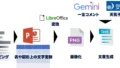
AI技術の発達が凄まじく、昔やりたかった事が色々と実現できるようになってきた。
今回実験するステップは次のとおり。
- ① 背面にあってもChrome画面を自動的にキャプチャする
- ② キャプチャ画像にOCRを実施して日本語を抽出
- ③ 抽出した日本語をLLMに渡す
- ④ LLMからのフィードバックを得る
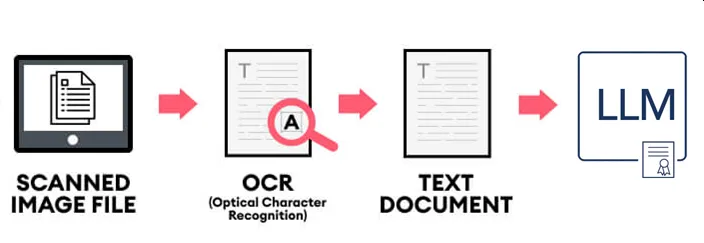
これが1ページ10秒~30秒もかからないスピードで実施できれば、多くの事ができるようになる。
- YouTubeなどの動画の文字抽出してコメントや要約出力
- 購入株画面キャプチャ画像から銘柄を抽出してシミュレーション
- デジタル書籍画像からの自動文字抽出
- オンライン試験・アンケート等の自動回答
- 社内のデジタル業務自動化
- その他、社内ハッカソンのデモ機作成
LLMは要約したり、OCRが誤っている部分を修正したり、問題を回答する目的で使っている。
最近は既に画像をアップロードするだけでChatGPTは返答できてしまうので、OCRを実施する行為自体が無駄な気もする。
ゼロから調査すると超面倒くさいけど、ChatGPTがコードはサクッと作ってくれるのでアイデア次第で何でもできる。
各種OCRの日本語抽出 精度確認
既に多くのサイトを徘徊し「Google Vision API」「Azure AI Vision」が使いやすいとの事前調査は済んでいる。
| サービス名 | 内容 | 備考欄 |
|---|---|---|
| Tesseract-ocr | OSSで利用 | |
| PaddleOCR | OSSで利用 | |
| Amazon Textract | Amazon提供、日本語非対応 | 無料枠 1,000 ページ/月 |
| Azure AI Vision | Microsoft 提供 | 無料枠 5,000 無料トランザクション/月 |
| Google Cloud Vision API | Google 提供 | 無料枠 1,000 ユニット(画像)/月 |
実用に向けて「Tesseract-ocr」と「Google Cloud Vision API」使った日本語抽出を実装した。
精度が悪いと知ってる「Tesseract-ocr」を選んだ理由はGoogle Cloudは金がかかるのでプロト実装の間はTesseract-ocrで代行するため(無料OCRではそこそこ性能は高い)だ。
実験に使う画像はオンラインSPI試験の例題。

これをOCRにかけてLLMが正しく回答できるならオンライン試験や就職活動までやり方を変える必要がありそうだ。
Tesseract-ocr
次のページにアクセスしてWindows用のインストーラーをダウンロード&インストール。

その際にインストールオプションで次の項目から「Japanese ~」を選択しておくこと。
- Additional script data (download
- Additional language data (download)

あとはWindows環境変数でPATHを設定する。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
from PIL import Image import pytesseract import sys # 画像ファイルのパスをコマンドライン引数として受け取る image_path = sys.argv[1] # 画像を開く img = Image.open(image_path) # OCRを実行して日本語を抽出 text = pytesseract.image_to_string(img, lang='jpn') # 抽出したテキストを出力 print(text) |
【実行結果(実行時間 1秒未満)】
例題(構造把握
Q:次のアンオは、ある美術館の意見箱に入っていた要望で
ある。 これらを要望の種類によってAグループ (3つ) と
Bグループ (2つ) に分けることができる。 Bグループに分類
されるものを下の選択肢の中から選びなさい。美大生の割引特典などとつけてほしい。
休憩スペースがあるといい。出口にゴミ箱を設置してほしい。
OOの展示スペースをもっと広くしたほうがいい。
入場制限時間を延ばしてほしい。ロロへ
A アとイ F イとエ
B アとウ G イとオ
C アとエ H ウとエ
D アとオ 1 ウとオ
E _イとウ J エとオ
なかなか精度が高い。でも肝心の選択肢の冒頭のカタカナが消えてしまっている。
Google Cloud Vision API
新規契約をすると「90 日間 $300 相当の無料トライアル」が付いてきた。
月1000回を超えなければ無問題だと思われるので、とりあえず料金は無視する。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
import requests import base64 import json import sys GOOGLE_CLOUD_VISION_API_URL = 'https://vision.googleapis.com/v1/images:annotate?key=' API_KEY = '取得したAPIキーを入力' # APIを呼び、認識結果をjson型で返す def request_cloud_vison_api(image_base64): api_url = GOOGLE_CLOUD_VISION_API_URL + API_KEY req_body = json.dumps({ 'requests': [{ 'image': { 'content': image_base64.decode('utf-8') # jsonに変換するためにstring型に変換する }, 'features': [{ 'type': 'TEXT_DETECTION', # ここを変更することで分析内容を変更できる 'maxResults': 10, }] }] }) res = requests.post(api_url, data=req_body) return res.json() # 画像読み込み def img_to_base64(filepath): with open(filepath, 'rb') as img: img_byte = img.read() return base64.b64encode(img_byte) # 文字認識させたい画像 image_path = sys.argv[1] img_base64 = img_to_base64(image_path) result = request_cloud_vison_api(img_base64) #認識した文字の位置など、すべての情報を出力 #print("{}".format(json.dumps(result, indent=4))) #認識した文字のみを出力 text_r = result["responses"][0]["fullTextAnnotation"]["text"] print(text_r) |
【実行結果(実行時間 1秒未満)】
例題(構造把握 : 言語)
Q:次のア~オは、 ある美術館の意見箱に入っていた要望で
ある。 これらを要望の種類によってAグループ (3つ) と
Bグループ (2つ) に分けることができる。 Bグループに分類
されるものを下の選択肢の中から選びなさい。
ア 美大生の割引特典などとつけてほしい。
イ休憩スペースがあるといい。
ウ 出口にゴミ箱を設置してほしい。
エオ
○○の展示スペースをもっと広くしたほうがいい。
才入場制限時間を延ばしてほしい。
A アとイ
B アとウ
C アとエ
F イとエ
G イとオ
H9
ウとエ
D アとオ
E イとウ
| ウとオ
Jエとオ
非常に精度が高い。選択肢の「H」が失敗しているが、LLMで理解できるレベルと思う。
背面にあるChromeブラウザの画像取得方法
OCRが動作することが分かったが、Chromeブラウザから画像取得しなければ話は始まらない。
Chromeブラウザがスクリーンの後ろに存在していても、Chromeのプロセス番号を指定して画面キャプチャするスクリプトがこれ。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
import win32gui import win32ui import win32con import win32api import time def capture_window_process(process_name, output_filename): # Find the window by process name hwnd = win32gui.FindWindow(None, process_name) if hwnd == 0: print(f"Window with process name '{process_name}' not found.") return # Get window dimensions left, top, right, bottom = win32gui.GetClientRect(hwnd) width = right - left height = bottom - top # Adjust for window border and title bar to get client area size border_width = win32api.GetSystemMetrics(win32con.SM_CXSIZEFRAME) titlebar_height = win32api.GetSystemMetrics(win32con.SM_CYCAPTION) width += 2 * border_width height += border_width + titlebar_height # Create a device context (DC) for capturing hwndDC = win32gui.GetWindowDC(hwnd) mfcDC = win32ui.CreateDCFromHandle(hwndDC) saveDC = mfcDC.CreateCompatibleDC() # Create a bitmap object saveBitMap = win32ui.CreateBitmap() saveBitMap.CreateCompatibleBitmap(mfcDC, width, height) # Select the bitmap into the DC saveDC.SelectObject(saveBitMap) # Copy the screen into our bitmap result = win32gui.PrintWindow(hwnd, saveDC.GetSafeHdc(), 0) if not result: print("Failed to capture window.") return # Save the bitmap to a file saveBitMap.SaveBitmapFile(saveDC, output_filename) # Clean up win32gui.DeleteObject(saveBitMap.GetHandle()) saveDC.DeleteDC() mfcDC.DeleteDC() win32gui.ReleaseDC(hwnd, hwndDC) if __name__ == "__main__": process_name = "YourProcessNameHere" output_filename = "screenshot.png" capture_window_process(process_name, output_filename) print(f"Screenshot saved to {output_filename}") |
おわりに
AI技術の進歩は凄まじい。
ChatGPTで画像認識から含めて何でもできてしまう。
ネットで同じような事を考えている人がいたけど、そもそもスマホで画面をキャプチャしてChatGPTに画像を送ってた。
確かに、そのレベルで同じことが出来てしまうね。