過去の「Featured」として、まずはタイタニック同様の「分類」コンテストで有名な次の問題を解いてみます。

このコンペは与えられた個人のクレジットの情報や以前の応募情報などから、各データが債務不履行になるかどうかを予測する問題です。
[参考] 過去の機械学習関係の記事
Kaggleで勝つには次の書籍がおすすめです。

この書籍によると、分析コンペで銅メダルに入賞するためには、Kernel(Notebooks)をしっかりとおいかけて基本フローをしっかりと押さえていくことで取れることがあるらしいです。
※ 2019年8月からKernelはNotebooksと名称が変わりましたが、多くのサイトや書籍では引き続きKernelと呼ばれています。
前回の記事でサブミットを行い、現在「スコア 0.70639(順位6119/7175 = Top 85%)」です。
Kernel(Notebooks)って何?
Kaggleには各コンペごとにフォーラムがあり、コンペ参加者がコードを公開する場(Kernel)、議論する場(Discussion)があります。
Kernelはクラウド上で計算や可視化のコードを実行できる環境です。
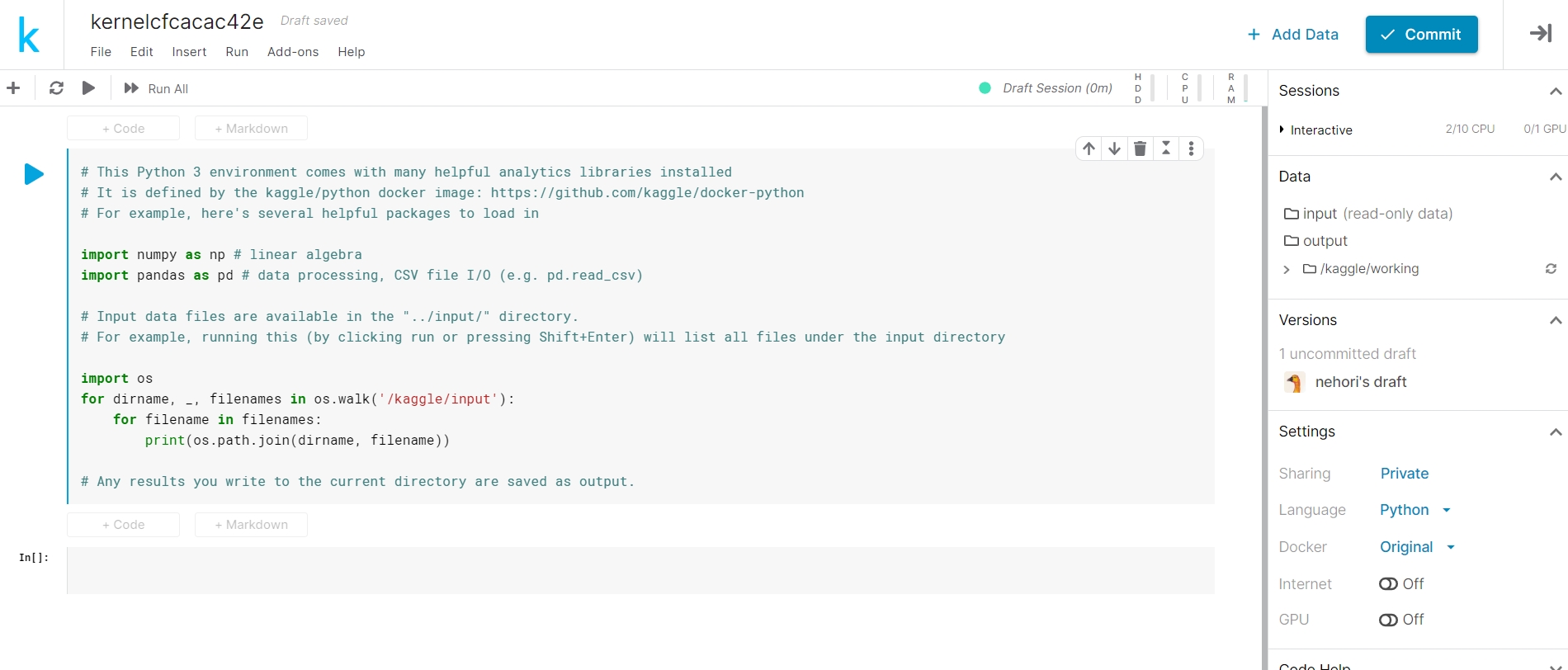
Kernelは分析のコードを共有場所にもなっており、公開されたものは他の人も見ることができます。
Kaggleにおいてはコンペに関する知見をプライベートにチーム外に共有することが禁止されており、コンペ参加者が平等にその知見に触れられるように、知見を共有しなければならないルールがあります。
そのため、参加しているコンペに関して、他の参加者が公開した知見を知りたい場合には、基本的にKernelおよびDiscussionを見ておけばよいようです。
なお、Kernelには、計算時間やメモリに制限があります。
- 9時間の実行時間
- 20GBのディスク容量
- 16GBの一時的なディスク容量
特に容量は気をつける必要があります。
20GB max private datasets (if you exceed this, either make your datasets public or delete unused datasets)
[引用] https://www.kaggle.com/docs/datasets#technical-specifications
どのKernelを見ていくか?
Voteの順序に並べてみました。
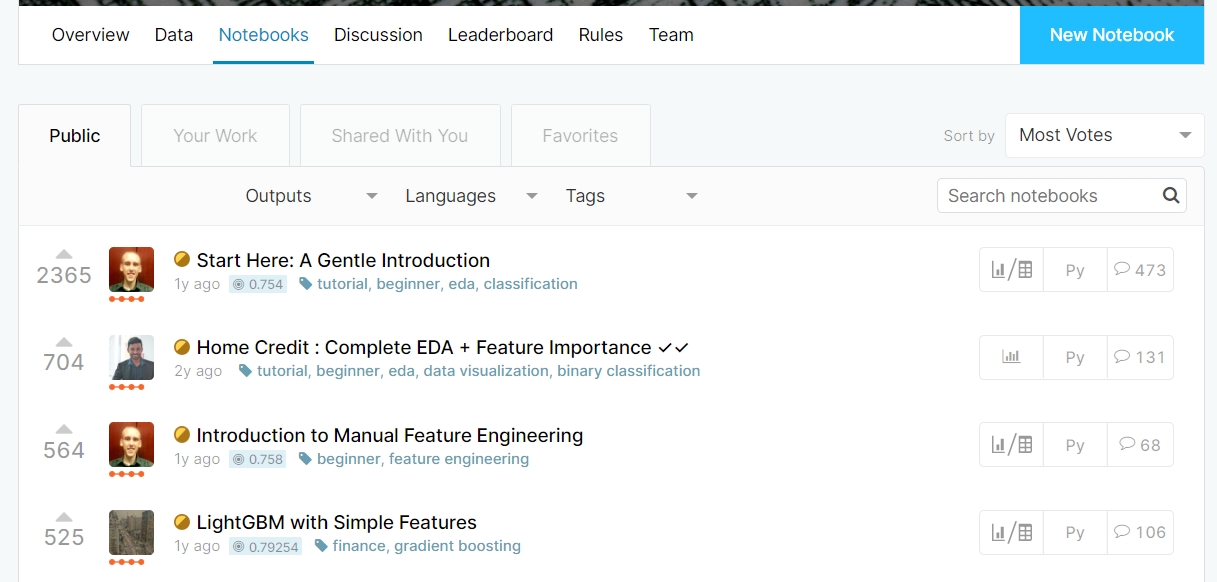
最初の3つはイントロダクションやEDAに関する記載ですが「LightGBM with Simple Features」は明らかに戦略が記載されてそうなタイトルです。

ページを開いてみると「スコア 0.79070」と書いてあります。
多くの参加者のスコアが「0.8~0.79の間」だという事を考えると、明らかにこちらのKernelを参照しており、これをベースにスクリプトを改造しているようです。
[引用] <実践>はじめてのKaggle体験記
私の場合は、写経するだけでスコアが一気にアップします。
ちなみに、各レベルに対するスコアとランキングを一つ一つ確認しながら並べてみました。
| レベル | スコア | ランキング |
|---|---|---|
| 賞金獲得 | 0.80511 | 3/7175 (上位 3名) |
| 金メダル | 0.80110 | 24/7175 (top 0.3%) |
| 銀メダル | 0.79602 | 359/7175 (top 5%) |
| 銅メダル | 0.79449 | 719/7175 (top 10%) |
| サンプル | 0.79070 | 2870/7175 (top 40%) |
このコンペは「0.001」の世界を争っていたようです。
「LightGBM with Simple Features」は何をやっているのか?
358行という長さの中で、一体何をしているのでしょうか?Pythonの書き方もよく分かってないので他人のコードは勉強になります。
実行時間を計測する
Kaggleで実行時間に制限のあるコンペがあるので、withとcontextmanagerで実行時間を計測しているようです。
|
1 2 3 4 5 6 7 8 |
@contextmanager def timer(title): t0 = time.time() yield print("{} - done in {:.0f}s".format(title, time.time() - t0)) with timer('説明'): (処理) |
コンテキストマネージャ(context manager) とは、 with 文の実行時にランタイムコンテキストを定義するオブジェクトです。
今までTime関数呼んで差分を求めて時間を測定していましたしたが、Kaggleではこちらが一般的とのことです。
各種CSVを読み込む
このコンペは複数のCSVが用意されていました。
|
1 2 3 4 5 6 7 8 9 10 |
df = application_train_test(num_rows) with timer("Process bureau and bureau_balance"): bureau = bureau_and_balance(num_rows) print("Bureau df shape:", bureau.shape) df = df.join(bureau, how='left', on='SK_ID_CURR') with timer("Process previous_applications"): prev = previous_applications(num_rows) print("Previous applications df shape:", prev.shape) df = df.join(prev, how='left', on='SK_ID_CURR') ...(省略) |
それらを一つ一つ読み込み、前処理を行い結合しています。
前処理は何をしているか?
グルーピングし統計量を算出する
このコンペでは、複数のデータが提供されています。
複数のデータは「SK_ID_CURR」というキーを使って、接続されています。
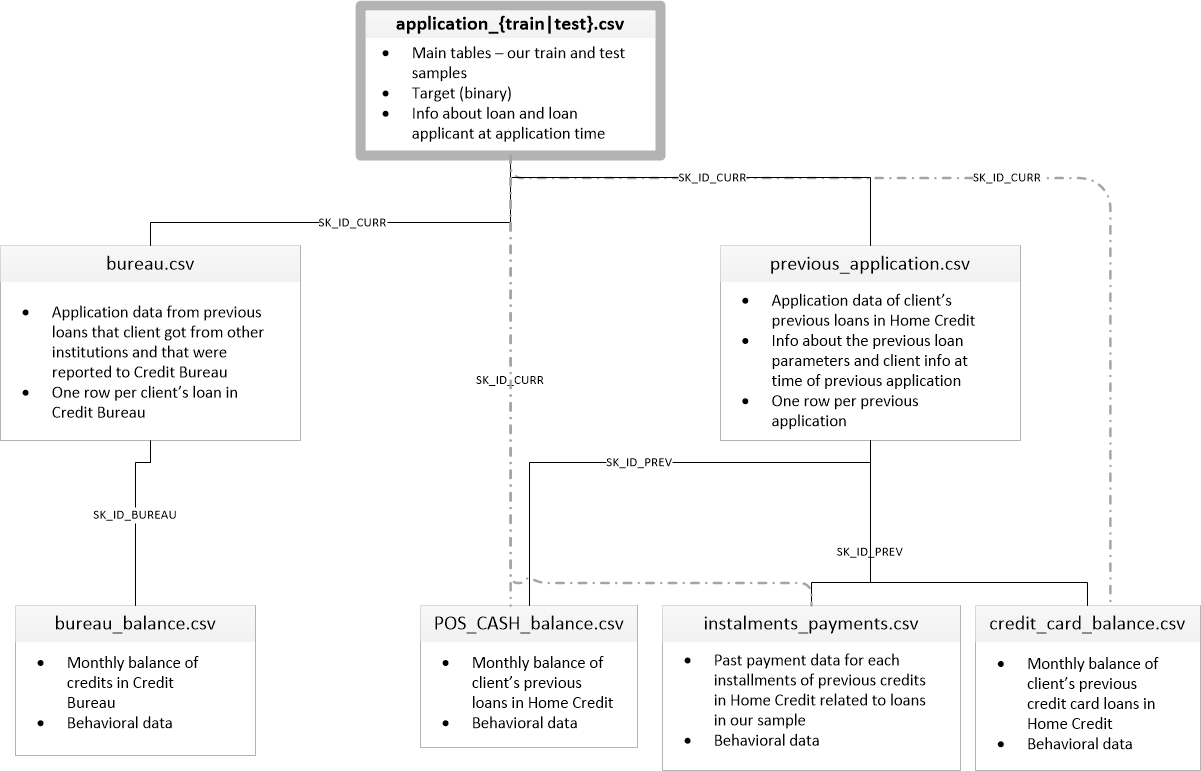
各データを合わせて一つの表を作ろうとしています。
また、重複するIDのカラムは集計して計算処理を行ったあとに合成しているようです。
サンプルを使って説明します。次のようなテーブルが存在するとします。
|
1 2 3 4 5 6 |
import pandas as pd import numpy as np df = pd.DataFrame({'A': [1, 1, 2, 2, 3, 3, 4, 5, 5, 5], 'B': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], 'C': np.random.randn(10)}) df |

これに対して、AのIDをユニークにして残りのデータを min、 max、 sum で集計して出力してみます。
Pandasのデータをさまざまなかたちで集計する関数.agg()を使います。
|
1 |
df.groupby('A').agg(['min', 'max', 'sum']) |
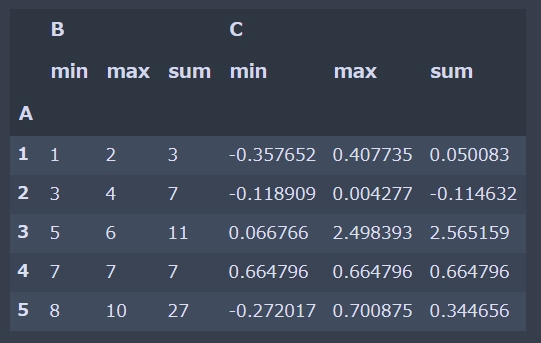
これと同じ処理を行っている部分が次のコードです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
pos = pd.read_csv('./POS_CASH_balance.csv', nrows = num_rows) pos, cat_cols = one_hot_encoder(pos, nan_as_category= True) # Features aggregations = { 'MONTHS_BALANCE': ['max', 'mean', 'size'], 'SK_DPD': ['max', 'mean'], 'SK_DPD_DEF': ['max', 'mean'] } for cat in cat_cols: aggregations[cat] = ['mean'] pos_agg = pos.groupby('SK_ID_CURR').agg(aggregations) pos_agg.columns = pd.Index(['POS_' + e[0] + "_" + e[1].upper() for e in pos_agg.columns.tolist()]) |
ほとんどの機械学習アルゴリズムを使うとき、特徴量の数は固定でないといけません。
ユーザー1は購買履歴が3行、ユーザー2は購買履歴が10行・・・のように、各ユーザーごとにデータの特徴量が違うと都合が悪いので、集計を全部の数値項目に対して行っています。
新しく特徴量を生成する
元の特徴量をもとに新しく特徴量を生成しているようです。
|
1 2 3 4 5 6 |
# Some simple new features (percentages) df['DAYS_EMPLOYED_PERC'] = df['DAYS_EMPLOYED'] / df['DAYS_BIRTH'] df['INCOME_CREDIT_PERC'] = df['AMT_INCOME_TOTAL'] / df['AMT_CREDIT'] df['INCOME_PER_PERSON'] = df['AMT_INCOME_TOTAL'] / df['CNT_FAM_MEMBERS'] df['ANNUITY_INCOME_PERC'] = df['AMT_ANNUITY'] / df['AMT_INCOME_TOTAL'] df['PAYMENT_RATE'] = df['AMT_ANNUITY'] / df['AMT_CREDIT'] |
このような特徴量を作成するには、その業界特有の知識(=ドメイン知識)が必要です。
なので、これはそのまま拝借します。
カテゴリカル変数を数値に変える
|
1 2 3 |
# Categorical features with Binary encode (0 or 1; two categories) for bin_feature in ['CODE_GENDER', 'FLAG_OWN_CAR', 'FLAG_OWN_REALTY']: df[bin_feature], uniques = pd.factorize(df[bin_feature]) |
「pd.factorize」を利用すると、カテゴリ変数をユニークな数値に変換してくれます。
引数にはシーケンス(list、Series)を渡します。
すると、カテゴリ変数を数値に変換したndarrayが返ってくるのでそれを元のデータフレームに戻します。
「uniques」にはユニークなラベルが入っています。
これをget_indexerを使うことで別のデータフレームのカテゴリ変数を同じ数値で変換することができます。
カテゴリデータを one-hot 表現に変換する
「pd.factorize」を利用すると、例えば「A 型から O 型への距離は A 型から B 型への距離の 3 倍である」というような関係だと勘違いすることがあります。、
このため、カテゴリ変数(カテゴリカルデータ、質的データ)をダミー変数(one-hot 表現)に変換するために「get_dummies」も利用されています。
|
1 2 3 4 5 6 7 8 9 10 |
# One-hot encoding for categorical columns with get_dummies def one_hot_encoder(df, nan_as_category = True): original_columns = list(df.columns) categorical_columns = [col for col in df.columns if df[col].dtype == 'object'] df = pd.get_dummies(df, columns= categorical_columns, dummy_na= nan_as_category) new_columns = [c for c in df.columns if c not in original_columns] return df, new_columns # Categorical features with One-Hot encode df, cat_cols = one_hot_encoder(df, nan_as_category) |
学習モデル構築では何をしているか?
K-分割交差検証 (k-fold cross-validation)を利用する
「# LightGBM GBDT with KFold or Stratified KFold」と書いてあります。
|
1 2 3 4 5 |
# Cross validation model if stratified: folds = StratifiedKFold(n_splits= num_folds, shuffle=True, random_state=1001) else: folds = KFold(n_splits= num_folds, shuffle=True, random_state=1001) |
今まで何度か「trai_test_split」関数で訓練セットとテストセットを分割する処理をしてきました。
「train_test_split」関数はデータをランダムに分割するので、クラス分類が難しいデータが訓練データに入り、簡単なデータがテストデータに入った場合評価精度はとても高くなってしまいます。
交差検証(Cross validation)はより正確な評価精度を得るために利用されます。
このサンプルでは、2つの交差検証手法である「k分割交差検証(k-fold cross-validation)」と「層化k分割交差検証(stratified-fold cross-validation)」を切り替えるような実装となっています。
- 【メリット】train_test_split関数を活用した場合に比べて、汎化性のある評価精度を得ることができる
- 【デメリット】分割したk個のモデルを訓練するため、単純な分割よりも計算コストがかかる
ちなみに「k分割交差検証」と「層化k分割交差検証」の活用用途は以下の通りです。
- k分割交差検証(KFold):予測問題
- 層化k分割交差検証(StratifiedKFold):分類問題
ベイズ最適化によるハイパーパラメータ探索をする
LightGBMのパラメータが細かく指定されており、コメントに「Bayesian optimization」で発見したパラメータと書いてあります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# LightGBM parameters found by Bayesian optimization clf = LGBMClassifier( nthread=4, n_estimators=10000, learning_rate=0.02, num_leaves=34, colsample_bytree=0.9497036, subsample=0.8715623, max_depth=8, reg_alpha=0.041545473, reg_lambda=0.0735294, min_split_gain=0.0222415, min_child_weight=39.3259775, silent=-1, verbose=-1, ) |
従来、ハイパーパラメータの探索は、grid searchなどで行うことが常套手段でしたが、時間がかかりすぎるという問題がありました。
そこで、もう少し効率良くベストなハイパーパラメータを探索する方法として「ベイズで最適化する手法」が提案されています。
KaggleのKernelでは、「parameters found by Bayesian optimization」というフレーズがよく出てくるそうなので、覚えておいて損はありません。
また今度、自分でも実装してみます。
AUC (Area Under the ROC Curve)で指標の評価
今までは、機械学習の分類問題などの評価指標として混同行列 (Confusion matrix)を使っていました。
このサンプルでは「ROC-AUC」が使われています。
ただ、正例が極端に少ないデータだと、混同行列では正しく判定できないことがあります。
AUCとは、ROC曲線が描いた線を元に計算される評価指標です。
ROC曲線とは、スコアが「0.999999」以上のみを陽性と見なすようなという厳しい条件においても、陽性を正しく分類できます。
・・・・こちらもよく分かりません。
Scikit-learnでAUCを計算するには、roc_auc_score()に、正解ラベルと予測スコアを渡すとAUCを計算してくれます。
|
1 2 |
feature_importance_df = pd.concat([feature_importance_df, fold_importance_df], axis=0) print('Fold %2d AUC : %.6f' % (n_fold + 1, roc_auc_score(valid_y, oof_preds[valid_idx]))) |
必要箇所をコピーして実行してみる
LightGBMで実行エラー
LightGBMで実行エラーが発生しました。
|
1 |
LightGBMError: Do not support special JSON characters in feature name. |
理由は分かりませんがググって次のように修正しました。
|
1 |
df.columns = ["".join (c if c.isalnum() else "_" for c in str(x)) for x in df.columns] |
その結果、実行できました。
CatBoostで実行エラー&実行
CatBoostはErrorが発生しました。因みに、LightGBMではErrorは発生しません。
|
1 2 |
CatBoostError: c:/goagent/pipelines/buildmaster/catboost.git/catboost/libs/data/model_dataset_compatibility.cpp:236: Feature FONDKAPREMONT_MODE_not specified from pool must be FONDKAPREMONT_MODE_not_specified. |
“FONDKAPREMONT_MODE_not specified” という文字列を”FONDKAPREMONT_MODE_not_specified”にしろというエラーです。
分かっているなら、自動的に変換してくれたらよいのに・・・。
修正すると、次から次へとエラーが表示されました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
CatBoostError: c:/goagent/pipelines/buildmaster/catboost.git/catboost/libs/data/model_dataset_compatibility.cpp:236: Feature NAME_EDUCATION_TYPE_Secondary_/_secondary_special from pool must be NAME_EDUCATION_TYPE_Secondary___secondary_special. CatBoostError: c:/goagent/pipelines/buildmaster/catboost.git/catboost/libs/data/model_dataset_compatibility.cpp:236: Feature NAME_HOUSING_TYPE_Co-op_apartment from pool must be NAME_HOUSING_TYPE_Co_op_apartment. CatBoostError: c:/goagent/pipelines/buildmaster/catboost.git/catboost/libs/data/model_dataset_compatibility.cpp:236: Feature NAME_TYPE_SUITE_Spouse,_partner from pool must be NAME_TYPE_SUITE_Spouse__partner. CatBoostError: c:/goagent/pipelines/buildmaster/catboost.git/catboost/libs/data/model_dataset_compatibility.cpp:236: Feature ORGANIZATION_TYPE_Industry:_type_1 from pool must be ORGANIZATION_TYPE_Industry__type_1. CatBoostError: c:/goagent/pipelines/buildmaster/catboost.git/catboost/libs/data/model_dataset_compatibility.cpp:236: Feature PREV_CHANNEL_TYPE_AP+_(Cash_loan)_MEAN from pool must be PREV_CHANNEL_TYPE_AP___Cash_loan__MEAN. |
変換は次のようにやります。
|
1 2 3 4 5 6 |
data = {'a,b': [9, 2, 8], 'a-c':[3, 4, 2], 'cc c':[4, 6, 1]} df = pd.DataFrame(data=data) df.columns = df.columns.str.replace(' |,|\/|-|\+|:|\(|\)|<|>', '_') df |
サブミットする
丸写しを避けるために、せめてもの意地で自分なりに幾つかやってみました。
- [Step1] LightGBM(前処理+ベイズ最適化)
- [Step2] CatBoost(前処理)
- [Step3] CatBoost(前処理+AUCで評価で評価&K-分割交差検証)
- [Step4] LightGBM(サンプル丸写し)
LightGBM(前処理+ベイズ最適化)で解いた結果
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
Train samples: 307511, test samples: 48744 Bureau df shape: (305811, 116) Process bureau and bureau_balance - done in 69s Previous applications df shape: (338857, 249) Process previous_applications - done in 90s Pos-cash balance df shape: (337252, 18) Process POS-CASH balance - done in 35s Installments payments df shape: (339587, 26) Process installments payments - done in 75s Credit card balance df shape: (103558, 141) Process credit card balance - done in 51s Run LightGBM with kfold - done in 0s The size of train is : (307507, 798) The size of test is : (48744, 797) X_train:(246005, 797) y_train:(246005,) X_valid:(61502, 797) y_valid:(61502,) LGBMClassifier Accuracy: 0.9654112721286152 Time = 3860.4211678504944 Total Time = 3860.4211678504944 LGBMClassifier was selected [[56223 323] [ 4654 302]] Model[LGBMClassifier] Testing Accuracy = "0.9190758024129296 !" LGBMClassifier was selected [[0.98310704 0.01689296] [0.89219864 0.10780136] [0.98928867 0.01071133] ... [0.9972012 0.0027988 ] [0.98476691 0.01523309] [0.79972031 0.20027969]] Finished. |
計算時間は約1時間です。
サブミットして得られたスコアは「0.77812」です。

順位は想定で4088/7175(top 57%)です。
CatBoost(前処理)で解いた結果
実行結果が得られました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
Train samples: 307511, test samples: 48744 Bureau df shape: (305811, 116) Process bureau and bureau_balance - done in 50s Previous applications df shape: (338857, 249) Process previous_applications - done in 68s Pos-cash balance df shape: (337252, 18) Process POS-CASH balance - done in 25s Installments payments df shape: (339587, 26) Process installments payments - done in 54s Credit card balance df shape: (103558, 141) Process credit card balance - done in 37s Run LightGBM with kfold - done in 0s The size of train is : (307507, 798) The size of test is : (48744, 797) X_train:(246005, 797) y_train:(246005,) X_valid:(61502, 797) y_valid:(61502,) CatBoostClassifier Accuracy: 0.0 Time = 418.5196192264557 Total Time = 418.5196192264557 CatBoostClassifier was selected [[56382 218] [ 4663 239]] Model[CatBoostClassifier] Testing Accuracy = "0.9206367272609021 !" CatBoostClassifier was selected [[0.92918278 0.07081722] [0.81582529 0.18417471] [0.97678134 0.02321866] ... [0.99281461 0.00718539] [0.96131774 0.03868226] [0.77844219 0.22155781]] Finished. |
実行時間は7分程度です。
サブミットして得られたスコアは「0.78639」です。
順位は想定で3559/7175(Top 50%)です。
CatBoost(前処理+AUCで評価で評価&K-分割交差検証)で解いた結果
よく分からないまま、次のように差し替えました。
|
1 2 3 4 5 6 7 8 9 10 11 |
for n_fold, (train_idx, valid_idx) in enumerate(folds.split(train_df[feats], train_df['TARGET'])): train_x, train_y = train_df[feats].iloc[train_idx], train_df['TARGET'].iloc[train_idx] valid_x, valid_y = train_df[feats].iloc[valid_idx], train_df['TARGET'].iloc[valid_idx] clf = CatBoostClassifier(logging_level='Silent') clf.fit(train_x, train_y, eval_set=[(train_x, train_y), (valid_x, valid_y)], verbose= 200, early_stopping_rounds= 200) oof_preds[valid_idx] = clf.predict_proba(valid_x)[:, 1] sub_preds += clf.predict_proba(test_df[feats])[:, 1] / folds.n_splits |
計算時間は1.5時間です。
サブミットして得られたスコアは「0.78767」となりました。

順位は想定で3406/7175(top 47%)です。
サンプル丸写しで解いた結果
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
Train samples: 307511, test samples: 48744 Bureau df shape: (305811, 116) Process bureau and bureau_balance - done in 49s Previous applications df shape: (338857, 249) Process previous_applications - done in 69s Pos-cash balance df shape: (337252, 18) Process POS-CASH balance - done in 26s Installments payments df shape: (339587, 26) Process installments payments - done in 53s Credit card balance df shape: (103558, 141) Process credit card balance - done in 42s Starting LightGBM. Train shape: (307507, 798), test shape: (48744, 798) Training until validation scores don't improve for 200 rounds [200] training's auc: 0.796826 training's binary_logloss: 0.234908 valid_1's auc: 0.776264 valid_1's binary_logloss: 0.24672 [400] training's auc: 0.819352 training's binary_logloss: 0.225332 valid_1's auc: 0.787004 valid_1's binary_logloss: 0.242586 [600] training's auc: 0.834096 training's binary_logloss: 0.219313 valid_1's auc: 0.79081 valid_1's binary_logloss: 0.241271 [800] training's auc: 0.846321 training's binary_logloss: 0.214286 valid_1's auc: 0.7928 valid_1's binary_logloss: 0.240638 [1000] training's auc: 0.857056 training's binary_logloss: 0.209805 valid_1's auc: 0.793643 valid_1's binary_logloss: 0.240313 [1200] training's auc: 0.866549 training's binary_logloss: 0.205677 valid_1's auc: 0.793764 valid_1's binary_logloss: 0.240252 [1400] training's auc: 0.875528 training's binary_logloss: 0.201654 valid_1's auc: 0.793798 valid_1's binary_logloss: 0.240266 Early stopping, best iteration is: [1311] training's auc: 0.871708 training's binary_logloss: 0.203388 valid_1's auc: 0.79399 valid_1's binary_logloss: 0.2402 Fold 1 AUC : 0.793990 Training until validation scores don't improve for 200 rounds [200] training's auc: 0.796479 training's binary_logloss: 0.235586 valid_1's auc: 0.777348 valid_1's binary_logloss: 0.241658 ...(省略) [1200] training's auc: 0.866856 training's binary_logloss: 0.206283 valid_1's auc: 0.789235 valid_1's binary_logloss: 0.234109 Early stopping, best iteration is: [1188] training's auc: 0.866209 training's binary_logloss: 0.206562 valid_1's auc: 0.789272 valid_1's binary_logloss: 0.234104 Fold 10 AUC : 0.789272 Full AUC score 0.791417 Run LightGBM with kfold - done in 9066s |
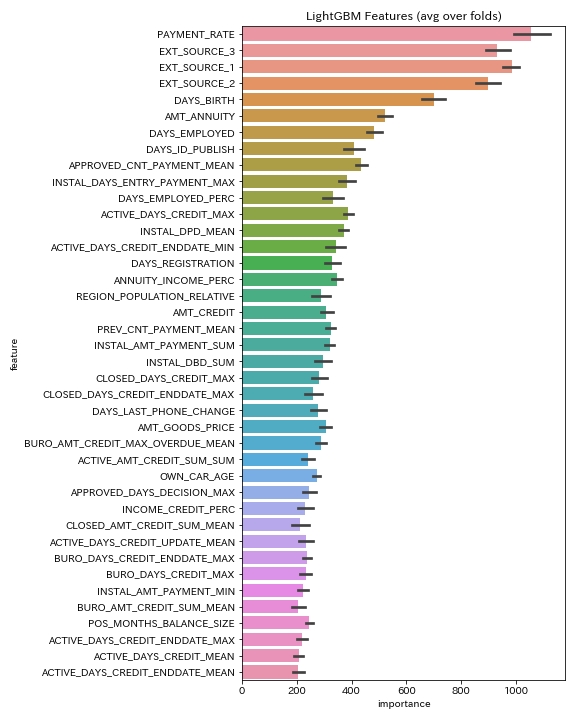
計算時間は2時間です。
サブミットして得られたスコアは「0.79036」となりました。
順位は想定で3059/7175(top 43%)です。
・・・ってあれ???
サンプルと比べて正解率が低いな・・・。
まとめ
「馬鹿の一つ覚え」で「train_test_split」関数や「混合行列(confusion_matrix)」を使っていました。
例えると、サザンアイズの八雲が「土爪(トウチャオ)」だけで戦う・・・という感じです。

もっと、精度が高いアルゴリズムがあるのですね・・・・。目からウロコです。
まだまだ知識は足りませんが、実践の中で少しずつ覚えていきたいです。
で、スコア表です。
| レベル | スコア | ランキング |
|---|---|---|
| 賞金獲得 | 0.80511 | 3/7175 (上位 3名) |
| 金メダル | 0.80110 | 24/7175 (top 0.3%) |
| 銀メダル | 0.79602 | 359/7175 (top 5%) |
| 銅メダル | 0.79449 | 719/7175 (top 10%) |
| サンプル | 0.79070 | 2870/7175 (top 40%) |
| 私(サンプル利用) | 0.79036 | 3059/7175(top 43%) |
| 私(全部利用+前処理+Castboost+AUC+k-分割交差検証) | 0.78767 | 3406/7175(Top 47%) |
| 私(全部利用+前処理+Castboost) | 0.78639 | 3559/7175(Top 50%) |
| 私(全部利用+前処理+LightGBM+ベイズ最適化) | 0.77812 | 4088/7175(Top 57%) |
| 私(application_trainのみ利用+実数+Catboost) | 0.70639 | 6119/7175(Top 85%) |
| 私(application_trainのみ利用+0/1の2値+Keras or PyTorch) | ? | ?/7175(Top ?%) |
| 私(application_trainのみ利用+0/1の2値+Catboost) | 0.53662 | 6812/7175(Top 95%) |
私の技術力でサンプルを超えることって出来るのかな・・・・。
ソースコード
最終的にはサンプルそのままとなってしまいましたので省略します。