddings.astype('float32')) print("完了!") def ask(self, question): """質問に回答""" if not self.index: return "PDFを先に読み込んでください" # 検索 query_vec = self.embedder.encode([question]) distances, indices = self.index.search(query_vec.astype('float32'), 3) # コンテキスト作成 context = "\n".join([self.documents[idx] for idx in indices[0]]) # 回答生成 prompt = f"参考情報:\n{context}\n\n質問: {question}\n回答:" inputs = self.tokenizer(prompt, return_tensors="pt", truncation=True, max_length=1500) outputs = self.model.generate(**inputs, max_new_tokens=200, temperature=0.7) answer = self.tokenizer.decode(outputs[0], skip_special_tokens=True) return answer.split("回答:")[-1].strip() |
モデルを変更する場合には次のコードを変更する。
|
1 2 |
# 3GBモデル model_name = "cyberagent/open-calm-3b" |
日本語で質問してみる
RAG用に実装してるので、呼び出し方がちょっと特殊になった。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
rag = SimpleRAG() def test_chat(text): """RAGのモデルを使って単純な会話テスト""" inputs = rag.tokenizer(text, return_tensors="pt", truncation=True, max_length=500) # pad_token_idの設定 if rag.tokenizer.pad_token_id is None: rag.tokenizer.pad_token_id = rag.tokenizer.eos_token_id outputs = rag.model.generate( **inputs, max_new_tokens=100, temperature=0.7, do_sample=True, pad_token_id=rag.tokenizer.pad_token_id ) response = rag.tokenizer.decode(outputs[0], skip_special_tokens=True) return response # いろんなパターンでテスト test_cases = [ "おはようございます。今日は", "質問: 2+3の答えは?\n回答:", "犬と猫、どちらが好きですか?", "明日の予定を教えてください。", "富士山の高さは何メートルですか?" ] for test in test_cases: print(f"入力: {test}") print(f"出力: {test_chat(test)}") print("-" * 50) |
実行すると勢いよく開始される。
で、20分~30分待つ。
入力: おはようございます。今日は
出力: おはようございます。今日は一日、雨模様の京都です。
さて、本日、京都新聞に京都の文化財保全に関する記事が掲載されています。
京都新聞記事
京都では、昨年、清水寺周辺から世界遺産清水寺へのルート上にあった、清水寺と通じる道を通行止めにしたことで、清水寺への観光客の減少や、清水寺周辺の道路の渋滞による観光への障害となっていました。
そこで、京都では、京都景観まちづくりネットワーク会議という団体を作り、京都の景観保全に関する様々な取り組みを行ってい
————————————————–
入力: 質問: 2+3の答えは?
回答:
出力: 質問: 2+3の答えは?
回答: 4+2
これは、数学における2次関数のグラフです。
2次関数のグラフは、2つの点を直線でつなぐとき、原点を中心とした円になります。
好き勝手喋ってるだけwww
相手の英語が分からず、適当に返答してる僕だわwww
因みに「open-calm-7b」は20分経過後に次のようにメモリ不足でディスクにオフロードしようとして失敗する。
device_map had weights offloaded to the disk. Please provide an offload_folder for them. Alternatively, make sure you have safetensors installed if the model you are using offers the weights in this format.
「open-calm-small」は動作するし早いけど、返答はこうなる。
出力: おはようございます。今日は、いよいよ、全国一斉「水かけ祭り」ですね。今年は、9月1日。2日。3日。5日の三日間。
水かけ祭りとは、毎年10月1日、2日。3日。4日。5日。5日間。
今年は、どんな楽しいお祭りになるのでしょうね。
(水かけ祭りの日程や時間は、毎年変わります。)
水かけ祭りとは、この3日間のお祭りです。
毎年、10月1日
————————————————–
入力: 質問: 2+3の答えは?
回答:
出力: 質問: 2+3の答えは?
回答: 1+3の答えは?
質問: 1+3の答えは?
「子どもを虐待から守るための法律」
「子ども虐待防止法」
「虐待防止法」
「虐待防止法」
「虐待防止法」
「虐待防止法」
もう相手の質問が何なのかすら分かってない。
実践的なRAG実装(大量文書対応版)
RAGを使うにはGoogle Driveの「rag_documents」フォルダに大量にPDFを置く。
ネット検索では見つからない資料が思いつかず、御三家男子中学校の入試過去問を17個 置いてみた。
そして次のコマンドを入力してみる。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# SimpleRAG初期化 rag = SimpleRAG() # フォルダとPDF確認 folder_path = '/content/drive/MyDrive/rag_documents' pdf_files = [f for f in os.listdir(folder_path) if f.lower().endswith('.pdf')] if not pdf_files: print("エラー: PDFが見つかりません。フォルダを再確認してください。") else: print(f"発見したPDF: {pdf_files}") rag.load_pdfs_from_folder(folder_path) print("読み込み成功!") # 質問実行 answer = rag.ask("つるかめ算を使った問題はどの中学校の何年入試に出題されているか?具体的な問題内容も教えて") print("回答:", answer) |
実行すると3時間経過しても、まだ考え中。
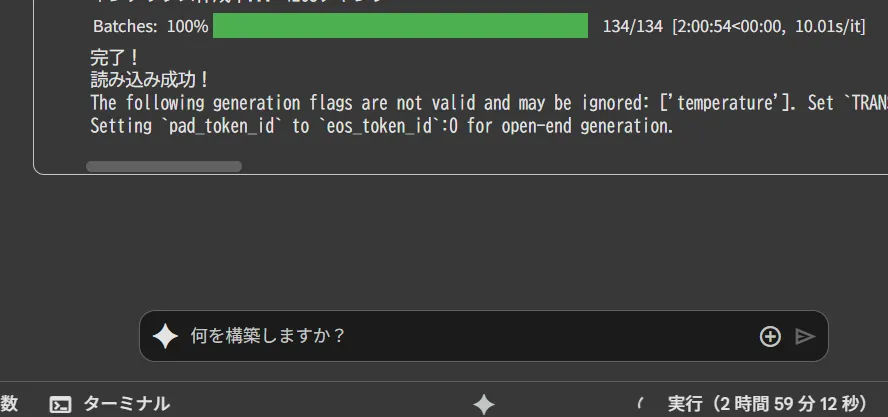
3時間40分経過
ついに結果が!
Batches: 100%
134/134 [2:00:54<00:00, 10.01s/it] 完了! 読み込み成功! The following generation flags are not valid and may be ignored: ['temperature']. Set
TRANSFORMERS_VERBOSITY=info for more details.Setting
pad_token_id to eos_token_id:0 for open-end generation.回答: ど
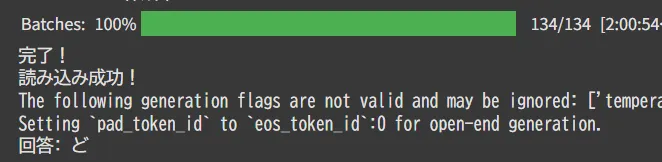

ここにまた、一つのゴミが誕生した……。
おわりに
この実験で3連休を潰した。後から分かったこと。
- Google Colab無料枠で GPU を有効にしてなかったので長時間かかった。
- AIが最新情報を把握しておらず、提案されたモデルが 2023年情報のため精度が悪かった。
当初の目的は達成したということで今回は終了とするが、リベンジしたい。

